Hallo Leute,
ich bräuchte mal euren Rat. Ich habe seit geraumer Zeit Probleme mit meiner HDD. Die HDD braucht sehr lange für verschiedene Aufgaben. Oft hängt dann auch Windows, sodass ich kaum damit arbeiten kann, während ich zum Beispiel eine große Anzahl an Dateien lösche.
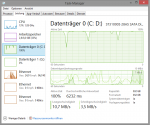
Konkret habe ich letztens ca. 260.000 .jpgs mit knapp 11 GB in den Papierkorb verlegt (Spielerbilder für Football Manager) und im Task-Manager wurde mir eine Zugriffszeit von ca. 3 bis 9 Sekunden angezeigt. Ich weiß jedoch nicht wie aussagekräftig diese Zugriffszeit im Task-Manager ist.
Auch bei großen Installationen als als zB Qt Creator (offlineinstaller) installiert habe, konnte ich teilweise meine Maus nicht bewegen. Bei beiden Beispiele war die Festplattenauslastung jeweils bei 100%.
Die Festplatte hat eine Kapazität von 1TB, wobei stand jetzt nur noch knapp 6 GB frei sind. Die Festplatte hat zwei Partitionen (C: 581 GB / 1 GB frei, Windows; D: 349 GB / 5 GB frei, Daten). Mir ist klar, dass die Zugriffszeit erhöht wird, wenn man eine Festplatte fast voll schreibt. Aber jedoch so langsam?
Windows sagt, dass die Partition C: eine Defragmentierung von 13% habe, nach Defragmentierung habe ich allerdings immer noch 13% Fragmentierung.
Seit neustem werden beim Windows Boot auch keine Programme mehr geladen, die im Autostart sind. Dies habe ich aber noch nicht weiter untersucht. Ich hab jedoch auch den Verdacht, dass dies mit der Festplatte in Verbindung steht. Im Autostart sind sie jedenfalls.
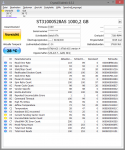
CrystalDiskInfo zeigt mir ein Vorsicht an. Allerdings weiß ich nicht, wie ich die Werte dort interpretieren soll.
Im Anhang sind Bildern von CrystalDiskInfo sowie ein Screenshot von der Zurgiffszeit aus dem Task Manager als ich die 260000 Bilder gelöscht habe und Chrome öffnen wollte (anstelle des Browserfensters von Chrome wurde mir nur ein weißes Bild angezeigt, Chrome brauchte eine Weile bis ich es benutzen konnte).
Systemdaten falls relevant:
CPU: AMD Phenom II x6 1055T OC @ 3,5 Ghz
RAM: 8GB 1332 Mhz
MB: Gigabyte 870a-UD3 rev 2.1
Virenscanner: Avast Free
OS: Windows 8.1 x64
Gruß und danke schonmal.