Claude 3: Das erste Large Language Model, das GPT-4 schlägt – oder?

Anthropic hat mit Claude 3 eine neue AI-Modellreihe vorgestellt, die laut Angaben des Unternehmens einen neuen Industriestandard setzt. Das Spitzenmodell Claude 3 Opus soll sogar OpenAIs GPT-4-Modell überflügeln. Experten zweifeln aber an der Aussagekraft der Benchmarks.
Claude 3 Opus, Sonnet und Haiku
Neben Opus umfasst die Claude-3-Reihe noch die Modelle Sonnet und Haiku. Diese unterscheiden sich in der Größe und Leistungsfähigkeit, Haiku ist das kleinste – und laut Anthropic effizienteste – Modell, Sonnet ist die Mittelklasse. Das Kontext-Fenster, das die maximale Größe der Prompt-Eingaben beschreibt, umfasst bei allen drei Modellen 200.000 Token.
Während bei Opus der Input von 1 Million Token 15 US-Dollar und der Output von 1 Million Token 75 US-Dollar kostet, sind es bei Haiku für dieselbe Anzahl an Token 0,25 US-Dollar und 1,25 US-Dollar. Sonnet liegt bei 3 US-Dollar beim Input von 1 Million Token und bei 15 US-Dollar beim Output von 1 Million Token.
Claude 3 ist zudem Anthropics erste multimodale Modellreihe, diese können also sowohl Text als auch Bilder verarbeiten. Somit bewegt sich das Unternehmen nun auf Augenhöhe mit der Konkurrenz und geht sogar in manchen Bereichen darüber hinaus. So lassen sich etwa bei einer Prompt-Eingabe bis zu 20 Bilder verarbeiten.
Neues Spitzenmodell
Was bei der Präsentation aber hervorsticht, ist die Performance bei typischen Aufgaben aus Bereichen wie logischem Denken, Expertenwissen, Mathematik und Sprachfähigkeit. Laut den von Anthropic bereitgestellten Benchmarks, die typische Tests wie MMLU oder MATH umfassen, schneidet Claude 3 Opus besser ab als GPT-4. „Anthropic schlägt OpenAI“ war daher auch eine der Schlagzeilen, die auf X und in KI-Newslettern kursierte.
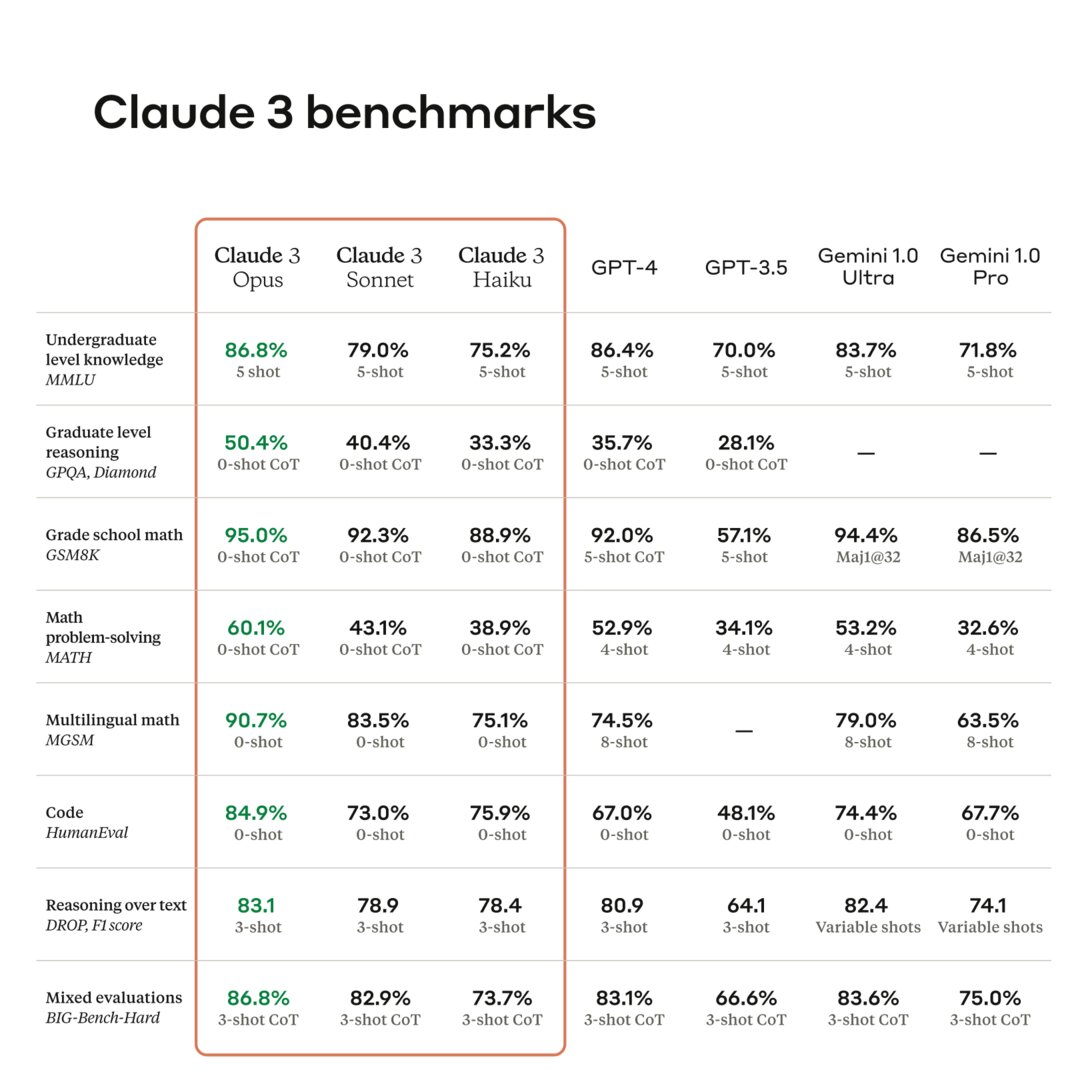
Ganz so einfach ist aber nicht. Der naheliegendste Punkt: Für den Vergleich nutzte Anthropic die Standard-Version von GPT-4 und nicht das aktuelle GPT-4 Turbo, das etwas besser abschneidet.
Entscheidender ist jedoch die generelle Zuverlässigkeit bzw. Unzuverlässigkeit der KI-Benchmarks. Laut einer Analyse von Ars Technica wären diese „notorisch anfällig für Rosinenpickerei“. Unter Experten würde daher noch kein Konsens bestehen, ob Claude 3 Opus nun tatsächlich das leistungsfähigste Modell am Markt ist.
Hinzu kommt die Diskrepanz zwischen theoretischer und praktischer Leistung. „Wie gut ein Modell in Benchmarks abschneidet, sagt nicht viel darüber aus, wie es sich ‚anfühlt‘“, so der KI-Forscher Simon Willison im Gespräch mit Ars Technica. Nichtsdestoweniger wären die präsentierten Ergebnisse bemerkenswert, erstmals schneide ein Modell bei so vielen Benchmarks besser ab als GPT-4.
Für den Markt heißt das im Endeffekt: Neben GPT-4 gibt es mit Gemini Advanced von Google sowie den aktuellen Modellen von Mistral und Anthropic nun mehrere Anbieter, die sich bei der Benchmark-Performance auf Augenhöhe bewegen. Für die Praxis relevant ist aber, wie die Modelle in Anwendungen integriert werden – und wie Fehleranfällig diese sind. Halluzinieren ist in diesem Bereich das Stichwort.
Verfügbarkeit über den Claude-Chatbot
Claude 3 Opus und Sonnet sind über die Claude API und den AI-Chatbot Claude.AI zugänglich, Haiku folgt später. Die kostenlose Variante des Chatbots nutzt Sonnet, während Abonnenten von Claude Pro (20 US-Dollar pro Monat) das Opus-Modell verwenden können. Man verfolgt mit der kostenpflichtigen Variante für das leistungsfähigste Modell also eine ähnliche Strategie wie OpenAI bei ChatGPT, Microsoft bei Copilot und Google bei Gemini.
Ebenfalls abrufen lassen sich die Modelle über Amazon Bedrock und in einer privaten Vorschau über Googles Cloud-Dienst Vertex AI. Amazon und Google zählen zu den Investoren von Anthropic, beide haben Milliarden-Summen in das Unternehmen gesteckt.
Arbeit an Risiken
Anthropic, das von ehemaligen OpenAI-Mitarbeitern gegründet wurde, betont die Rolle der Sicherheit. Mehrere Teams arbeiten daran, Risiken laufend zu identifizieren und zu entschärfen. Zu diesen Risiken zählen etwa Falschinformationen, der Missbrauch biologischer Technologien, die Darstellungen von Kindesmissbrauch und Wahlmanipulationen.
Antworten der Modelle können verzerrend ausfallen, wie zuletzt das Beispiel Gemini verdeutlichte. Googles neuer AI-Chatbot stellte historische Darstellungen kurios bis grob irreführend da. Anthropic verkündet nun, man habe in diesem Bereich Fortschritte gemacht. Claude 3 soll weniger voreingenommen sein als ältere Claude-Modelle. Die Fehleranfälligkeit ist einer der Aspekte, an dem man weiter arbeitet.
- Bester Grafikkarten-Hersteller
- Bester Monitor-Hersteller
- Bester CPU-Hersteller