Ich weiß nicht so recht, ob das hier reinpasst oder doch eher ins Programmierforum gehört. Aber da ich eher mit Linux auf Kriegsfuß stehe, denke ich passt es ganz gut hier mit rein. Es geht um folgendes:
Für die Uni hab ich ein kleines Benchmark programmiert, das ne schnelle Fourier Transformation ausführt. Geschrieben hab ichs in C++ mit Inline Assembler. Es gibt 2 Varianten:
1) Single-Thread Lösung (simple iterative Schleife)
2) Dual-Thread Lösung (Datenfluss aufgebrochen, eine Barriere, die einmal durchlaufen wird, zur Threadsynchronisation)
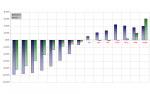
Das Proggie läuft unter Windows und Linux. Jetzt kommt das eigentlich faszinierende, was mir Kopfschmerzen macht. Auf Dualcore Prozessoren liefert die Dual-Thread Lösung unter Linux keine besseren Ergebnisse als die Single-Thread Lösung. Um hier was zu messen, müssen die Transformationen schon verdammt lang werden und da werden die Messwerte wieder durch andere Faktoren beeinträchtigt.
Unter Windows hingegen zeigen sich mit der Dual-Thread Lösung Leistungssteigerungen schon bei relativ kleinen Transformationen mit nur wenigen KB Testdaten Performancesteigerungen um bis zu 40%. Das Leistungsdelte wird bei größeren Datenmengen geringer, was aber wohl daran liegt, dass ich die Prozessorkerne gegenseitig ums Speicherinterface kloppen. So gesehen nicht verwunderlich.
Aber woher kommts nun, dass ich unter Windows Leistungsverbesserungen habe und unter Linux eher noch Verschlechterungen? Die Codes sind praktisch identisch. Klar, unter Linux is die pthread gefragt, unter Windows die AFX. Aber der Code an sich is identisch und ob ich jetzt unter Windows oder unter Linux ne Barriere mit Semaphoren und Mutexes programmiere sollte ja egal sein - noch dazu ist es nur eine Barriere pro Transformation.
Es kann ja eigentlich fast nur noch am Scheduling der Betriebssysteme liegen...
Kennt jemand von Euch ähnliche Probleme oder weiß jemand ne gute Seite, wo die Scheduler von Windows und Linux verglichen werden? So kann ich den Code ja nicht an die Öffentlichkeit lassen...
/Edit: Ja, der Kernel is SMP fähig!
Für die Uni hab ich ein kleines Benchmark programmiert, das ne schnelle Fourier Transformation ausführt. Geschrieben hab ichs in C++ mit Inline Assembler. Es gibt 2 Varianten:
1) Single-Thread Lösung (simple iterative Schleife)
2) Dual-Thread Lösung (Datenfluss aufgebrochen, eine Barriere, die einmal durchlaufen wird, zur Threadsynchronisation)
Das Proggie läuft unter Windows und Linux. Jetzt kommt das eigentlich faszinierende, was mir Kopfschmerzen macht. Auf Dualcore Prozessoren liefert die Dual-Thread Lösung unter Linux keine besseren Ergebnisse als die Single-Thread Lösung. Um hier was zu messen, müssen die Transformationen schon verdammt lang werden und da werden die Messwerte wieder durch andere Faktoren beeinträchtigt.
Unter Windows hingegen zeigen sich mit der Dual-Thread Lösung Leistungssteigerungen schon bei relativ kleinen Transformationen mit nur wenigen KB Testdaten Performancesteigerungen um bis zu 40%. Das Leistungsdelte wird bei größeren Datenmengen geringer, was aber wohl daran liegt, dass ich die Prozessorkerne gegenseitig ums Speicherinterface kloppen. So gesehen nicht verwunderlich.
Aber woher kommts nun, dass ich unter Windows Leistungsverbesserungen habe und unter Linux eher noch Verschlechterungen? Die Codes sind praktisch identisch. Klar, unter Linux is die pthread gefragt, unter Windows die AFX. Aber der Code an sich is identisch und ob ich jetzt unter Windows oder unter Linux ne Barriere mit Semaphoren und Mutexes programmiere sollte ja egal sein - noch dazu ist es nur eine Barriere pro Transformation.
Es kann ja eigentlich fast nur noch am Scheduling der Betriebssysteme liegen...
Kennt jemand von Euch ähnliche Probleme oder weiß jemand ne gute Seite, wo die Scheduler von Windows und Linux verglichen werden? So kann ich den Code ja nicht an die Öffentlichkeit lassen...
/Edit: Ja, der Kernel is SMP fähig!
Zuletzt bearbeitet: