Hallo,
mein Linux Server (Openmediavault) hat eine sehr hohe Load. Vor allem, seit ich den Rechner vor einigen Tagen neu gestartet habe.
Anbei einige Screenshots dazu

Den Neustart sieht man am 2. Mai an der Unterbrechung.
Die CPU Auslastung ist nicht besonders hoch - und sinkt sogar nach dem Neustart, während die Load einen gegenläufigen Trend hat:

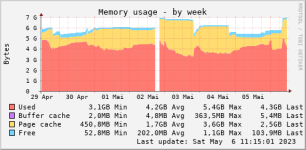
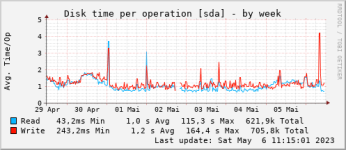
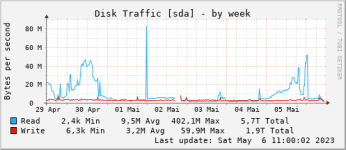
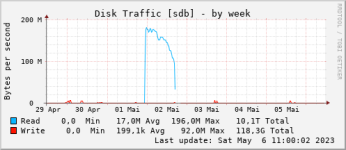
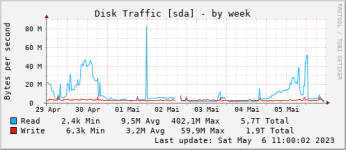
Bei Festplatte und Co sehe ich nix auffälliges.
Prozessor ist ein Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz und es laufen einige Docker Container und eine Home-Assistant VM.
Ich habe schon viel gesucht und diesen Einzeiler gefunden, der wartende Prozesse anzeigt
Das gibt aber einen leeren Output.
Top liefert mir dies:
Hier sehen wir schon, das qemu viel benötig - aber nicht sooo viel. Das sind 32% von einem Kern (von 4).
Bei einem Load von 4 (den ich aktuell habe) müssten aber ja alle Kerne zu 100% ausgelastet sein -wenn es denn an der CPU liegt.
Warum die VM 32% CPU braucht können wir nochmal in einem eigenen Thread ergründen (es sei denn, jemand meint, dies sei die Ursache). Denn wenn ich mich in der VM einlogge, ist die CPU Auslastung minimal.
Um der Sache weiter auf den Grund zu gehen habe ich dann mal Schritt für Schritt alles abgeschaltet:
Aber auch danach ist die Last noch hoch.
Was kann ich noch machen, um der Sache auf den Grund zu kommen?
Gruß,
Hendrik
FYI:
Die Docker-Container sind
mein Linux Server (Openmediavault) hat eine sehr hohe Load. Vor allem, seit ich den Rechner vor einigen Tagen neu gestartet habe.
Anbei einige Screenshots dazu
Den Neustart sieht man am 2. Mai an der Unterbrechung.
Die CPU Auslastung ist nicht besonders hoch - und sinkt sogar nach dem Neustart, während die Load einen gegenläufigen Trend hat:
Bei Festplatte und Co sehe ich nix auffälliges.
Prozessor ist ein Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz und es laufen einige Docker Container und eine Home-Assistant VM.
Ich habe schon viel gesucht und diesen Einzeiler gefunden, der wartende Prozesse anzeigt
Code:
ps -eo s,user,cmd | grep ^[RD] | sort | uniq -c | sort -nbr | head -20Das gibt aber einen leeren Output.
Top liefert mir dies:
Code:
Tasks: 559 total, 1 running, 557 sleeping, 0 stopped, 1 zombie
%CPU(s): 14,6 us, 10,2 sy, 0,0 ni, 73,0 id, 0,5 wa, 0,0 hi, 1,6 si, 0,0 st
MiB Spch: 7737,1 total, 136,9 free, 4546,4 used, 3053,8 buff/cache
MiB Swap: 20480,0 total, 17862,6 free, 2617,4 used. 3171,5 avail Spch
PID USER PR NI VIRT RES SHR S %CPU %MEM ZEIT+ BEFEHL
3076 libvirt+ 20 0 2320800 462744 5720 S 34,8 5,8 481:41.09 qemu-system-x86
4737 root 20 0 10,4g 600156 16472 S 13,2 7,6 47:03.10 influxd
4459 henfri 20 0 2920652 138424 0 S 7,3 1,7 83:18.84 python3
867687 henfri 20 0 120688 16956 10700 S 7,3 0,2 0:31.32 smbd
934 root -51 0 0 0 0 S 6,0 0,0 11:15.14 irq/122-enp0s31f6
875488 root 20 0 0 0 0 Z 6,0 0,0 0:00.18 php
4805 root 20 0 11200 4436 1648 S 4,3 0,1 68:55.55 htop
70 root 20 0 0 0 0 S 4,0 0,0 5:31.54 kswapd0
13552 admin 20 0 734284 288008 4324 S 2,3 3,6 41:02.03 bundle
59 root 20 0 0 0 0 S 1,7 0,0 3:02.20 kcompactd0
875445 root 20 0 11392 4500 3356 R 1,7 0,1 0:00.13 top
15 root -2 0 0 0 0 S 1,0 0,0 13:17.07 ktimers/0
28 root -2 0 0 0 0 S 1,0 0,0 13:33.38 ktimers/1
36 root -2 0 0 0 0 S 1,0 0,0 14:31.01 ktimers/2Hier sehen wir schon, das qemu viel benötig - aber nicht sooo viel. Das sind 32% von einem Kern (von 4).
Bei einem Load von 4 (den ich aktuell habe) müssten aber ja alle Kerne zu 100% ausgelastet sein -wenn es denn an der CPU liegt.
Warum die VM 32% CPU braucht können wir nochmal in einem eigenen Thread ergründen (es sei denn, jemand meint, dies sei die Ursache). Denn wenn ich mich in der VM einlogge, ist die CPU Auslastung minimal.
Um der Sache weiter auf den Grund zu gehen habe ich dann mal Schritt für Schritt alles abgeschaltet:
Die VM (HomeAssistant) macht also schon viel aus.load: 7.0
VM aus --> load: 4.0
docker aus --> load: 3.0
reboot, mount SSD-Datenpartition auskommentiert
wieder hoch, load 2.76
smbd gestoppt - unverändert
knxd gestoppt - unverändert
nginx gestoppt - 2.07
nut-server
owserver
spamassassin
libvirtd
nut-monitor
owftp
owhttpd
xrdp
xrdp-sesman
gestoppt. - 1.66
pmcd stop
pmie stop
pmlogger stop
pmproxy stop
virtlogd stop
collectd stop
fail2ban stop
load jetzt 0.64, steigt aber wieder auf 1.2 - aber auch nginx wieder gestartet
reboot: load wieder auf 7.6
Aber auch danach ist die Last noch hoch.
Was kann ich noch machen, um der Sache auf den Grund zu kommen?
Gruß,
Hendrik
FYI:
Die Docker-Container sind
Code:
pihole
unifi1
knx-ng_smarthome-ng_1
nextcloud_app_1
nextcloud_db_1
paperless-ng_webserver_1
paperless-ng_tika_1
paperless-ng_gotenberg_1
paperless-ng_db_1
paperless-ng_broker_1
knx-ng_smartvisu_1
knx-ng_grafana_1
knx-ng_influxdb_1
knx-ng_renderer_1
speedtest
gitlab_gitlab_1
opensprinkler
vaultwarden
scrutiny
portainer_portainer_1
heimdall
TasmoAdmin