AMD CDNA 2 Whitepaper: Mehr Details zum Compute-Monster Instinct MI200

AMDs HPC-Grafikkarten-Serie Instinct MI200 macht mit brachialer Rechenleistung auf sich aufmerksam. Dafür verantwortlich ist auch, aber nicht nur, der Multi-Chip-Ansatz, der zwei GPU-Dies in einer GPU vereint. Das offizielle Whitepaper (PDF) verrät inzwischen weitere Details. Ein Überblick.
MI200 lässt MI100 weit hinter sich
Die Serie Instinct MI200 gibt es in drei Ausführungen: Als MI250X und MI250 im Formfaktor OCP Accelerator Module (OAM) und MI210 im PCIe-Steckkartenformat. Das Topmodell ist dabei mindestens mehr als doppelt so schnell wie der Vorgänger Instinct MI100 auf Basis von CDNA 2.
-
 Die Instinct MI210 im PCIe-Format folgt „in Kürze“ (Bild: AMD)
Die Instinct MI210 im PCIe-Format folgt „in Kürze“ (Bild: AMD)




Schon zur Vorstellung bekannt war, dass AMD diese Leistungsexplosion zu einem großen Teil durch den Einsatz zweier Graphics Compute Dies (GCDs) auf dem GPU-Package möglich macht. Die Anzahl der CUs je GCD liegt bei 110, was in Summe 220 CUs entspricht, während der eine Die der MI100 auf 120 CUs kam. Laut dem Whitepaper liegt der Vollausbau eines GCDs bei 112 CUs.
| Instinct MI200 | Instinct MI100 | ||
|---|---|---|---|
| Ausprägung | MI250X | MI250 | MI100 |
| Eckdaten | |||
| Architektur | CDNA 2 | CDNA | |
| Fertigung | „6 nm“ | 7 nm TSMC FinFET | |
| Compute Units | 220 | 216 | 120 |
| Shader | 14.080 | 13.312 | 7.680 |
| max. Takt | 1.700 MHz | 1.502 MHz | |
| Speicher | 128 GB HBM2e, 8.092 Bit (1,6 GHz, 3,2 TB/s) |
32 GB HBM2, 4.096 Bit (1,2 GHz, 1,2 TB/s) |
|
| Infinity Fabric Links | 8 | 6 | 3 |
| max. Board Power | 500 (passiv) oder 560 Watt (Wakü) | 300 Watt (passiv) | |
| Leistung* | |||
| FP64/FP32 Vektor | 47,9/47,9 TFLOPS | 45,3/45,3 TFLOPS | 11,5/23,1 TFLOPS |
| FP64/FP32 Matrix | 95,7/95,7 TFLOPS | 90,5/90,5 TFLOPS | –/46,1 TFLOPS |
| * MI200 bei 560 Watt. Die Eckdaten und Leistungswerte der MI200 im PCIe-Steckkarten-Format sind noch nicht bekannt | |||
Durch eine leichte, zusätzliche Taktsteigerung ergibt sich auch mit 9 Prozent weniger CUs pro GDC eine Skalierung der FP32-Leistung um den Faktor 2,1x. In anderen Bereichen steigt die Leistung allerdings noch deutlicher um den Faktor 4. Was dahinter steckt, verrät das Whitepaper im Detail.
CDNA 2 bietet die volle Geschwindigkeit bei FP64
Auf der Ebene der CUs gab es auf den ersten Blick dabei nur inkrementelle Veränderungen. Schon bei CDNA wurde letztes Jahr eine Struktur gewählt, die ähnlich wie bei RDNA 2 einige Elemente zwischen die beiden ALU-Gruppen setzt, während der Rest wie bei GCN geblieben ist. Die Verbesserungen von CDNA 2 gegenüber CDNA sieht man wiederum in den ALUs. So wurden die Recheneinheiten in vielen ihrer Funktion erweitert und beschleunigt.
-
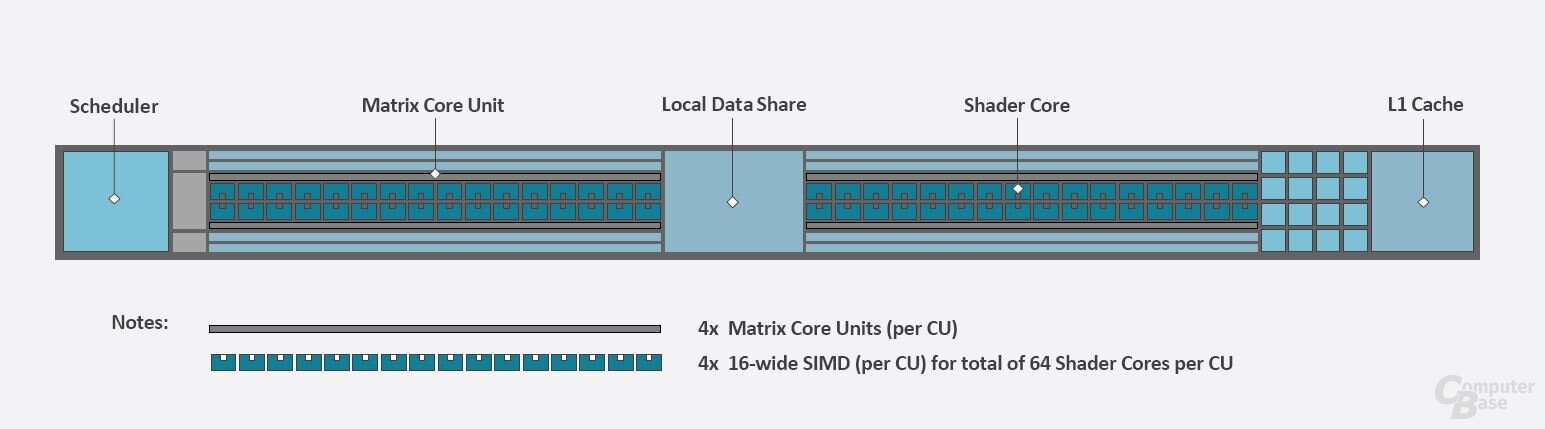 Die Compute Unit von CDNA 2 (MI250)
Die Compute Unit von CDNA 2 (MI250)
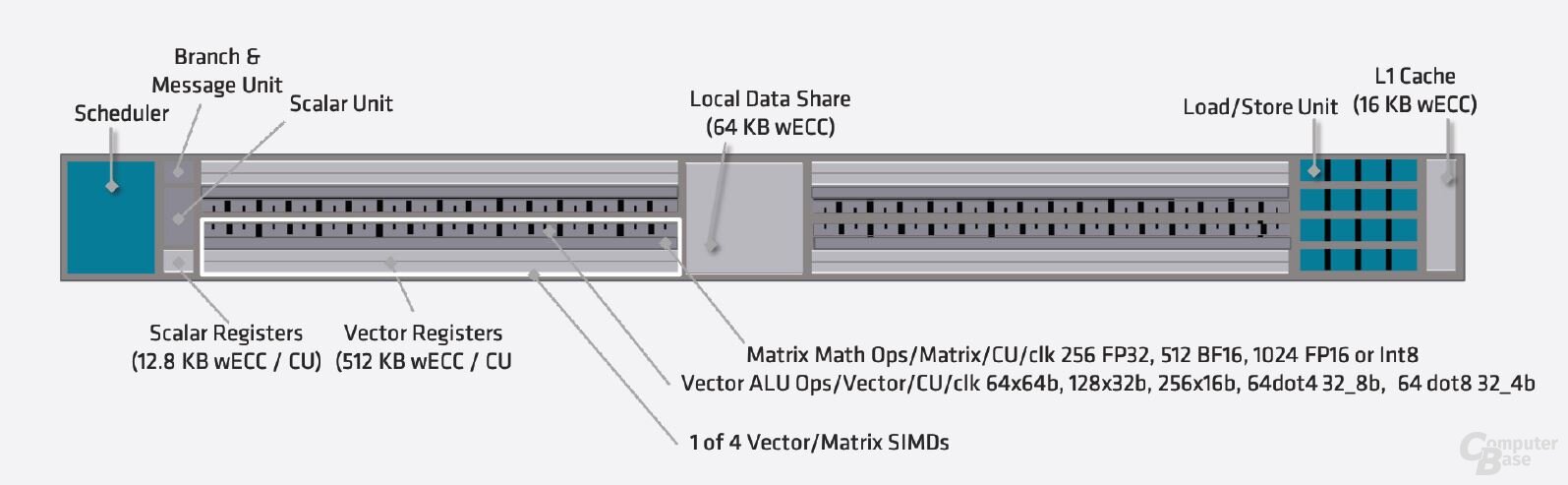


Traditionell sind GPUs auf maximale Rechenleistung bei FP32, der sogenannten einfachen Genauigkeit, ausgelegt. MI100 verarbeitete Zahlen mit FP64, also 64 bit pro Zahl und deswegen doppelte Genauigkeit, nur mit halber Geschwindigkeit, um Register und damit Waferfläche zu sparen. Das Verhältnis von 1:2 zwischen FP32 und FP64 war trotzdem ein klares Zeichen für eine Server-GPU, arbeitete die verhältnismäßig aufgebohrte Consumer-GPU Radeon VII doch mit 1:4 und der Vorgänger Vega 64 mit 1:16.
Bei der MI200 ist das anders. Von Vorneherein wurden die ALUs für FP64 ausgelegt und verarbeiten FP64-Berechnungen im Verhältnis 1:1. Dafür wurden die Register so verbreitert, dass jede ALU direkt eine FP64-Zahl verarbeiten kann. Bei 128 ALUs pro CU macht das 128 FLOPS pro CU pro Clock, doppelt so viel wie bei MI100 und MI50.
Rapid Packed Math kann FP32 weiter beschleunigen
Einen zusätzlichen Vorteil liefern die großen Register: Mittels Rapid Packed Math (RPM) können, bei angepasstem Code, zwei FP32-Berechnungen gleichzeitig pro ALU durchgeführt werden. Beispiele für die erforderliche Code-Anpassung gibt AMD im Whitepaper (PDF). Dadurch liegt die maximale FP32-Leistung nochmals doppelt so hoch wie von AMD auf den Folien angegeben. In den passenden Anwendungen liegt AMD damit teilweise extrem weit vor der Konkurrenz.
| Datenformat | MI100 | MI250X* | A100 |
|---|---|---|---|
| Standard-ALUs | |||
| Vector FP64 (TFLOPS) | 11,5 | 47,9 | 9,7 |
| Vector FP32 (TFLOPS) | 23,1 | 47,9 | 19,5 |
| Vector FP32 RPM (TFLOPS) | N/A | 95,7 | N/A |
| Matrix-Einheiten | |||
| Matrix FP64 (TFLOPS) | N/A | 95,7 | N/A |
| Matrix FP32 (TFLOPS) | 46,1 | 95,7 | 156 |
| Matrix FP16 (TFLOPS) | 184,6 | 383 | 312 |
| Matrix BF16 (TFLOPS) | 92,3 | 383 | 312 |
| Matrix INT8 (TOPS) | 184,6 | 383 | 624 |
| * MI250X bei 560 Watt mit Server-Wakü, sonst maximal 500 Watt TDP | |||
AMDs Matrix-Cores im Vergleich zu Tensor-Cores
Etwas unter dem Radar hat AMD in CDNA bereits in 1. Generation Matrix-Cores eingeführt, die wie die Tensor-Cores von Nvidia Matrix-Operationen beschleunigen und insbesondere bei KI-Aufgaben punkten. In CDNA 2 hat AMD, neben der komplett neuen Einführung von FP64-Matrix-Operationen, auch die Berechnungen von BF16 ausgebaut. Bei diesen gibt es wie bei der traditionellen FP32-Leistung mit RPM mit dem Faktor 4,2x einen doppelt so großen Zuwachs wie bei der sonstigen Rechenleistung.
Interessant wird es, wenn man die Rechenleistung einer einzigen Matrix-Einheit mit der eines Tensor-Cores über verschiedene Generationen vergleicht. So waren AMDs Matrix-Einheiten der ersten Generation zwar bereits deutlich schneller und von der Funktionalität breiter aufgestellt als Nvidias erste Generation der Tensor-Cores im Volta-Beschleuniger V100. Gegenüber den Tensor-Cores der dritten Generation in Ampere-GPUs sind aber auch AMDs verbesserte Matrix-Cores noch deutlich schwächer. Einzig die fast doppelt so hohe Anzahl (880 gegenüber 432) und der höhere Takt (1700 MHz gegenüber 1410 MHz) sorgen dafür, dass AMD in einigen Bereichen auf Augenhöhe agiert. Mit dem Erscheinen der nächsten Generation von Nvidias Server-GPUs könnte Nvidia in KI wieder davonziehen.
| AMD CDNA (2) | Nvidia Volta/Ampere | |||
|---|---|---|---|---|
| Datenformat | 1. Gen Matrix Core | 2. Gen Matrix Core | 1. Gen Tensor Core | 3. Gen Tensor Core |
| Matrix FP64 (FLOPS) | N/A | 64 | N/A | N/A |
| Matrix FP32 (FLOPS) | 64 | 64 | N/A | 256 |
| Matrix TF32 (FLOPS) | N/A | N/A | N/A | 256 |
| Matrix FP16 (FLOPS) | 256 | 256 | 128 | 512 |
| Matrix BF16 (FLOPS) | 128 | 256 | N/A | 512 |
| Matrix INT8 (OPS) | 256 | 256 | N/A | 1024 |
| Rechenleistung pro Core pro Clock. | ||||
Zwei Graphic Compute Dies in einer GPU
Der Aufbau eines GCD hat sich im Vergleich zum Chip der MI100 wiederum nicht grundlegend verändert. Die Neuerungen stecken auch hier eher im Detail. So wurde die Bandbreite des L2-Caches je GCD bei gleichbleibender Größe von 8 MB mit jetzt knapp 7 TB/s mehr als verdoppelt. Dazu wurden die Algorithmen zur Datenverteilung im L2-Cache für den maximalen FP64-Durchsatz bei atomaren Operationen optimiert.
Außerdem kommen bei CDNA 2 zur typischen PCIe-Anbindung mehrere Infinity-Fabric-Links hinzu, die die Kommunikation sowohl mit dem zweiten GCD auf derselben GPU als auch mit weiteren GPUs im System sicherstellen. Zwischen zwei GCDs arbeitet die Infinity Fabric mit bis zu 400 GB/s, zwischen mehreren GPUs in einem System mit je 100 GB/s (50 GB/s bidirektional) und damit bis zu 800 GB/s.
AMD spricht hier von cache-kohärenter Kommunikation, gesteuert vom AMD-Epyc-Prozessor der dritten Generation, die allerdings nur die MI250X nutzen darf. Die Server-CPU kann dabei auf jeden Teil des VRAMs zugreifen und ihn als Cache mit der GPU nutzen. Die GPUs merken sich dabei, welche Teile des VRAMs zurzeit mit der CPU geteilt werden, um Performance-Engpässe zu vermeiden. Der Adressraum, den die GPU dafür ansprechen kann, reicht für 4 Petabyte physischen und 128 Petabyte virtuellen Speicher. In einem Node mit bis zu 8 Beschleunigerkarten soll dabei jeder GCD dem System als eigenständige GPU angezeigt werden.
Interessanterweise beinhalten sowohl CDNA als auch CDNA 2 Videodekodiereinheiten („Multimedia Engine“ bzw. „VCN“), obwohl es keine Monitoranschlüsse gibt. Diese können laut AMD dafür genutzt werden, um Machine-Learning-Aufgaben direkt mit Video- und Bildmaterial zu füttern, welches dann auf der Karte in Echtzeit dekodiert wird. Die Videodekodiereinheiten unterstützen VP9, HEVC, AVC und JPEG.
-
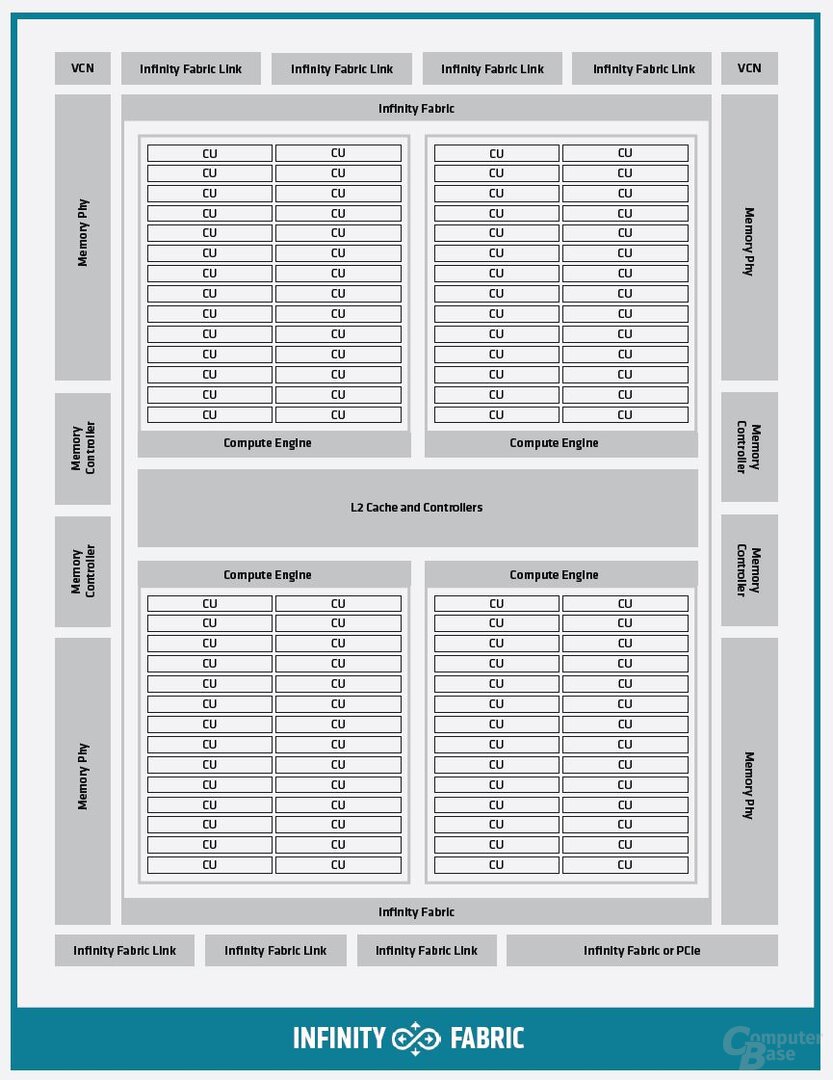 MI200-Blockschaltbild
MI200-Blockschaltbild
Die Reader's Choice Awards 2026