B100 und X100: Nvidia zieht das Tempo beim KI-Supercomputing an

Nicht mehr alle zwei Jahre, sondern im Jahresrhythmus will Nvidia künftig GPU-Mikroarchitekturen für Beschleuniger im KI-Segment einführen. Das geht aus einer offiziellen Roadmap hervor, die gegenüber Investoren präsentiert wurde. Demnach stehen B100 noch 2024 und X100 ab 2025 als Nachfolger der aktuellen H100 und H200 an.
Der Tesla P100 war Nvidias erster Grafikprozessor fürs Rechenzentrum mit Fokus auf den Bereich KI-Supercomputing. Auf die 2016 vorgestellte Pascal-Mikroarchitektur folgte 2018 Volta mit der V100, dann 2020 Ampere mit der A100 und zuletzt 2022 Hopper mit der aktuell äußerst begehrten H100, die den globalen KI-Boom kaum befriedigen kann.
Doch Nvidia will das Tempo einer offiziellen Roadmap (PDF) zufolge anziehen und zu einem Jahresrhythmus wechseln. In der an Investoren gerichteten Roadmap geht es ausschließlich um Nvidias Data-Center-Sparte und das KI-Supercomputing, nicht um Consumer-Produkte wie die GeForce-Grafikkarten, sodass dort nicht mit einem gleichen Jahresrhythmus zu rechnen ist.
GH200 als erstes Zeichen für höheres Tempo
Dass Nvidia das Tempo anziehen könnte, hatte sich zuletzt schon mit dem Grace Hopper Superchip abgezeichnet. Die Kombination aus Arm-basierter Grace-CPU mit Hopper-GPU hat mit dem H200 zuletzt ein Upgrade auf 141 GB HBM3e mit 5 TB/s pro GPU erhalten und darf sich in diesem Zusammenspiel GH200 Grace Hopper Superchip nennen.
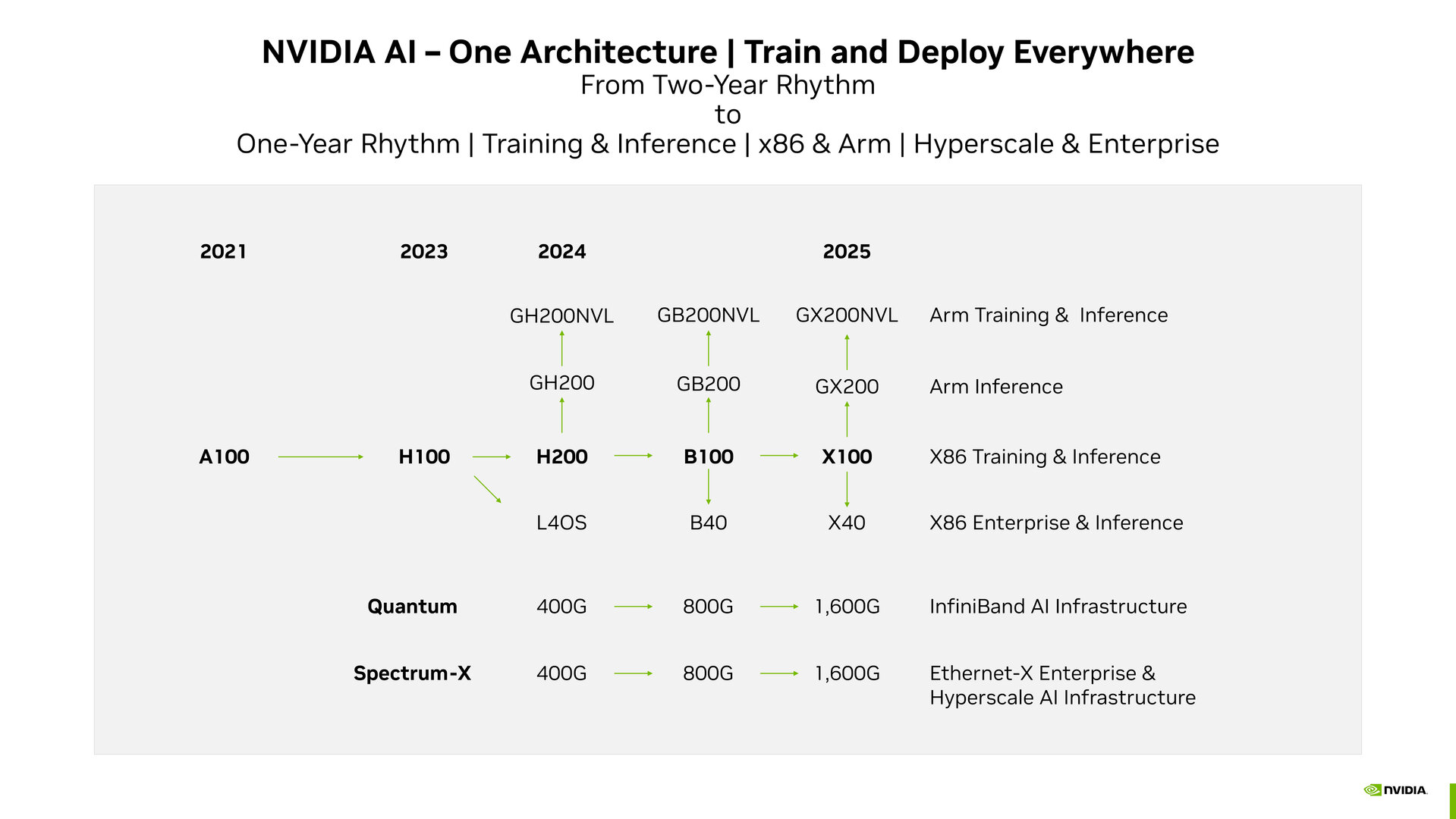
H200 ist die leistungsgesteigerte Ausführung der reinen Hopper-H100-GPU für das KI-Training und Inferencing auf einer X86-Plattform. Für das Inferencing in Kombination mit der eigenen Arm-CPU läuft die Lösung unter dem Namen GH200. Diese Lösungen sollen 2024 auf den Markt kommen. Für Multi-GPU-Systemkonfigurationen im Bereich „Arm Training & Inference“ plant Nvidia laut Roadmap zudem eine Lösung namens GH200NVL. In die Kategorie „X86 Enterprise & Inference“ fällt die im August vorgestellte L40S auf Basis der Ada-Lovelace-Architektur für das Omniverse. Bei den Quantum und Spectrum-X genannten InfiniBand- und Ethernet-Architekturen steht Nvidia derzeit bei 400 Gbit/s.
Blackwell kommt nächstes Jahr
Für kommendes Jahr wird die Vorstellung und potenziell auch schon Markteinführung der Blackwell-Mikroarchitektur erwartet. Im Zentrum steht dabei als Data-Center-Lösung der Grafikprozessor B100, von dem wie bei der vorherigen Mikroarchitektur Ableitungen namens GB200 und GB200NVL geplant sind, also GPUs, die mit Arm-CPU kombiniert werden. Für das Omniverse steht die B40 in der Roadmap. Die Netzwerk-Lösungen sollen kommendes Jahr auf 800 Gbit/s gehen.
1,6 Tbit/s im Netzwerk geplant
Auf diese Lösungen soll 2025 der namentlich noch mit einem Platzhalter versehene Grafikprozessor X100 mit den Abwandlungen GX200 und GX200NVL nach oben sowie X40 nach unten folgen – der Name der Mikroarchitektur steht noch aus. Im Netzwerk will Nvidia übernächstes Jahr die Bandbreite auf 1,6 Tbit/s und somit abermals verdoppeln.
- Bester Maus- und Tastatur-Hersteller
- Bester PC-Gehäuse-Hersteller
- Bester NAS-Hersteller
- Alle Wahlen im Überblick...