Nvidia cuLitho: GPU-beschleunigte Lithografie geht in die Serienproduktion

TSMC und Synopsys bringen die von Nvidia entwickelte, GPU-beschleunigte Lithografie in die Serienproduktion. Nvidia cuLitho ist eine Software-Bibliothek, die von vielen GPUs beschleunigt wird und im Bereich der Computational Lithography die Zeit für die Berechnung von Belichtungsmasken moderner Nodes deutlich reduzieren soll.
Der weltgrößte Auftragsfertiger TSMC und der Halbleiter-Design-Software-Anbieter Synopsys waren vor einem Jahr zur GTC die ersten Unternehmen, die starkes Interesse an Nvidia cuLitho bekundet hatten und die Software-Bibliothek einsetzen wollten. Bei TSMC stand man kurz vor der Qualifikationsphase für den Einsatz in der Produktion, und Synopsys prognostizierte massive Fortschritte für die Optical Proximity Correction (OPC) mit einer Verkürzung des Prozesses von mehreren Wochen auf wenige Tage.
TSMC und Synopsys setzen cuLitho ein
Jetzt haben beide Unternehmen passend zur diesjährigen GTC den Einsatz von cuLitho in der Serienproduktion angekündigt. Die Software-Bibliothek komme im Produktionsprozess von TSMC und in der Design-Software von Synopsys zum Einsatz, heißt es, doch für welche Fertigungsstufen genau, geht aus der Ankündigung nicht hervor. TSMC erklärt jedoch, dass man bei kurvigen Mustern auf den Belichtungsmasken eine 45-fache und bei geradlinigen Mustern eine 60-fache Beschleunigung für die Berechnung der Muster erzielen konnte.
Blackwell kann cuLitho beschleunigen
Nvidia fügt hinzu, dass cuLitho künftig auch von den neuen GPUs auf Basis der Blackwell-Architektur beschleunigt werden könne. Darüber hinaus liefere ein neuer Generative-AI-Workflow über den GPU-beschleunigten Prozess hinaus eine Geschwindigkeitssteigerung um den Faktor 2x. Generative AI erstelle annähernd perfekte inverse Belichtungsmasken für die Korrektur der Diffraktion. Die finale Maske werde davon abgeleitet unter Verwendung traditioneller Methoden weiter angepasst, sodass sich für die OPC unterm Strich eine Halbierung des zeitlichen Aufwands ergebe.
Diese Probleme geht Nvidia cuLitho an
Nvidia cuLitho geht dabei ein Problem an, das vor allem bei modernen Fertigungsprozessen besteht und viel Zeit in der Lithografie respektive der Computational Lithography verschlingt. Zum Hintergrund: Lithografie ist der Prozess, bei dem ein am Computer erstelltes Chip-Design über eine Belichtungsmaske physisch auf einen Siliziumwafer übertragen wird. Ein Chip-Design kann dabei aus bis zu rund Hundert Ebenen und Billionen Polygonen oder Mustern bestehen, die auf den Wafer übertragen werden müssen, um dort die Transistoren und Verdrahtungen des Chips zu erzeugen. Zum Einsatz kommen aufgrund stetig aufwendigerer Designs auch immer komplexere Belichtungsmasken, die immer dichtere Muster in den Fotolack des Wafers ätzen müssen, um die dreidimensionale Struktur des geplanten Chip-Designs zu erhalten.
Computational Lithography ist in diesem Zusammenhang nicht neu, sondern kommt zwangsweise als Resultat der stetig kleineren Nodes zum Einsatz, deren Strukturen vor etwa 30 Jahren anfingen, kleiner als die Wellenlänge der genutzten Lichtquelle auszufallen. Anfang der 1990er Jahre waren Strahlungsquellen mit einer Wellenlänge von 240 bis 255 nm neu, nach den Quecksilberdampflampen kamen später KrF-Excimerlaser mit einer Wellenlänge von 248 nm zum Einsatz, die für die DUV-Lithografie genutzt wurden. Der Abstand zwischen der Wellenlänge der Lichtquelle und der Größe von Transistoren wurde seitdem stetig größer, erst mit der EUV-Lithografie kamen sich beide Entwicklungen wieder näher, gehen seitdem aber wieder weiter auseinander.
OPC und ILT helfen bei Belichtung
Das wiederum führt bei der Belichtung zum physikalischen Effekt der Diffraktion, also der Ablenkung von Lichtwellen an einem Hindernis – in diesem Fall der Belichtungsmaske. Das Ergebnis aus diesem Effekt wäre ohne Korrektur eine verschwommene Belichtung auf dem Wafer, käme nicht die heutzutage übliche Computational Lithography zum Einsatz. Die Herangehensweise erfolgt dafür mittlerweile in der entgegengesetzten Richtung, indem man für die auf dem Wafer gewünschte Belichtung berechnet, wie die Belichtungsmaske unter Berücksichtigung der Limitierungen bei der Wellenlänge der Lichtquelle designt werden muss, um dennoch das gewünschte Chip-Design mit einer scharfen Abtrennung der einzelnen Transistoren und Verdrahtungen zu erhalten.
Konnte man vor 30 Jahren vereinfacht ausgedrückt noch nach dem „What you see is what you get“-Prinzip arbeiten, als das Muster noch eins zu eins, so wie es auf der Belichtungsmaske zu sehen war, auf den Wafer übertragen werden konnte, musste man sich später bei kleineren Nodes Tricks wie vermeintlichen Verfälschungen auf der Maske bedienen, um unter Berücksichtigung der Diffraktion dennoch das korrekte Ergebnis zu erhalten. Zu diesen Anpassungen zählt zum Beispiel die Optical Proximity Correction (OPC), die zusätzliche Strukturen auf der Belichtungsmaske aufbringt, um nicht erwünschte Effekte wie Linienendenverkürzung, Kantenverrundungen oder die Verbreiterung benachbarter Linien zu kompensieren. Bei der heutigen EUV-Lithografie kommt die Inverse Lithography Technology (ILT) zum Einsatz, bei der hochkomplexe, kurvenförmige Muster aufseiten der Quelle (Maske) berechnet werden, um auf dem Wafer eine exakte Annäherung zwischen Maske und Ziel (Wafer) zu erhalten.
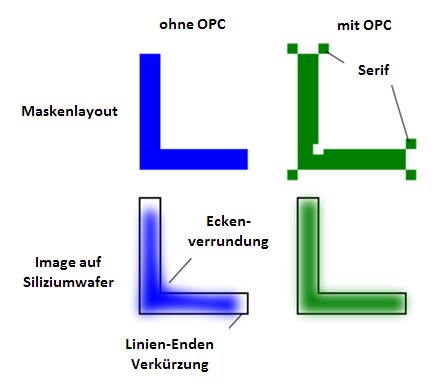
Diese Berechnungen für OPC und ILT sind das, was man unter Computational Lithography versteht und was immer leistungsfähigere Rechenzentren bei Ausrüstern und Fertigern voraussetzt, um entsprechende Belichtungsmasken erzeugen zu können. Genau hier kommt die von Nvidia entwickelte Software-Bibliothek cuLitho zum Einsatz, deren Algorithmen mittels GPU beschleunigt werden, um den Vorgang massiv zu beschleunigen und mit einem geringeren Energiebedarf bei gleichzeitig weniger benötigter Fläche durch kleinere Server im Rechenzentrum durchzuführen.
350 DGX H100 statt 40.000 CPUs
Nvidia gibt zur Ankündigung gleichlautend wie zur GTC vor einem Jahr an, dass das Mask Processing der Belichtungsmasken bei heutigen Nodes mit einer Berechnungszeit von rund zwei Wochen unter Verwendung von 40.000 CPUs einhergehe. Was sich zur diesjährigen GTC allerdings verändert hat, ist die Angabe, dass mit cuLitho auf jetzt nur noch 350 statt vor einem Jahr 500 DGX H100 diese Berechnungen deutlich beschleunigt durchgeführt werden können – von der ehemaligen Angabe „über Nacht“ ist aber keine Rede mehr. Zum Einsatz würden somit „nur noch“ 2.800 statt 4.000 Hopper-Beschleuniger kommen. Zur GTC 2023 hatte Nvidia erklärt, dass die Lösung mit 500 DGX H100 nur 1/8 der Stellfläche im Rechenzentrum und 1/9 der Energie im Vergleich zu den reinen CPU-Servern mit 40.000 Prozessoren belege. Durch den Einsatz von cuLitho könne man zudem 200.000 Tonnen CO2 pro Jahr einsparen.
Für anstehende Nodes wie die 2-nm-Fertigung und noch kleinere Verfahren könne die bisherige Computational Lithography ausschließlich mit CPUs potenziell nicht mehr praktikabel sein, sagt Nvidia, weil man von einem um den Faktor 10x gesteigerten Berechnungsaufwand für künftige Belichtungsmasken ausgehe. cuLitho sei deshalb überhaupt erst der Ermöglicher für die in Zukunft erwarteten Fertigungsprozesse.
ComputerBase hat Informationen zu diesem Artikel von Nvidia im Vorfeld und im Rahmen einer Veranstaltung des Herstellers in San Jose unter NDA erhalten. Die Kosten für Anreise, Abreise und vier Hotelübernachtungen wurden von dem Unternehmen getragen. Eine Einflussnahme des Herstellers auf die oder eine Verpflichtung zur Berichterstattung bestand nicht. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.
- CB-Funk-Podcast #63: Zu Besuch bei Nvidia im Silicon Valley
- Samsung und SK Hynix: GDDR7 mit nur 1,1 Volt oder bis zu 40 Gbit/s
- SK Hynix PCB01 alias P51: Endlich kommt eine Alternative zum Phison E26
- +8 weitere News