GF100 „Fermi“: Nvidias nächste Grafik-Architektur im Detail erklärt
3/6GF100 im Detail
Graphics Processing Clusters (GPCs)
Einer der größten Unterschiede zwischen dem „alten“ GT200 (und G80) und dem neuen GF100-Chip ist die Aufteilung der internen Komponenten, die Nvidia deutlich überarbeitet hat, um so nach eigenen Aussagen die Effizienz spürbar steigern zu können. Die meisten Ausführungseinheiten hat Nvidia in so genannten „Graphics Processing Clusters“ (GPCs) untergebracht, die jeweils gewisse Komponenten wie zum Beispiel die Streaming-Multiprocessors (SM) und die TMUs enthalten. Um die GF100-Architektur skalieren zu können, kann Nvidia sowohl die GPCs als auch die SMs und die Speichercontroller abschalten beziehungsweise gar nicht erst verbauen.
Den Anfang in der Renderingpipeline macht das Host-Interface, das die Befehle von der CPU abfängt. Anschließend kopiert die „GigaThread Engine“ die notwendigen Daten aus dem Systemspeicher in den eigene Framebuffer. Daraufhin teilt die GigaThread Engine die zu berechnenden Daten in „Thread“-Blöcke, die dann an die Streaming-Multiprocessors weitergeleitet werden. Diese wiederum teilen die Blöcke in Warps (32 Threads), bevor diese an die CUDA-Cores (sprich die ALUs) verteilt werden.
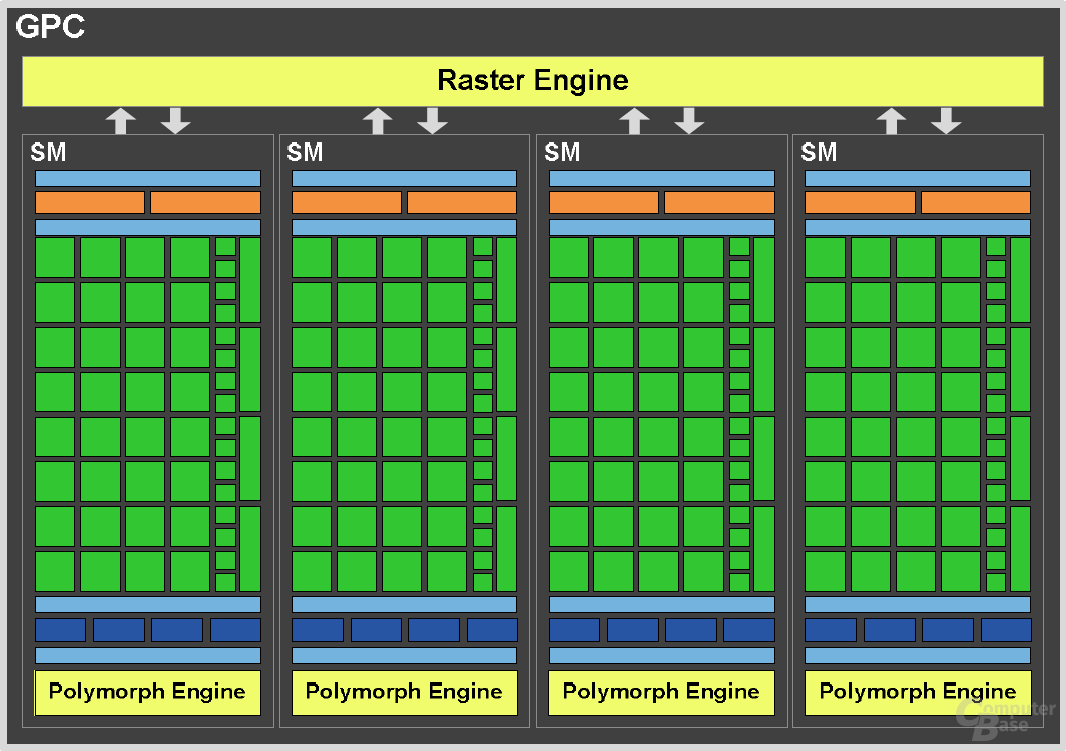
Die Vollausstattung des GF100 besteht aus vier GPCs, die wiederum jeweils aus vier Streaming-Multiprocessors zusammengesetzt sind. Jeder SM kann auf 32 einzelne ALUs zurückgreifen, womit es insgesamt 512 einzelne Shadereinheiten gibt. Die ALUs vom GF100 sind, wie schon beim GT200, skalare Einheiten. Das heißt, dass jede ALU pro Rechentakt eine einzelne Komponente (Rot, Grün, Blau oder Alphawert) berechnen kann. Jeder einzelne SM kann auf dem GF100 pro Taktzyklus nun mit unterschiedlichen Komponenten versorgt werden, je nachdem, welche gerade am dringendsten benötigt wird. Jeder SM kann zu jeder Zeit mit 48 Warps umgehen.
Laut Nvidia bietet der GF100 insbesondere zwei wichtige Neuerungen, durch die die Effizienz stark verbessert werden soll. So gibt es in der überarbeiteten Architektur für jeden GPC eine eigene Raster-Engine für das Triangle-Setup (wichtig bei Geometrieberechnungen), die Rasterization an sich sowie Z-Cull (Sichtbarkeitsprüfungen). Darüber hinaus verfügt jeder GPC über eine so genannte PolyMorph-Engine, die sich primär um die Geometriearbeit kümmert und unter anderem den Tessellator beinhaltet.
PolyMorph Engine
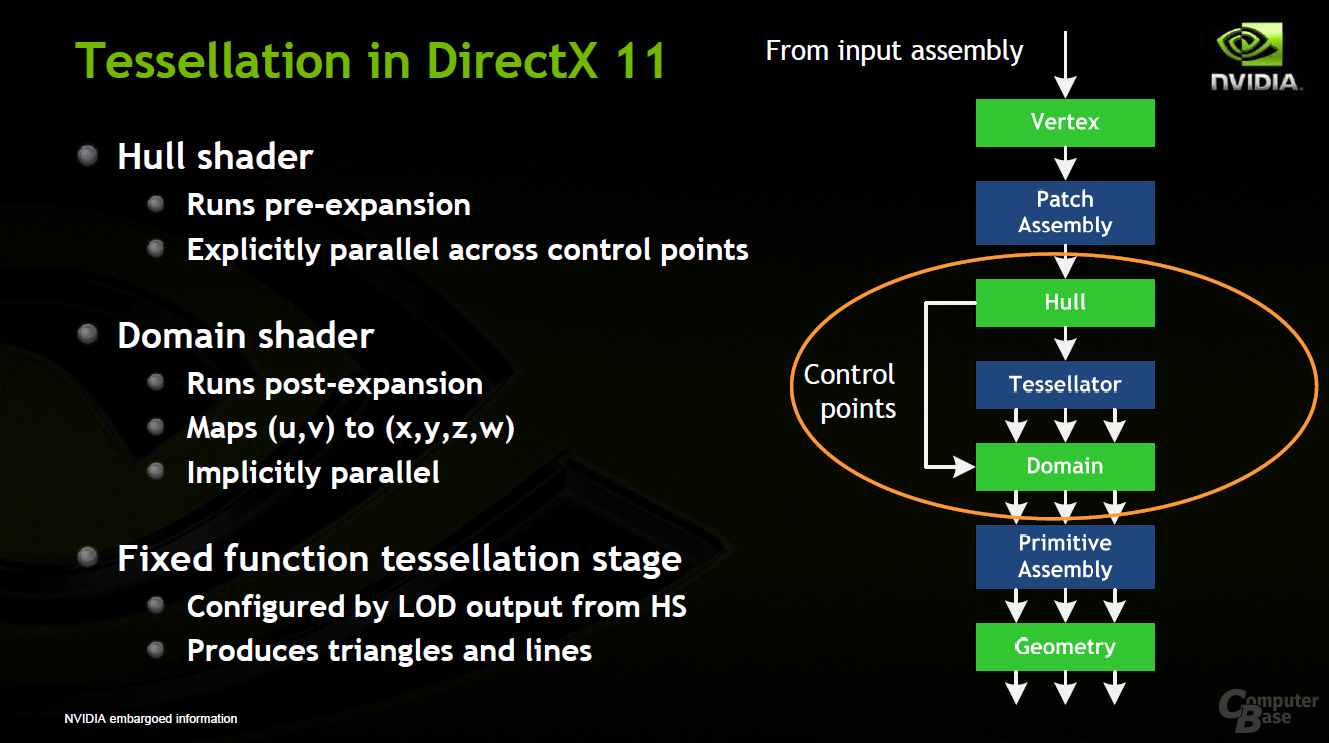
Bei den vorherigen Nvidia-Architekturen sowie bei der Radeon-HD-5000-Serie gibt es vor den Shader-Clustern (oder wie man sie nennen möchte) eine fixe Einheit, die sich um diverse Aufgaben wie die eigentlichen Raster-Arbeit kümmert und deren Ergebnisse dann anschließend auf die Shader-Cluster weiter verteilt werden. Laut Nvidia war dies bis jetzt kein großes Problem. Mit DirectX 11, dem Tessellator und somit zahlreichen weiteren Dreiecken soll es bei dieser Konstellation aber zu einem Flaschenhals kommen können, da der Workload anders anfallen kann als bisher.
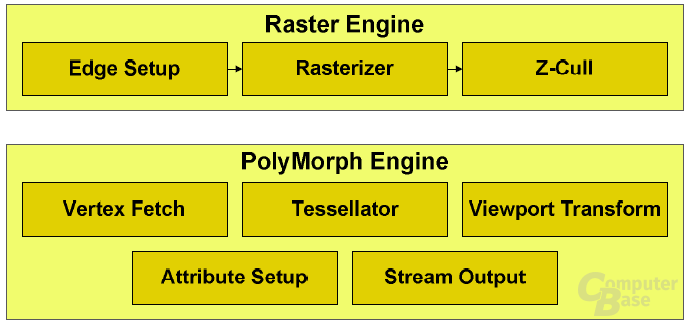
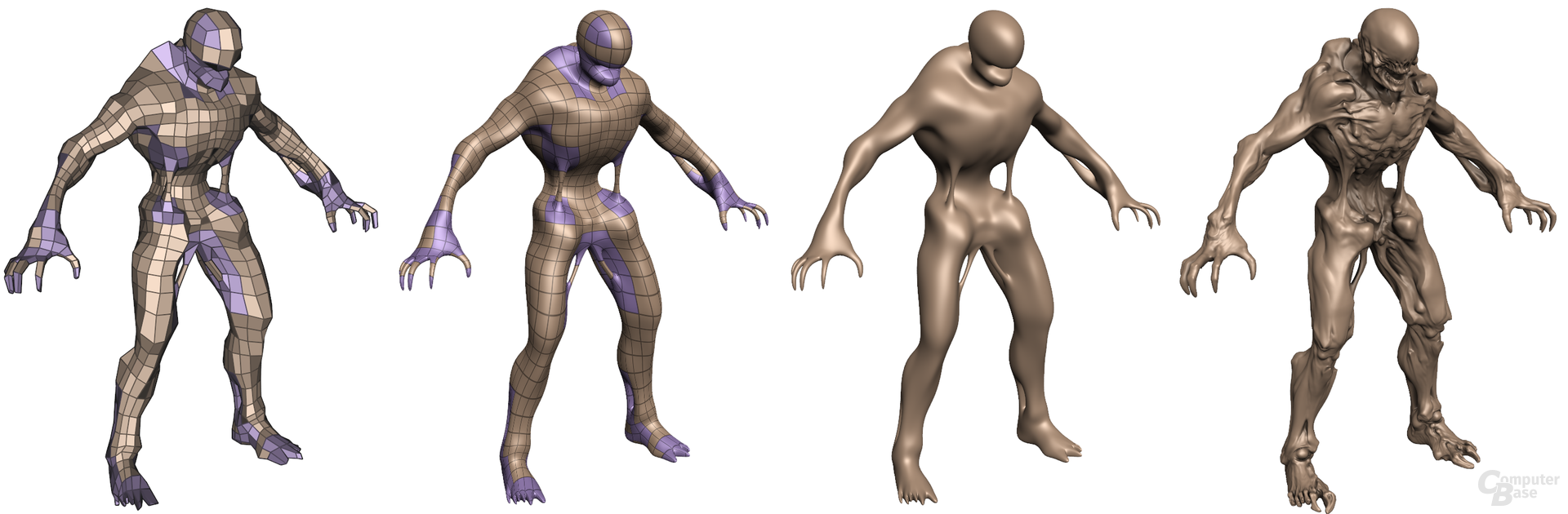
Um den Workload besser bewältigen zu können und damit die Auslastung aller Einheiten zu gewährleisten, verfügt jeder Streaming-Multiprocessor auf dem GF100 über eine „PolyMorph Engine“ – es gibt also 16 Einheiten davon. Jede PolyMorph Engine kann einen Vertex Fetch ausführen und sich die Vertices (Ecken eines Polygons) aus einem globalen Vertex Buffer holen. Die Vertices werden dann zum Vertex Shading und zum Hull Shading geschickt, um dann den Tessellator nutzen zu können.


Zudem beherrscht jede PolyMorph Engine „Viewpoint Transform“ und „Attribute Setup“. Beide Funktionen sind für den Vorgang der Tessellation notwendig, da zum Beispiel Koordinaten geändert und die Effizienz gesteigert werden muss. Eine Stream-Output-Funktion kann die bearbeiteten Daten dann, wenn notwendig, in den Framebuffer der GPU schreiben, falls diese noch weiter verändert werden müssen. Ist der Vorgang abgeschlossen, werden die entstandenen Primitive (zum Beispiel Punkte oder Linien) zur Raster Engine geschickt.



Raster Engine
Bei den bisherigen GPU-Designs ist darüber hinaus auch die gesamte Raster-Engine vor sämtlichen Shader-Clustern platziert, was sich mit dem GF100 ebenfalls ändert. Dort hat jeder GPC eine eigene Raster Engine, um so einen weiteren Flaschenhals zu verhindern. Es gibt also gleich vier separate Raster-Blöcke. Jeder einzelne besteht aus dem „Edge Setup“, das die Koordinaten einzelner Vertex-Daten erfasst und eine vergleichbare Position in einem Dreieck berechnet. Falls das erstellte Dreieck außerhalb des Sichtbereichs liegt, wird es direkt verworfen.
Jedes Edge Setup kann pro Takt einen Punkt, eine Linie oder ein Dreieck berechnen. Der in der Raster Engine enthaltene Rasterizer (von denen es im GF100 also gleich vier Stück gibt, im Vergleich zu zwei wohl etwas weniger komplexen Ausführungen auf dem RV870) berechnet dann die Pixelbedeckung. Jeder Rasterizer kann pro Takt acht Pixel fertigstellen, also 32 Pixel im gesamten GF100.


Die erstellten Pixel durchlaufen schlussendlich den Z-Cull-Mechanismus, der die Tiefe der Pixel mit den bereits vorhandenen Pixeln im Framebuffer vergleicht. Falls die neuen Pixel komplett verdeckt werden, löscht Z-Cull diese sofort, um so unnötigen Rechenaufwand zu minimieren.
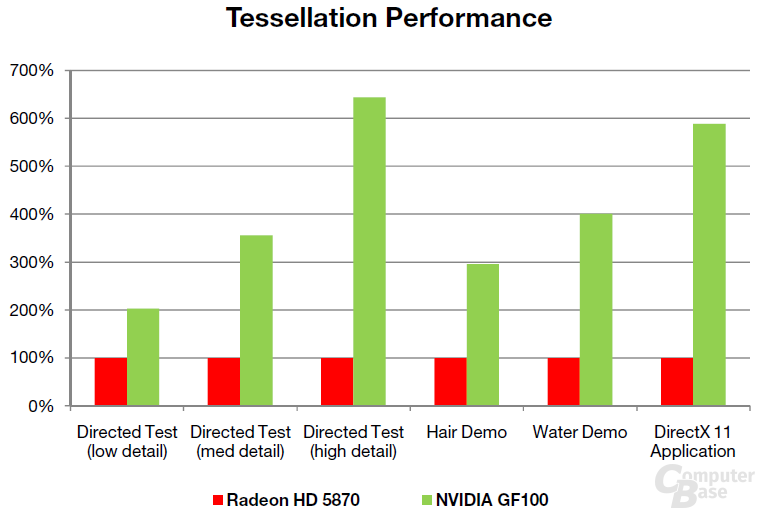
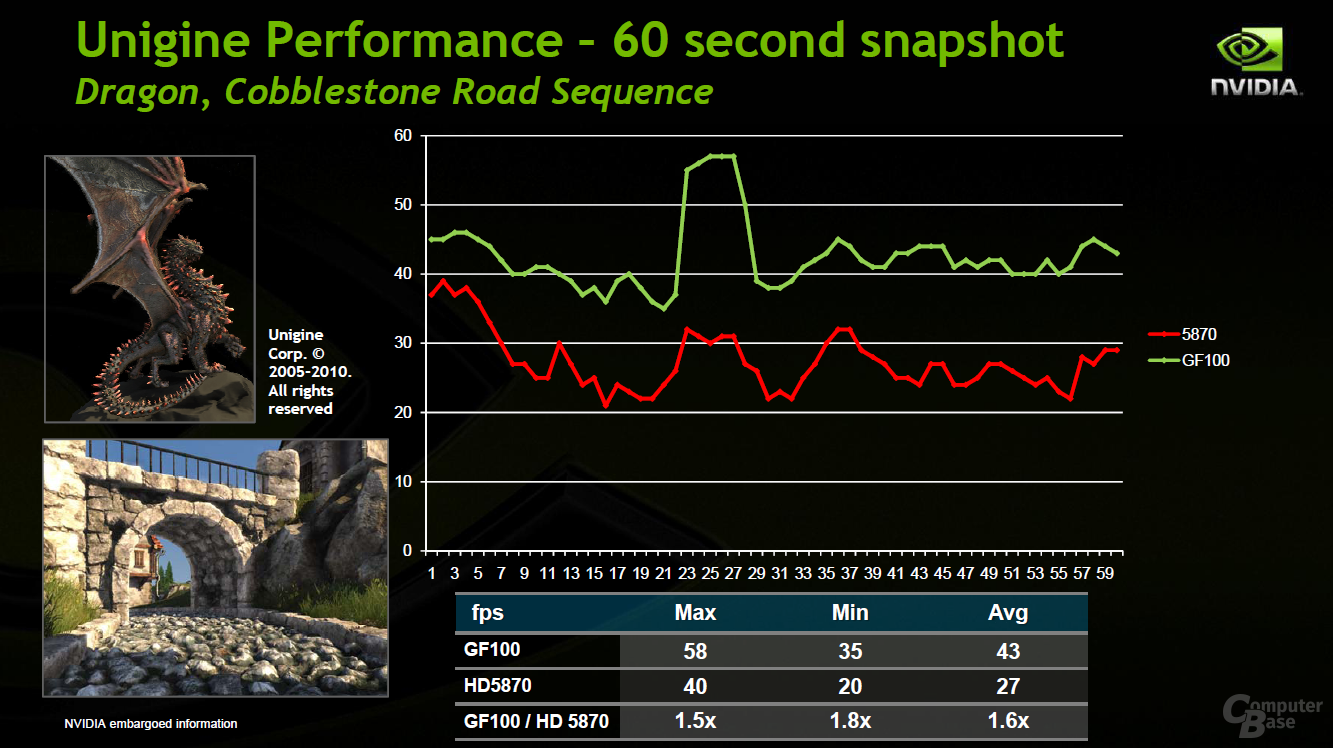
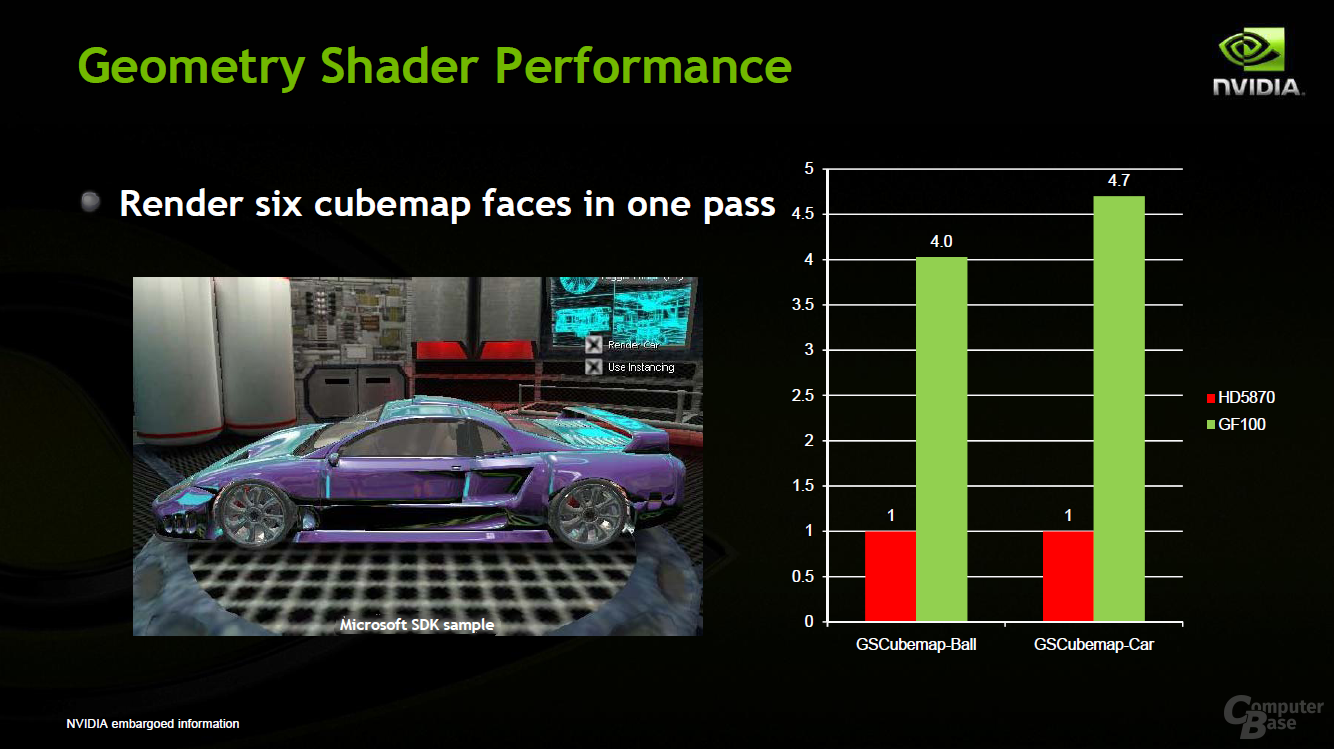
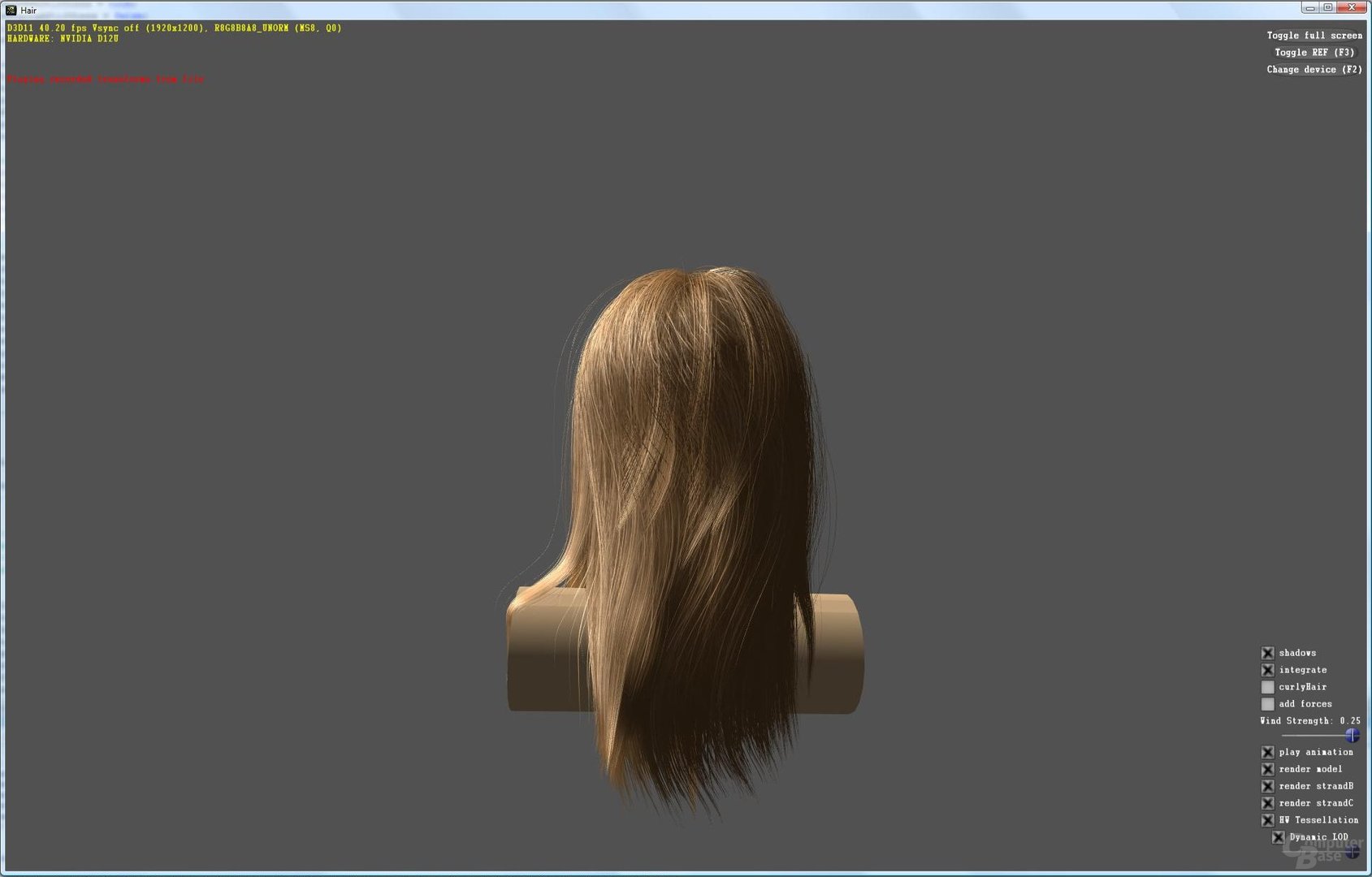
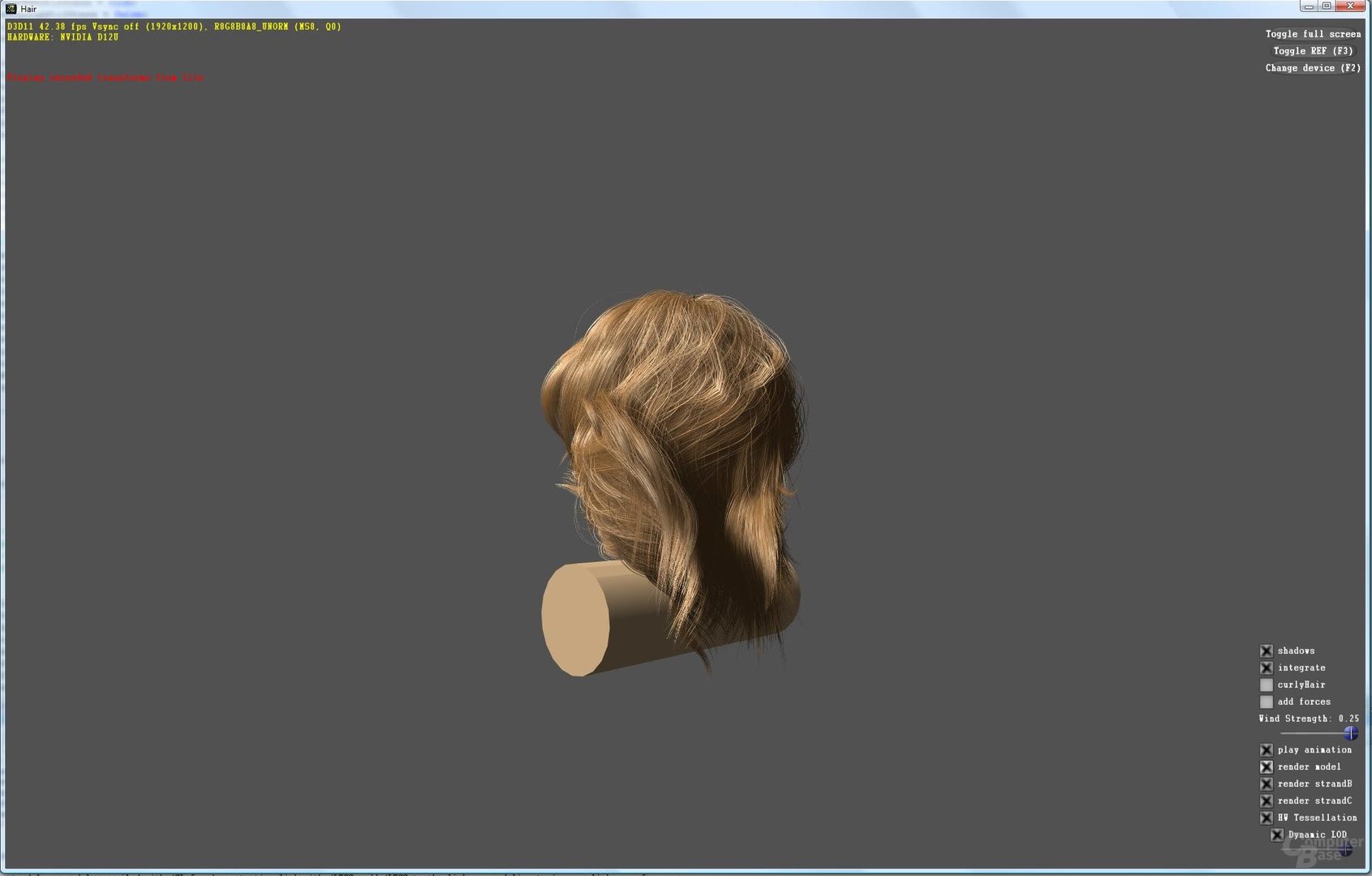
Nvidia hat also sehr viel Wert auf die Geometrieleistung beim GF100 gelegt. Nach eigenen Angaben konnte die Geschwindigkeit um den Faktor acht im Vergleich zum GT200 erhöht werden. Die Kalifornier zeigen, um dies zu untermauern, einige selbst erstellte Benchmarks gegen eine Radeon HD 5870. Diese zeigen die Performance der Tessellation auf dem GF100, die je nach Applikation doppelt bis mehr als sechs Mal so schnell wie auf dem RV870 ist. Da die Ergebnisse von Nvidia stammen (und zudem nur eine spezielle Berechnung zeigen), sind sie wie gewohnt mit Vorsicht zu genießen.