
Nvidia Ampere: Die GA100-GPU im Vollausbau analysiert

tl;dr: Nvidias A100 als erstes Produkt mit Ampere-Architektur ist für KI-Berechnungen im Datenzentrum gedacht. Die Basis ist die mit 826 mm² gigantisch große GA100-GPU. Was deren Vollausbau zu bieten hat, wie er im Vergleich zu Volta dasteht und was sich aus Ampere für GeForce ableiten lässt, klärt der Artikel – soweit es geht.
GA100: Die Überraschung hinter A100
Eigentlich war alles klar: Am Donnerstagnachmittag sollte die Vorstellung von Nvidias für das Datacenter und dort speziell für KI-Training und Inferencing gedachtem Beschleuniger A100 stattfinden. ComputerBase hatte Informationen von Nvidia unter NDA vorab erhalten, um einen Artikel vorzubereiten. Dass es nur relativ wenige Details zu dessen Technik gab, verwunderte schon. Aber es schien klar: Nur A100 in verschiedensten Ausführungen wird in der aufgezeichneten Keynote das Thema sein. Aber es kam anders.
Parallel zur Vorstellung des A100 stellte Nvidia einen umfassenden Artikel zum A100 ins Netz, der deutlich mehr zur neuen Architektur Ampere verriet, und es zeigte sich, dass die GPU des A100 gar nicht A100 heißt, sondern der Hersteller doch dem alten Schema folgt und sie GA100 getauft hat. Und zu genau dieser GPU gab es dann gleich noch ausführliche technische Details.
Keine Überraschung war, dass A100 nicht den Vollausbau der GA100-GPU nutzt. Das war bei der Tesla V100 und der GV100-GPU so und ist in dem Segment die Regel: Gerade bei so riesigen GPUs kann es schnell passieren, dass nicht alle Einheiten korrekt funktionieren, eingeplant abgeschaltete Ausführungseinheiten können den Chip-Ausschuss da signifikant senken. Ungewöhnlich ist bei GA100 allerdings, dass Nvidia gleich 15 Prozent aller Einheiten abgeschaltet hat – mitsamt eines ganzen HBM2-Stacks inklusive Speicherchips und Bandbreite. Der Einschnitt ist enorm und ihn zu kennen, macht GA100 automatisch noch ein Stück beeindruckender, als es A100 schon war.
Das ist der voll aktivierte GA100
Der GA100 ist eine riesige GPU: Sie belegt 826 mm², wird im N7-Verfahren bei TSMC hergestelllt und umfasst 54,2 Milliarden Transistoren. Ein AMD Ryzen Threadripper 3990X mit 64 Kernen verteilt auf 8 CPU-Dies und einen I/O-Die bringt es „nur“ auf 40 Milliarden. Gegenüber Volta hat sich die Anzahl mehr als verdoppelt. Da war durchaus die Frage angebracht, ob allein die zahlreichen KI-Verbesserungen beim A100 so viele Transistoren forderten. Jetzt, da bekannt ist, was hinter dem GA100 wirklich steckt, ergeben die Zahlen plötzlich deutlich mehr Sinn.
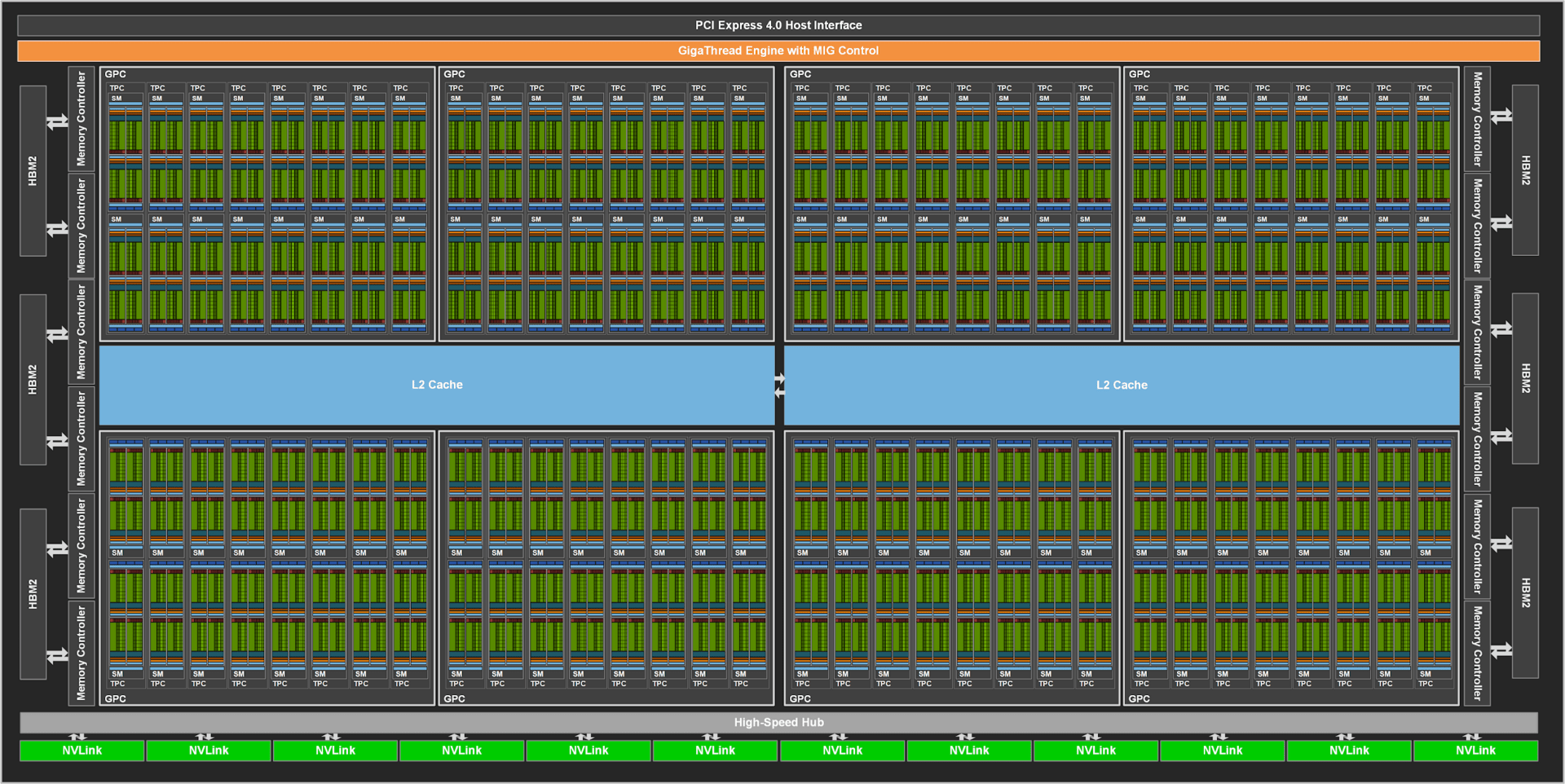
Denn der GA100 verfügt über mehr als die 108 Streaming Multiprocessor und damit die 6.912 FP32-ALUs des A100. Es sind sogar 128 SMs und damit 8.192 ALUs. Damit könnten weitere 18 Prozent an Ausführungseinheiten aktiviert werden, wenn intakt und gewünscht. Der GA100 hat damit automatisch nicht nur mehr FP32-ALUs, auch viele weitere Einheiten skalieren. Aus den sieben Graphics Processing Clusters (GPC, quasi ein gesamter Rechenblock bestehend aus ALUs, TMUs und vielem mehr) werden deren 8, aus 3.456 FP64-ALUs werden 4.096, aus 432 Tensor-Cores werden 512, aus 432 Textureinheiten werden 512 und auch der gesamte Geometrieblock mitsamt den an den SMs angebundenen Caches fällt entsprechend größer aus. Und das ist noch nicht das Ende, weil der A100 auch beim Speicher längst nicht in die Vollen geht.
Denn während der A100 „nur“ 5 HBM2-Stacks mit je 8 GB und einem Speicherinterface von insgesamt 5.120 Bit (1.024 Bit pro Stack) bietet, kann der GA100 auch mit 6 Stacks, 48 GB sowie 6.144 Bit umgehen. Beim Speicher gibt es also noch größere Reserven als bei den Recheneinheiten: 20 Prozent.
Warum ist so viel deaktiviert?
Es stellt sich die Frage, warum Nvidia so viele Einheiten deaktiviert hat. Das lässt sich an dieser Stelle nicht klären, offizielle Aussagen gibt es keine. Zwei Motivationen sind möglich: Zum einen verzichtet Nvidia sicherlich auch mit Ampere auf das, was die Kalifornier auch mit den letzten professionellen GPU-Generationen gemacht haben: Auf den Vollausbau, um so teildefekte Chips immer noch verkaufen zu können.
Das ist vor allem bei riesigen und komplexen Chips wie dem GA100 ratsam, weil dieselbe Anzahl Produktionsfehler pro Wafer einen größeren Anteil der GPUs auf dem Wafer betrifft. Allerdings ist es ungewöhnlich, mal eben ein Fünftel des Chips abzuschalten.
Beim Vorgänger Volta, dem GV100, waren 80 von 84 SMs aktiviert und damit nur 5 Prozent der Einheiten abgeschaltet. Selbst wenn Nvidia aufgrund der anderen Fertigung einen größeren Puffer bräuchte, erscheint der vom GA100 zu groß. Hinzu kommt, dass dies nicht erklären würde, warum auch ein HBM2-Stack nicht besetzt ist. Denn das reduziert die im HPC-Segment so wichtige Speicherbandbreite doch enorm.
Deshalb erscheint ein zweiter Hintergrund durchaus realistisch: Der A100 wird nur der Anfang mit GA100 sein und Nvidia plant in Zukunft noch eine schnellere Version der professionellen Grafikkarte. Quasi das Super-Modell für Profis. Das ist in dem Segment zwar eher ungewöhnlich, aber irgendwann gibt es für alles einen Anfang. Und dem Ausschuss-Argument steht es nicht entgegen. Vielleicht ist die Produktion der riesigen GPU in 7 nm aktuell noch etwas problematisch, Nvidia geht aber davon aus, in Zukunft deutlich besser zu werden. Bis dahin könnte man viele A100 verkaufen und hätte bei besserer Ausbeute dann später noch den Markt für einen „A200“.
Ampere vs. Volta aus der Vogelperspektive
Nvidia hat am grundlegenden Aufbau von Ampere gegenüber Turing – nach aktuellem Stand – keine Änderungen vorgenommen. Die Aufteilung der GPU in GPCs, TPCs sowie SMs sind gleich geblieben und das gilt auch für die Einheiten in diesen Oberkategorien. Das Blockschaltbild ähnelt damit auch dem von Turing sehr.
Verbesserungen beim Cache
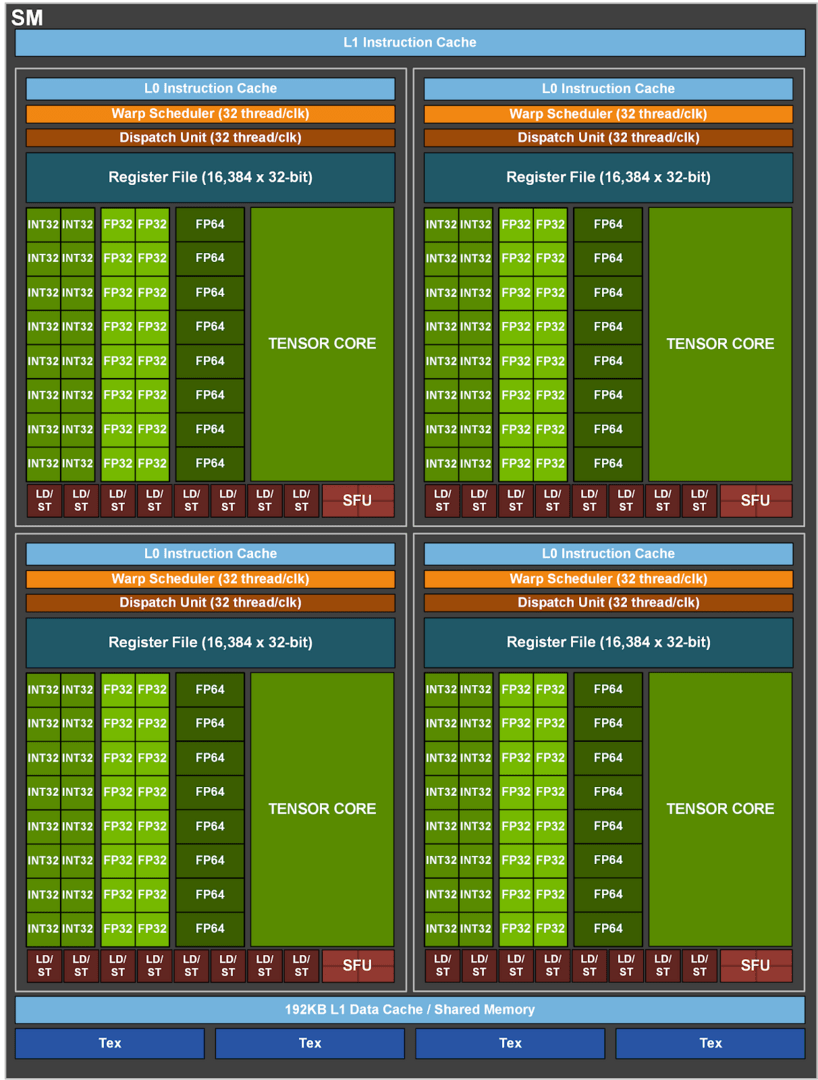
Nvidia hat beim GA100 einige Verbesserungen am Cache vorgenommen. So sind der L1-Cache und der Shared Memory pro SM gegenüber Volta von 128 auf 192 KB angewachsen, in Summe kommt allein der L1-Cache bei GA100 auf knapp 25 MB. Schneller soll der Cache auch geworden sein, doch macht Nvidia dazu keine Angaben.
Der L2-Cache macht noch einen deutlich größeren Sprung. Während er bei Volta 6 MB groß war, sind es beim GA100 mal eben 40 MB – also fast sieben Mal so viel. Der L2-Cache ist aufgeteilt in zwei verschiedene Partitionen, was die Bandbreite und die Zugriffszeiten verbessert. Darüber hinaus hat Nvidia auch die Crossbar des Caches, die den schnellen Zwischenspeicher mit den SMs verbindet, modifiziert, sodass die Leserate des Caches 2,3 Mal so hoch wie bei Volta liegen soll. Zudem soll es für den Programmierer nun einfacher sein zu bestimmen, welche Daten im Cache liegen sollen und welche nicht.
Die Tensor Cores sind jetzt 4× so schnell wie bei Volta
Es klingt schon verwunderlich, dass der A100 mit lediglich 432 Tensor Cores bei geringerem Takt deutlich schneller Matrizen berechnen können soll als der Vorgänger Tesla V100 mit Volta mit immerhin 640 Tensor Cores.. Die Botschaft ist allerdings klar: Die Tensor Cores sind wesentlich schneller.
Volta (und Turing) hat 8 Tensor-Cores pro SM, die jeweils 64 FP16/FP32 Mixed-Precision Fused Multiply-Add (FMA) durchführen können. Bei Ampere sind es nur noch 4 Tensor-Kerne pro SM, die dafür aber gleich 256 FP16/FP32 FMA-Operationen pro Takt durchführen können. Trotz nur halb so vieler Tensor-Cores pro SM hat sich die Matrizenleistung bei Ampere gegenüber dem Vorgänger also verdoppelt. Da der GA100 auch über mehr SMs verfügt, ergibt dies die deutlich gesteigerte KI-Leistung.
Für weitere Details über die KI-Fähigkeiten von Ampere ist ein Blick in den Bericht zum Derivat A100 empfehlenswert.
| Nvidia A100 (Produkt) | Nvidia GA100 (GPU) | Tesla V100 (Produkt) | |
|---|---|---|---|
| Architektur | Ampere | Volta | |
| GPU | GA100 | GV100 | |
| Fertigung | TSMC N7 | TSMC 12FFN | |
| Transistoren | 54,2 Milliarden | 21,1 Milliarden | |
| Die Size | 826 mm² | 815 mm² | |
| SMs | 108 | 128 | 80 |
| FP64 CUDA Cores | 3.456 | 4.096 | 2.560 |
| FP32 CUDA Cores | 6.912 | 8.192 | 5.120 |
| Tensor Cores | 432 | 512 | 640 |
| GPU-Takt | 1.410 MHz | 1.455 MHz | |
| FP64-Performance (Peak) | 9,7 TFLOPS | 11,6 TFLOPS* | 7,4 TFLOPS |
| FP32-Performance (Peak) | 19,5 TFLOPS | 23,1 TFLOPS* | 14,9 TFLOPS |
| FP16-Performance (Tensor-Peak) | 312 TOPS | 370 TOPS* | 120 TFLOPS |
| INT8-Performance (Tensor-Peak) | 624 TOPS | 739 TOPS* | 60 TOPS |
| Textureinheiten | 432 | 512 | 336 |
| Speicher | 40 GB HBM2 | 48 GB HMB2 | 32 GB HBM2 |
| Speichertakt | 1.215 MHz | 880 MHz | |
| Speicherinterface | 5.120 Bit | 6.144 Bit | 4.096 Bit |
| Bandbreite | 1,56 TB/s | 1,87 TB/s* | 900 GB/s |
| L2-Cache | 40 MB | 48 MB | 6 MB |
| TDP | 400 Watt | 300 Watt | |
| Interconnect | NVLink 600 GB/s PCIe 4.0 64 GB/s |
NVLink 300 GB/s PCIe 3.0 32 GB/s |
|
| * Bei gleichem Takt wie A100 | |||
Grafik berechnen ist möglich, aber kein Raytracing
Es scheint derzeit gesichert, dass AMDs neue Profi-GPU Arcturus keine Grafik berechnen kann und sich rein auf HPC-Aufgaben konzentrieren wird. Bei Ampere ist dies nicht der Fall, zumindest spricht Nvidia auch von „Graphics Rendering“ und „Cloud Gaming“. Hinzu kommt, dass das Blockschaltbild die fürs Spielen notwendigen Textureinheiten zeigt. Zwar fehlen die Geometrie-Einheiten sowie die ROPs, die für die Grafikberechnung ebenso benötigt werden. Auf ihre Darstellung hatte Nvidia allerdings bereits beim Blockschaltbild von Volta verzichtet. Sie sind also vermutlich vorhanden, spielen im Einsatzgebiet des A100 aber keine Rolle.
Was auf dem Blockschaltbild des GA100 ebenso fehlt, sind die Raytracing-Einheiten. Nvidia hat mittlerweile auch bestätigt, dass der GA100 über keine Raytracing-Einheiten verfügt. Dasselbe gilt für die Videoeinheit NVENC. Als Grund gibt Nvidia an, dass beides im HPC-Einsatz schlicht nicht benötigt werden. Dasselbe gilt für Monitoranschlüsse.
Was bedeutet der GA100 für Spieler?
GA100 ist mit seiner schieren Größe, der Masse an Ausführungseinheiten und den großen Caches zweifelsohne spannend. Doch mit der Vorstellung von Ampere stellt sich auch die Frage, was sich von der professionellen GPU für die Spieler-Grafikkarten der GeForce-Reihe mit der vielerorts schon als Überschrift genutzten „GeForce RTX 3080 Ti“ ableiten lässt? Wenn man ehrlich ist lautet die Antwort: reichlich wenig.
Auch die neuen GeForce-RTX-Grafikkarten (und GTX?) werden auf Ampere basieren, die Basis zwischen den GPUs für Profis und Spieler ist gleich. Das war bei Volta und Turing auch so. Alle Verbesserungen bei Ampere in für Gaming-GPUs relevanten Bereichen werden auch die Spieler erhalten. Dazu zählen heutezutage zum Beispiel die Verbesserungen der Tensor-Cores (DLSS, Denoising bei RTX) und des Caches. Was bis jetzt aber noch völlig unklar ist, ist in wie weit die ALUs abseits der Tensor-Kerne schneller geworden sind und wie es um Geschwindigkeit und Anzahl der RT-Kerne steht. Ebenso ist offen, ob beim Front-End, den Geometrie-Einheiten, den TMUs oder den ROPs etwas getan hat. Und auch, ob TSMCs 7-nm-Prozess genutzt wird, und wenn ja, in welcher Form, ist weiterhin nur Rätselraten.
Was dagegen gesichert ist, ist dass „Gaming-Ampere“ eine völlig andere Konfiguration als Profi-Ampere erhalten wird. So wird die Spieler-Grafikkarte mit Sicherheit deutlich weniger Shadereinheiten und alles, was damit zusammenhängt, erhalten. Im Gegensatz dazu wird die Taktrate mit Sicherheit deutlich steigen und wieder bei mindestens um die 2,0 GHz anstatt 1.410 MHz beim A100 liegen. Auch beim Cache wird es vermutlich große Einschnitte geben.
Beim Speicher dürfte sich quasi alles ändern. HBM2 wird der Spieler kaum bekommen, stattdessen wird vermutlich 18 Gbps (9.000 MHz) schneller GDDR6-Speicher eingesetzt. Damit wird die Speicherbandbreite deutlich geringer ausfallen, für Spiele sollte es aber reichen.
Wie sich Raytracing ändern wird, ist noch ein Geheimnis
Während der GA100 völlig auf Raytracing-Einheiten verzichtet, werden die GeForce-RTX-3000-Ableger diesbezüglich mit Sicherheit deutlich gegenüber Turing aufrüsten. Ob dies jetzt schlicht deutlich mehr RT-Cores, deutlich verbesserte RT-Cores, beides oder womöglich etwas wie bei den Tensor-Cores bedeutet (weniger, aber dafür deutlich bessere Kerne), wird sich noch zeigen müssen.
Ebenso unklar ist und bleibt das Erscheinungsdatum. Aktuell deutet immer noch alles auf einen Marktstart in diesem Jahr hin. Doch ob dies noch im dritten, oder (wahrscheinlicher) erst im vierten Quartal geschehen wird, dazu liegen noch keine verlässlichen Informationen vor. ComputerBase wird fundierte Gerüchte zu diesem Thema über die kommenden Monate aufgreifen, aber nicht jedem vermeintlich authentischen Leak zu GeForce RTX 3000 nachjagen.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.