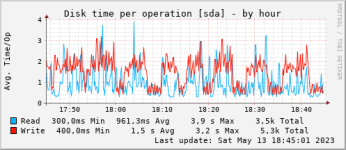
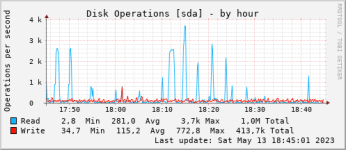
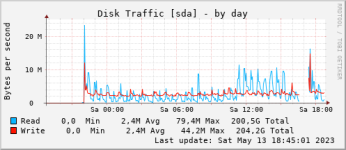
lsof -p 30 |grep -v IPv |grep -v lib |more
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python3 30 smarthome cwd DIR 0,69 2328 34615 /usr/local/smarthome/plugins
python3 30 smarthome rtd DIR 0,69 218 256 /
python3 30 smarthome txt REG 0,69 14416 5586 /usr/local/bin/python3.9
python3 30 smarthome mem REG 0,50 5586 /usr/local/bin/python3.9 (path dev=0,69)
python3 30 smarthome 0u CHR 136,0 0t0 3 /dev/pts/0
python3 30 smarthome 1u CHR 136,0 0t0 3 /dev/pts/0
python3 30 smarthome 2u CHR 136,0 0t0 3 /dev/pts/0
python3 30 smarthome 3w REG 0,75 354 27330801 /usr/local/smarthome/var/log/smarthome-alexa.log
python3 30 smarthome 4w REG 0,75 1968 27253379 /usr/local/smarthome/var/log/smarthome-alexa4shng.log
python3 30 smarthome 5w REG 0,75 0 18531071 /usr/local/smarthome/var/log/smarthome-bewaesserung-dbg.log
python3 30 smarthome 6w REG 0,75 232 27320553 /usr/local/smarthome/var/log/smarthome-forecastsolar.log
python3 30 smarthome 7w REG 0,75 3108 27253510 /usr/local/smarthome/var/log/smarthome-knx-plugin-debug.log
python3 30 smarthome 8w REG 0,75 0 18531073 /usr/local/smarthome/var/log/smarthome-landroid.log
python3 30 smarthome 9w REG 0,75 58421 27313320 /usr/local/smarthome/var/log/smarthome-lichtstatus-dbg.log
python3 30 smarthome 10w REG 0,75 33108289 27313383 /usr/local/smarthome/var/log/smarthome-mqtt-dbg.log
python3 30 smarthome 11w REG 0,75 1136 27339173 /usr/local/smarthome/var/log/smarthome-telegram.log
python3 30 smarthome 12w REG 0,75 277647 27313482 /usr/local/smarthome/var/log/smarthome-uvr-dbg.log
python3 30 smarthome 13w REG 0,75 891 27317793 /usr/local/smarthome/var/log/smarthome-xiaomi.log
python3 30 smarthome 14w REG 0,75 163237 27313354 /usr/local/smarthome/var/log/ow_busmonitor.log
python3 30 smarthome 15w REG 0,75 15877205 27313323 /usr/local/smarthome/var/log/knx_busmonitor.log
python3 30 smarthome 16w REG 0,75 5487695 27380694 /usr/local/smarthome/var/log/smarthome-details.log
python3 30 smarthome 17w REG 0,75 129 27317483 /usr/local/smarthome/var/log/item-value-change.log
python3 30 smarthome 18w REG 0,75 775569 27313355 /usr/local/smarthome/var/log/smarthome-warnings.log
python3 30 smarthome 19r REG 0,75 2 26049223 /usr/local/smarthome/var/run/smarthome.pid
python3 30 smarthome 20u a_inode 0,14 0 1048 [eventpoll]
python3 30 smarthome 21u a_inode 0,14 0 1048 [eventpoll]
python3 30 smarthome 24u a_inode 0,14 0 1048 [eventpoll]
python3 30 smarthome 26u a_inode 0,14 0 1048 [eventpoll]
python3 30 smarthome 29u unix 0x0000000016d600b6 0t0 53007 type=STREAM
python3 30 smarthome 30u unix 0x000000004bfa2264 0t0 53008 type=STREAM
python3 30 smarthome 32u REG 0,75 17666276352 106710 /usr/local/smarthome/var/db/smarthome.db
python3 30 smarthome 42u sock 0,8 0t0 1252348 protocol: TCPv6
python3 30 smarthome 46u a_inode 0,14 0 1048 [eventpoll]