Arm-Kerne 2022: Cortex-X3: Everything is bigger in Texas
2/3Innerhalb der TCS22 stellt Arm im Bereich „Compute“ drei neue respektive zwei neue CPU-Kerne und einen optimierten CPU-Kern vor. Neuer großer Prime-Core ist der Cortex-X3, den Arm am Standort in Austin, Texas entwickelt hat. Der neue Cortex-A715 wurde hingegen im französischen Technologiepark Sophia Antipolis im Gemeindeverband CASA entworfen, während der Cortex-A510 Refresh am ältesten Standort in Cambridge, England entstanden ist, wo das Unternehmen nach wie vor seinen Hauptsitz hat.
Single-Core-Leistung steigt um bis zu 25 Prozent
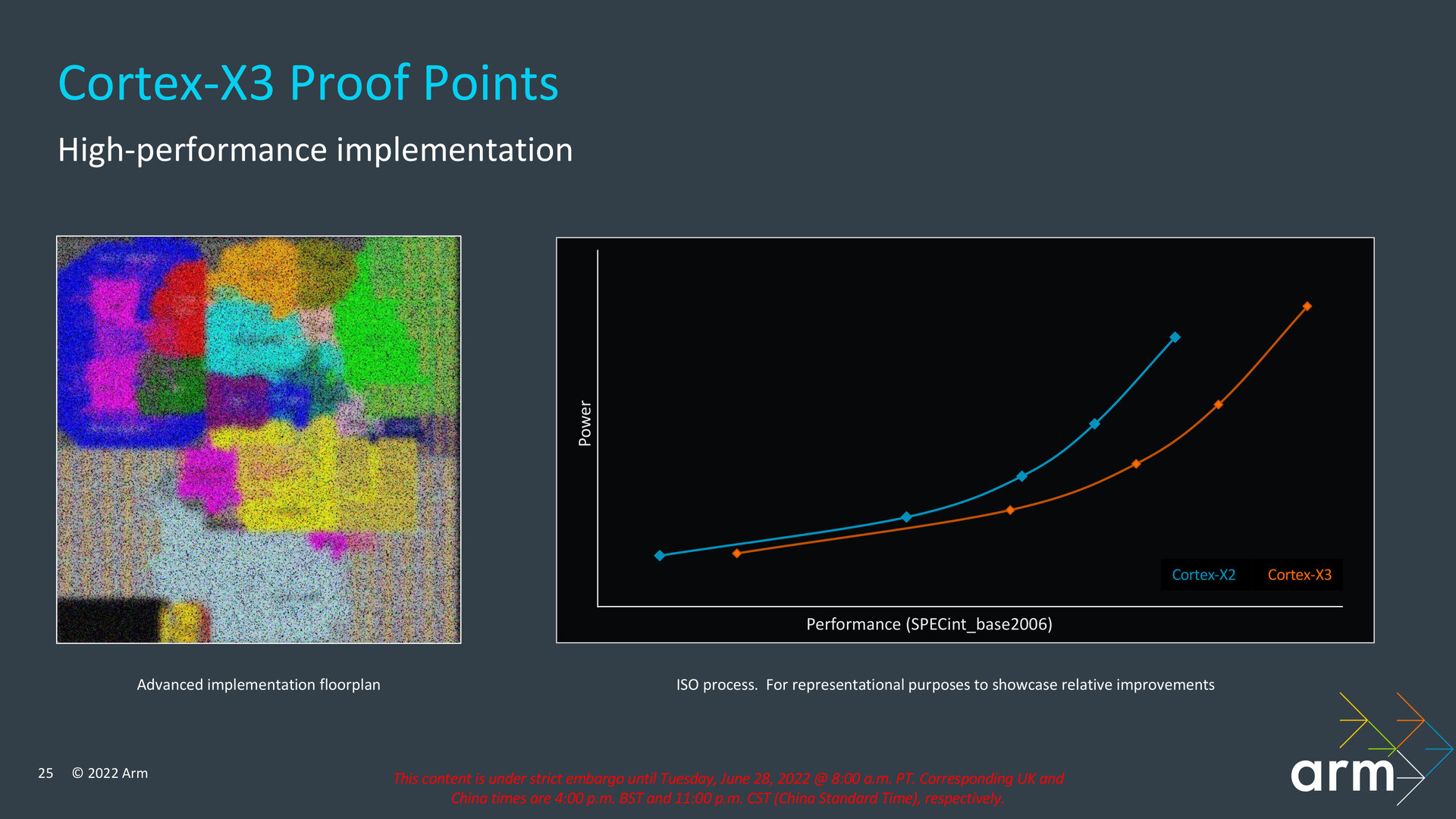
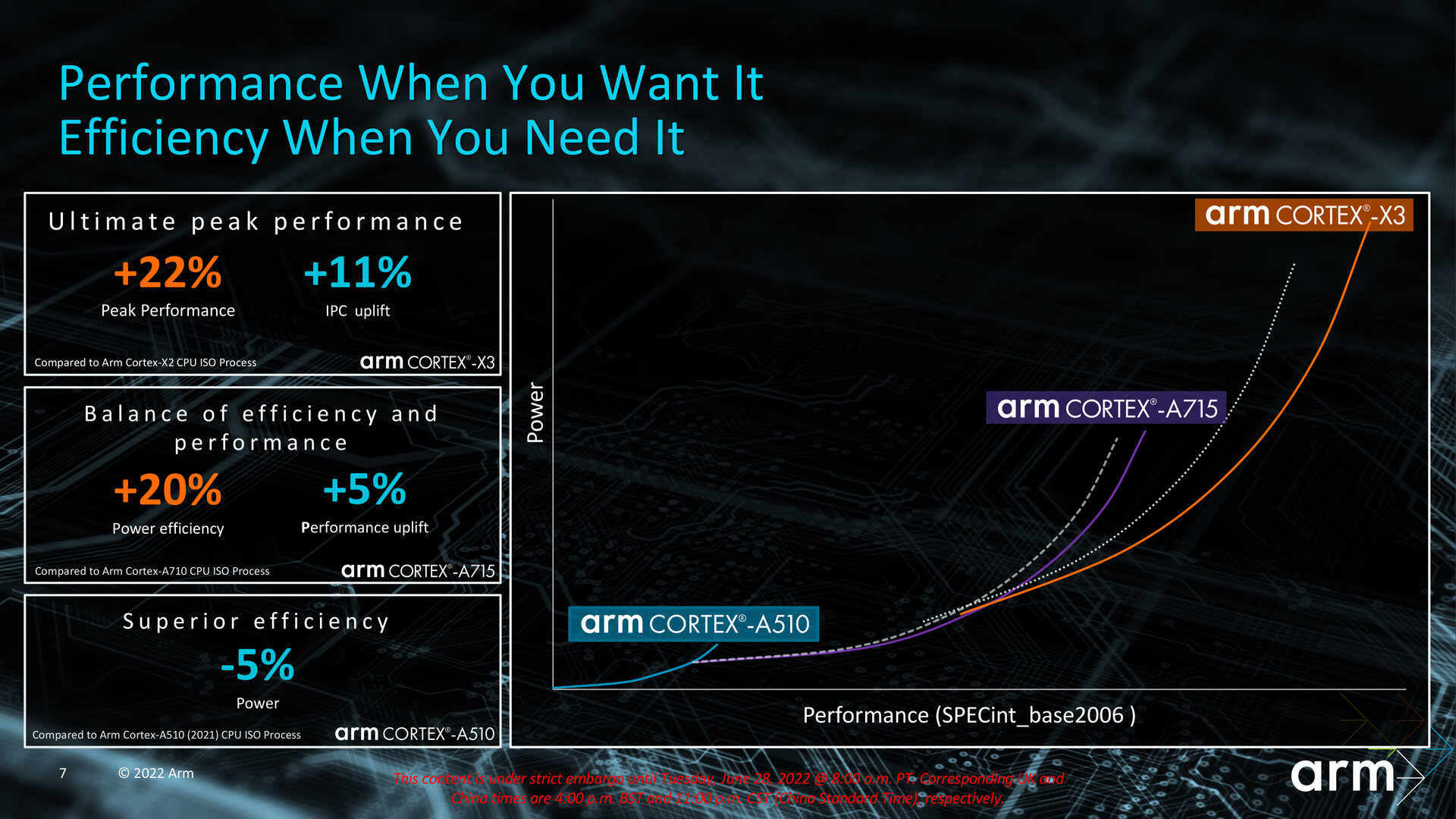
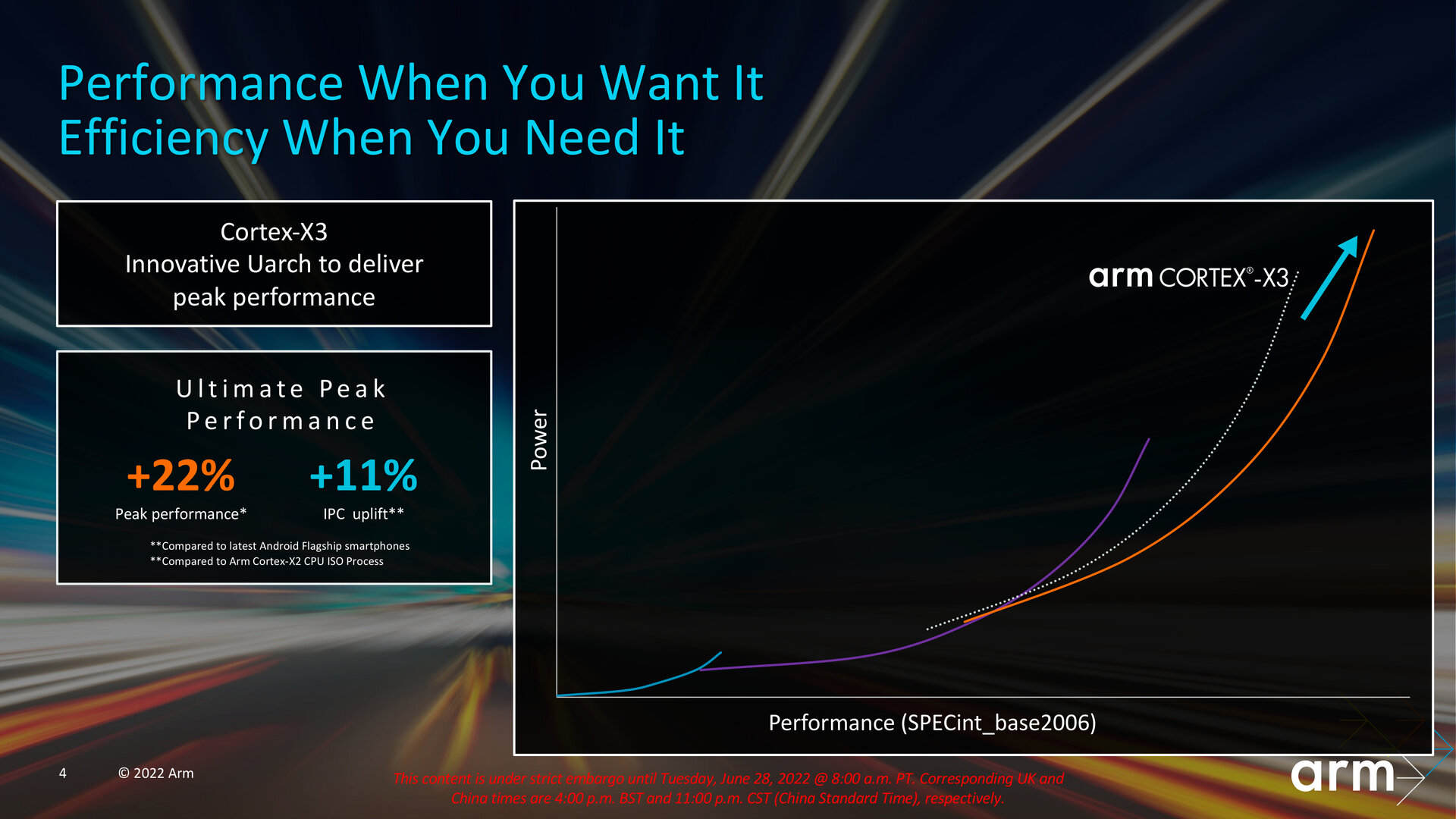
Als Nachfolger von Cortex-X1 und Cortex-X2 soll der neue Cortex-X3 im geometrischen Mittel der Benchmarks SPECRate 2017_int_base, SPECint_base2006 und Geekbench 5 eine 25 Prozent höhere Single-Core-Leistung gegenüber einem „aktuellen Android-Flaggschiff-Smartphone“ (Stand März 2022) liefern, wenn der Cortex-X3 mit satten 3,3 GHz und in einer nicht unüblichen Konfiguration mit 1 MB L2- und 8 MB L3-Cache betrieben wird. Nur auf die Peak-Leistung im SPECint_base2006 bezogen liegt das Plus bei 22 Prozent. Der Maximaltakt fällt in diesem Beispiel von Arm höher als bei derzeitigen Lösungen mit Cortex-X2 aus, die lediglich bis zu 3,2 GHz etwa beim nagelneuen MediaTek Dimensity 9000+ oder Qualcomm Snapdragon 8+ Gen 1 erreichen. Die normalen Ausbaustufen dieser beiden Chips mit Cortex-X2 liegen im Bereich von 3,0 GHz. Nur auf SPECint_base2006 bezogen
-
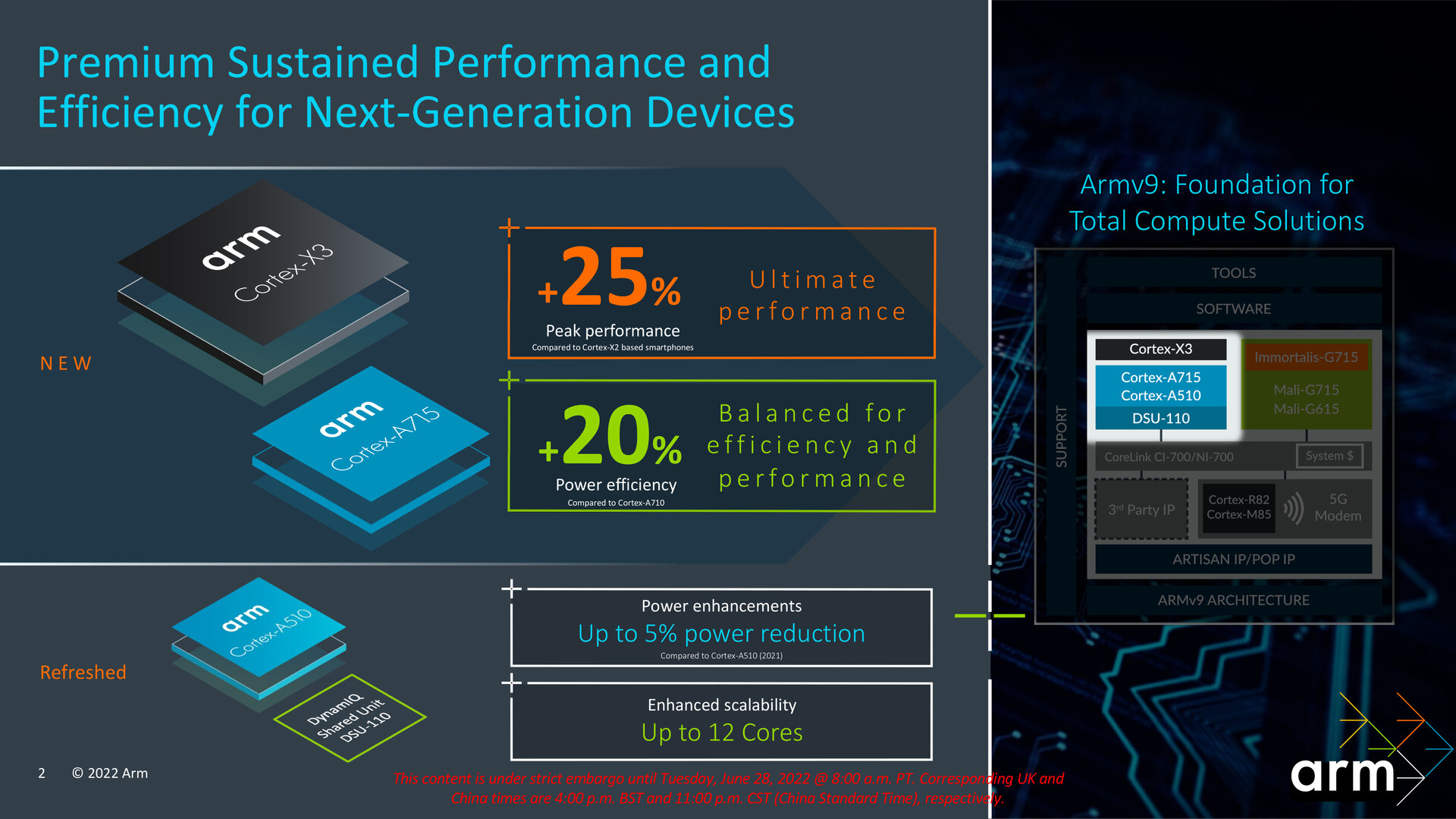 Cortex-X3, Cortex-A715 und Cortex-A510 Refresh im Überblick (Bild: Arm)
Cortex-X3, Cortex-A715 und Cortex-A510 Refresh im Überblick (Bild: Arm)

Schneller als ein Intel Core i7-1260P im Notebook
Ein sattes Plus von 34 Prozent Single-Core-Leistung soll der Cortex-X3 im Vergleich zu heutigen Prozessoren in Notebooks bieten, wobei Arm in diesem Szenario einen Takt von 3,6 GHz ansetzt, was sich mit entsprechender Kühlung durchaus in einem Notebook realisieren ließe, und den L3-Cache auf 16 MB gegenüber dem Smartphone verdoppelt. Für den Vergleich im Benchmark SPECRate2017_int_base wurde ein mit 28 Watt konfigurierter Intel Core i7-1260P aus der aktuellen Alder-Lake-Generation herangezogen.
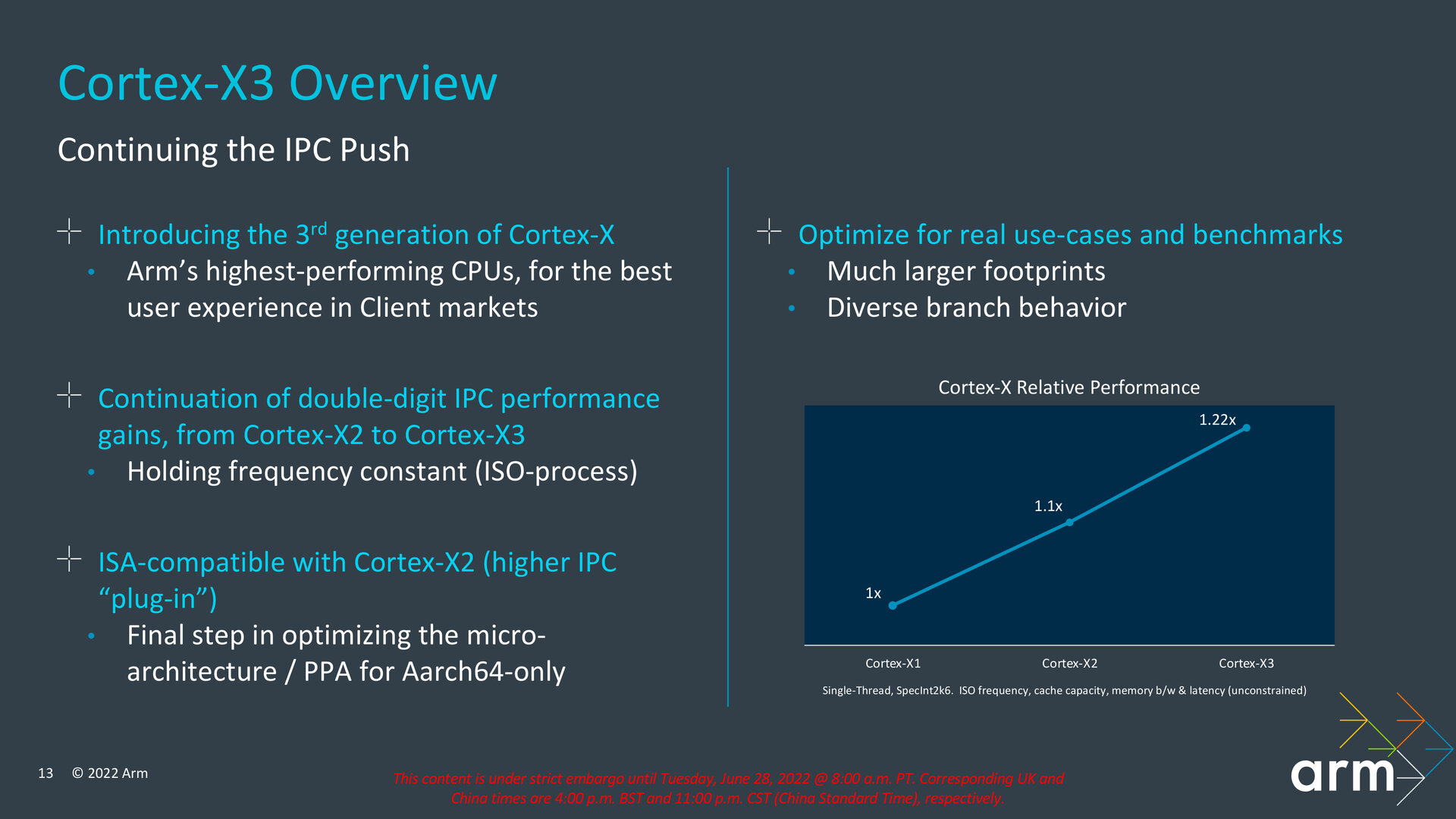
IPC-Zugewinn liegt bei 11 Prozent
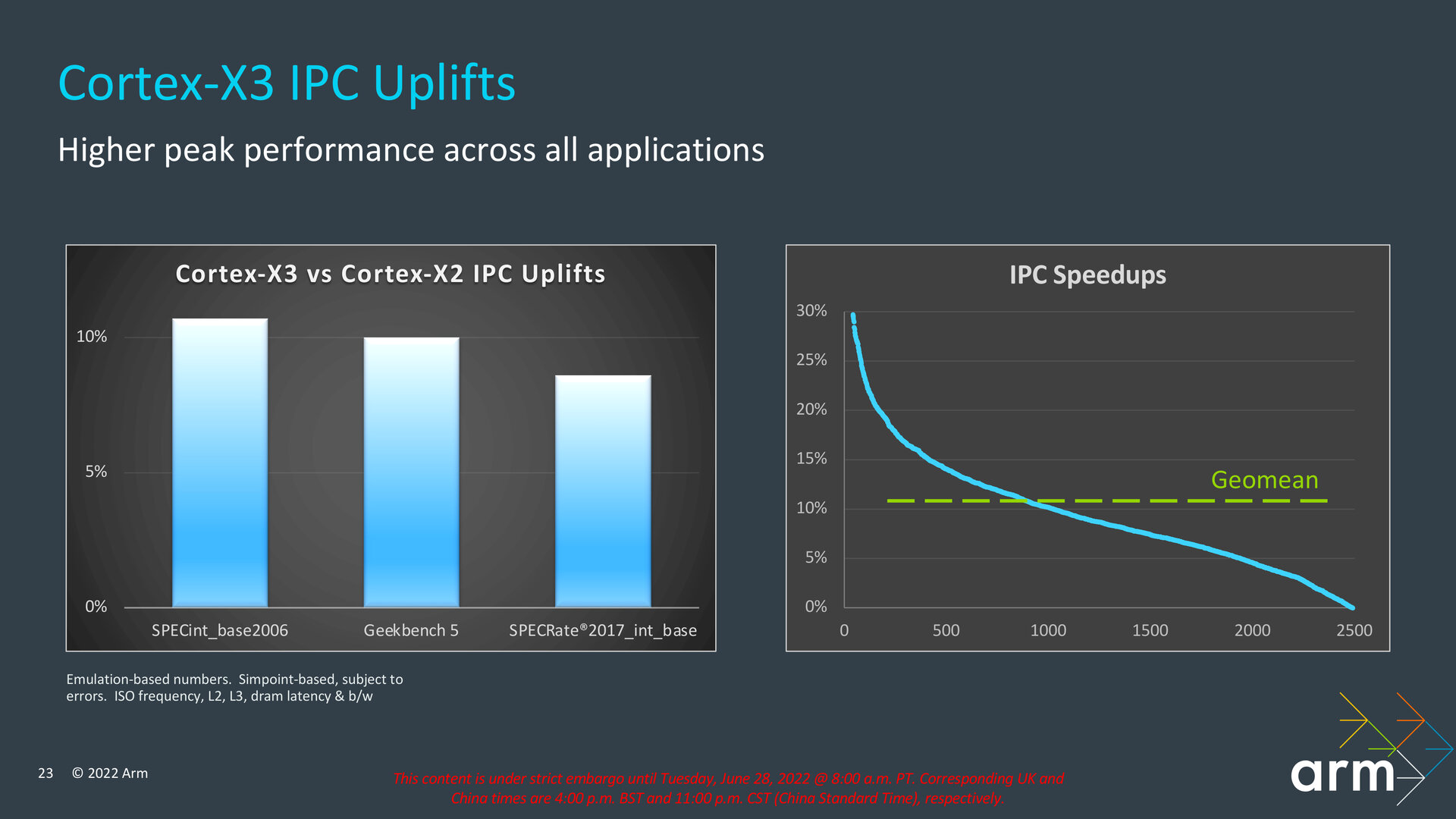
Den eigentlichen IPC-Zugewinn gibt Arm mit 11 Prozent an, sodass der Hersteller von einem dritten Jahr infolge mit zweistelligem IPC-Zuwachs spricht. Vom Cortex-X1 kommend, lag der Schritt noch bei 10 Prozent zum Cortex-X2. Der Wert wurde unter Verwendung desselben Takts und derselben Fertigung (ISO) ermittelt. Arm versteht den Cortex-X3 als Plug-in für eine höhere IPC, weil der Kern vollständig ISA-kompatibel zum Cortex-X2 ist und die finale Ausbaustufe in der Optimierung der Mikroarchitektur darstellt. „Power, Performance and Area“ (PPA) sind beim Cortex-X3 ausschließlich für AArch64 ausgelegt. Wie schon im letzten Jahr beim Cortex-X2 lassen sich keine 32-Bit-Apps auf dem Kern ausführen. Diese Eigenschaft ist jetzt auf den kleinsten Cortex-A510 beschränkt.
-
 Cortex-X3 legt Wert auf IPC-Zugewinn (Bild: Arm)
Cortex-X3 legt Wert auf IPC-Zugewinn (Bild: Arm)

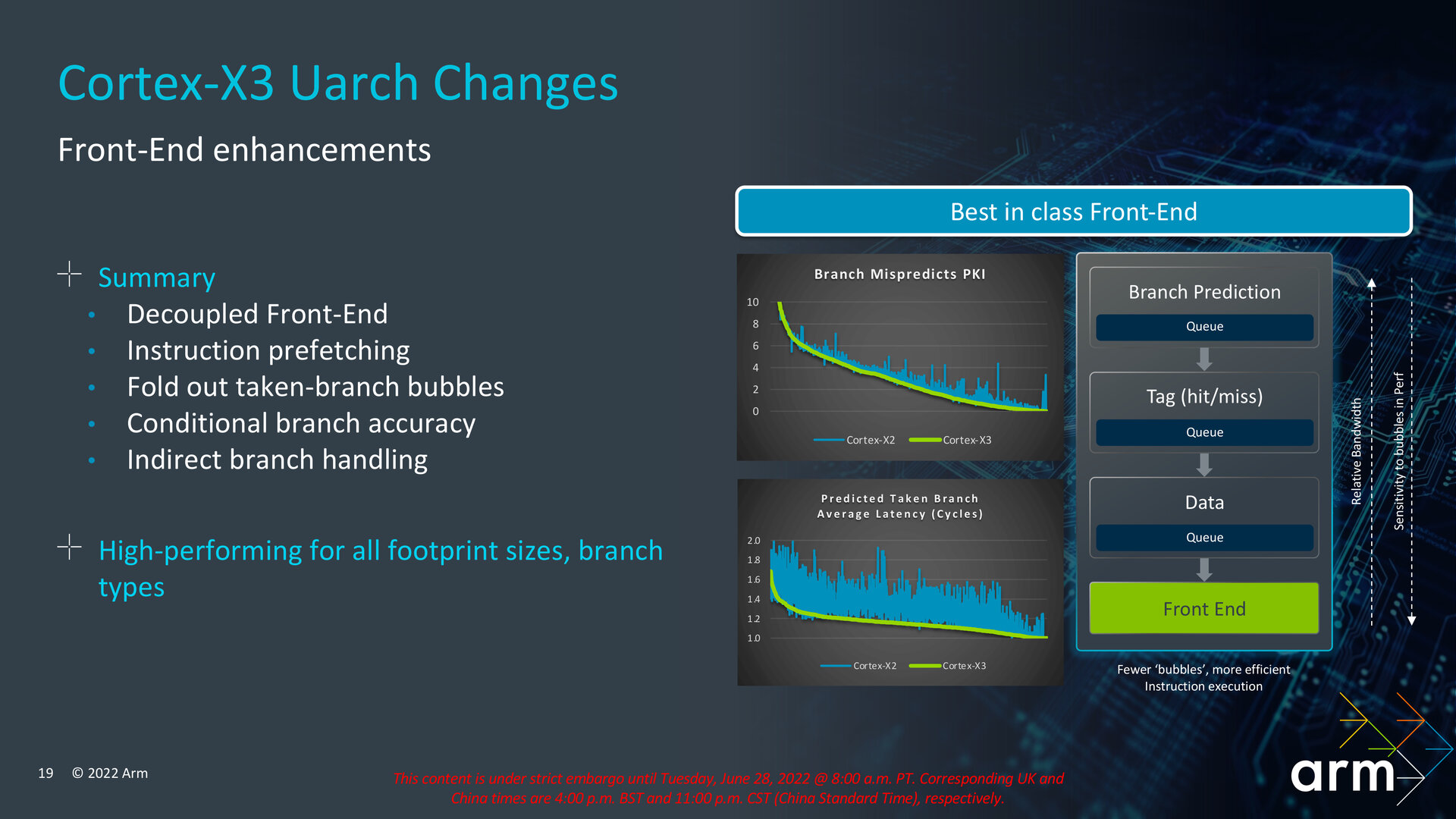
Front-End erhält die meisten Veränderungen
Im Vergleich zum Cortex-X2 ist der Cortex-X3 ein Design mit vor allem Front-End-lastigen Optimierungen, wie Arm erklärt. Der Kern bringt aber in allen Bereichen der Mikroarchitektur Veränderungen und Optimierungen mit, die somit auch den Out-of-Order-Core und das Back-End betreffen. Der Cortex-X3 ist ein reiner Performance-Kern und entsprechend umfangreich wurde die Neuauflage dahingehend optimiert. Arm hat zum Beispiel im Bereich der Sprungvorhersage bei Genauigkeit und Latenz nachgelegt, im Front-End soll es zu weniger Leerläufen (Bubbles) kommen, Tiefe und Breite des Cores haben zugelegt und beim Prefetching wurden Abdeckung und Genauigkeit verbessert.
Arm bohrt „Branch Target Buffer“ auf
Die meisten Veränderungen hat dabei das Front-End erfahren, das bei einem Prozessor für die Sprungvorhersage, das Fetching aus dem Speicher und das Decoding zuständig ist. Dabei nutzt der Cortex-X3 abermals ein Front-End mit voneinander entkoppelter Sprungvorhersage und Fetch-Stufe, ein sogenanntes „Decoupled Front-End“, das auch schon der Cortex-X2 besaß und das effizienter laufen sowie zu weniger Bubbles führen soll. Arm setzt auf durch die Bank größere Kapazitäten für die „Branch Target Buffer“ (BTB), um Leerläufe zu unterbinden und größere Instruktionen zu prefetchen. Für den L1- und L2-Cache wurden die BTBs um 50 Prozent vergrößert, für den L0 sogar um den Faktor 10. Arm erreicht zudem eine größere Tiefe beim Fetching und kann damit Cache-Misses im „L1 Instruction Cache“, also wenn angeforderte Daten nicht im Cache gefunden werden, sodass auf die vorherigen Cache-Ebenen oder gar den deutlich langsameren RAM gewechselt werden muss, bei größeren Instruktionen praktisch verstecken.
-
 Front-End des Cortex-X3 (Bild: Arm)
Front-End des Cortex-X3 (Bild: Arm)
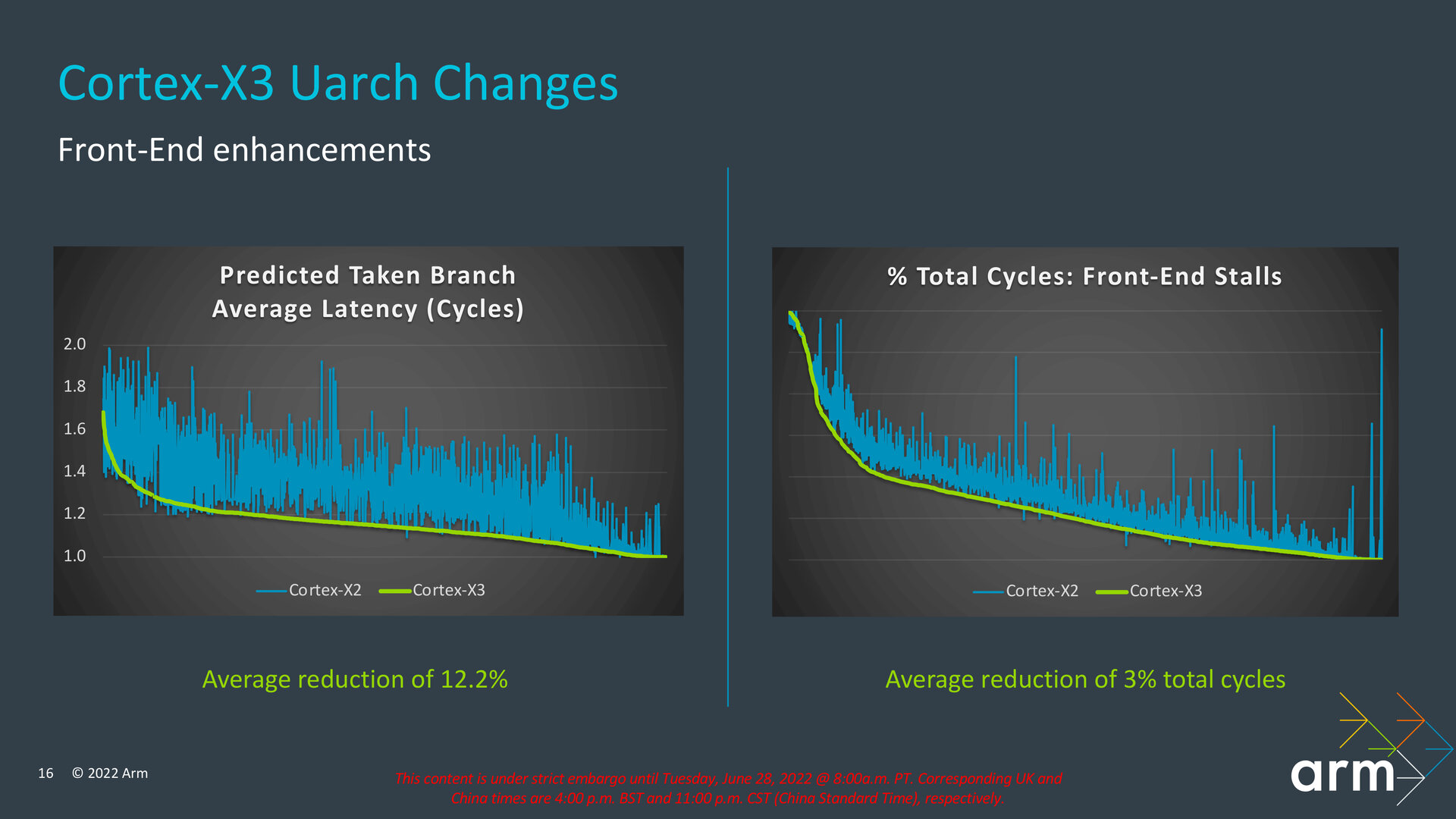
Die Latenz für jeden genommenen Sprung gibt Arm zwar nicht preis, nennt für den Cortex-X3 aber eine durchschnittliche Verringerung der Verzögerung um 12,2 Prozent gegenüber dem Cortex-X2. Keine exakten Angaben macht das Unternehmen auch für den prozentualen Anteil der Verzögerungen (Stalls) im Front-End gemessen an allen Durchläufen, die vom Takt abhängig sind. Daten wandern in einem Prozessor von einer Stufe in die nächste mit jedem abgeschlossenen Takt. Bei beispielhaft 3,3 GHz benötigt jede Stufe 0,3 Milliardstel einer Sekunde für diesen Vorgang. Arm gibt für die Front-End-Stalls eine Reduzierung um durchschnittlich 3 Prozent aller vollständigen Durchläufe an.
Neuer Prädiktor für Indirect Branches
Für die Sprungvorhersage beherrscht das Front-End einen neuen Prädiktor, der explizit für sogenannte Indirect Branches implementiert wurde, um deren Latenz und Genauigkeit zu steigern. Während Direct Branches die Zieladresse für den Sprung in der Instruktion beinhalten, liefern Indirect Branches einen Zeiger auf eine Speicheradresse, die wiederum die Zieladresse des Sprungs beinhaltet. Darüber hinaus soll es allgemeine Verbesserungen für die Genauigkeit von bedingten Branches geben, die in Abhängigkeit zu einer Kondition ausgeführt oder eben nicht ausgeführt werden. Für bedingte direkte Branches, die den BTB verpassen, sei ebenfalls die Genauigkeit gesteigert worden, erklärt Arm. Im Return-Stack der Sprungvorhersage kann der Cortex-X3 im Vergleich zum Cortex-X2 jetzt doppelt so viele und damit 32 Einträge hinterlegen. Die falsche Sprungvorhersage hat Arm mit all diesen Maßnahmen um 6,1 Prozent bezogen auf 1.000 Instruktionen (PKI) gegenüber dem älteren Cortex-X2 vermindert.
-
 Front-End des Cortex-X3 (Bild: Arm)
Front-End des Cortex-X3 (Bild: Arm)

Mop-Cache in der Größe halbiert
Von der optimierten Sprungvorhersage geht es im überarbeiteten Front-End weiter zum Fetching, dessen Mop-Cache für bereits decodierte Instruktionen jetzt nur noch bei 1.500 Einträgen und somit 50 Prozent der Kapazität eines Cortex-X1 und Cortex-X2 liegt. Damit hat der Mop-Cache jetzt wieder die Größe zur erstmaligen Einführung mit dem Cortex-A77 und erreicht eine verbesserte Energieeffizienz. Gegenüber dem Cortex-X2 wurde die Pipeline im Bereich des Mop-Cache-Fetchings um eine Stufe gekürzt, sodass sie jetzt bei neun liegt. Pro Takt erhält der Mop-Cache des Cortex-X3 acht Macro-Ops und reduziert die Latenz bei einer falschen Sprungvorhersage von zehn auf neun Taktzyklen.
Execution-Core wächst in der Breite
Mit dem Out-of-Order-Execution-Core geht Arm mit dieser Generation hingegen in die Breite und setzt auf sechs anstelle von fünf Decodern, deren Verbreiterung um 20 Prozent vor allem bei großen Instruktionen von Vorteil sein soll, die nicht in den Mop-Cache passen. An Breite gewinnen auch die Integer-Einheiten mit jetzt vier anstelle von zwei Single-Cycle-ALUs, während die Multi-Cycle-ALUs mit mehreren Taktzyklen pro Durchlauf bei zwei verbleiben. Hinzu kommt ein größerer Reorder-Buffer (ROB) für 320 × 2 Instruktionen, um Informationen über die ursprüngliche Reihenfolge der Macro-Ops eines Programmablaufs zu speichern, bevor es zur Out-of-Order-Ausführung im Kern kam.

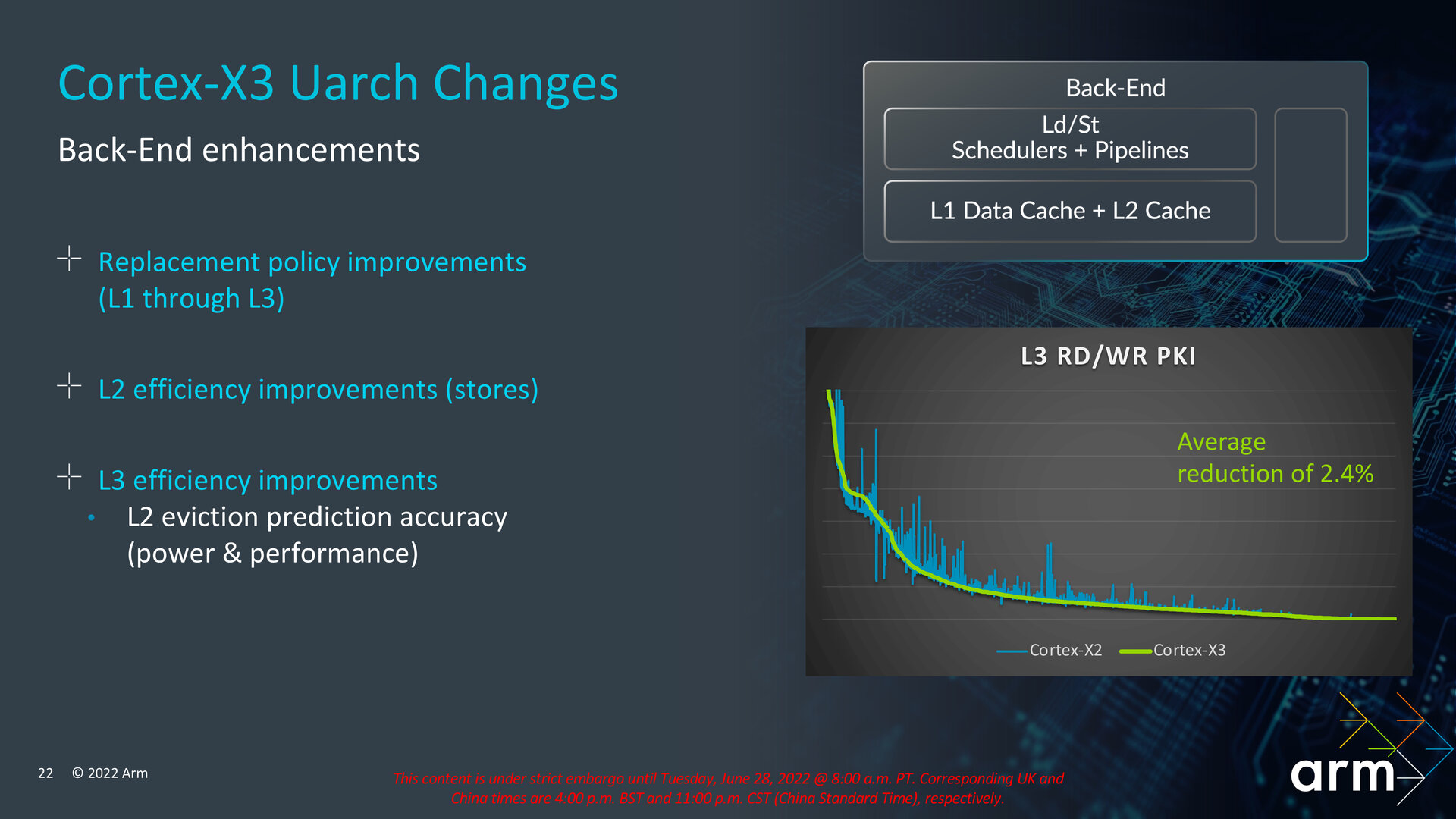
Back-End ist schneller und sparsamer
Im Back-End gibt es eine Handvoll kleinerer Anpassungen wie eine auf 32 Bit angehobene Bandbreite für Integer-Instruktionen in den Load-Einheiten. Das Out-of-Order-Fenster wächst um bis zu 25 Prozent und es liegen zusätzliche Prefetch-Engines für Spatial, Pointer und Indirect vor. Von einer gesteigerten Genauigkeit beim Prefetching sollen Verbrauch und Leistung profitieren. Arm nennt zudem Verbesserungen der Cache-Algorithmen von L1 bis L3 sowie eine höhere Effizienz für Stores im L2-Cache und allgemeine Optimierungen für den L3. Die Anzahl der notwendigen Read-/Write-Vorgänge im L3-Cache habe Arm um durchschnittlich 2,4 Prozent pro 1.000 Instruktionen reduzieren können, was Leistung und Energieverbrauch zugutekommen soll.
-
 Back-End des Cortex-X3 (Bild: Arm)
Back-End des Cortex-X3 (Bild: Arm)
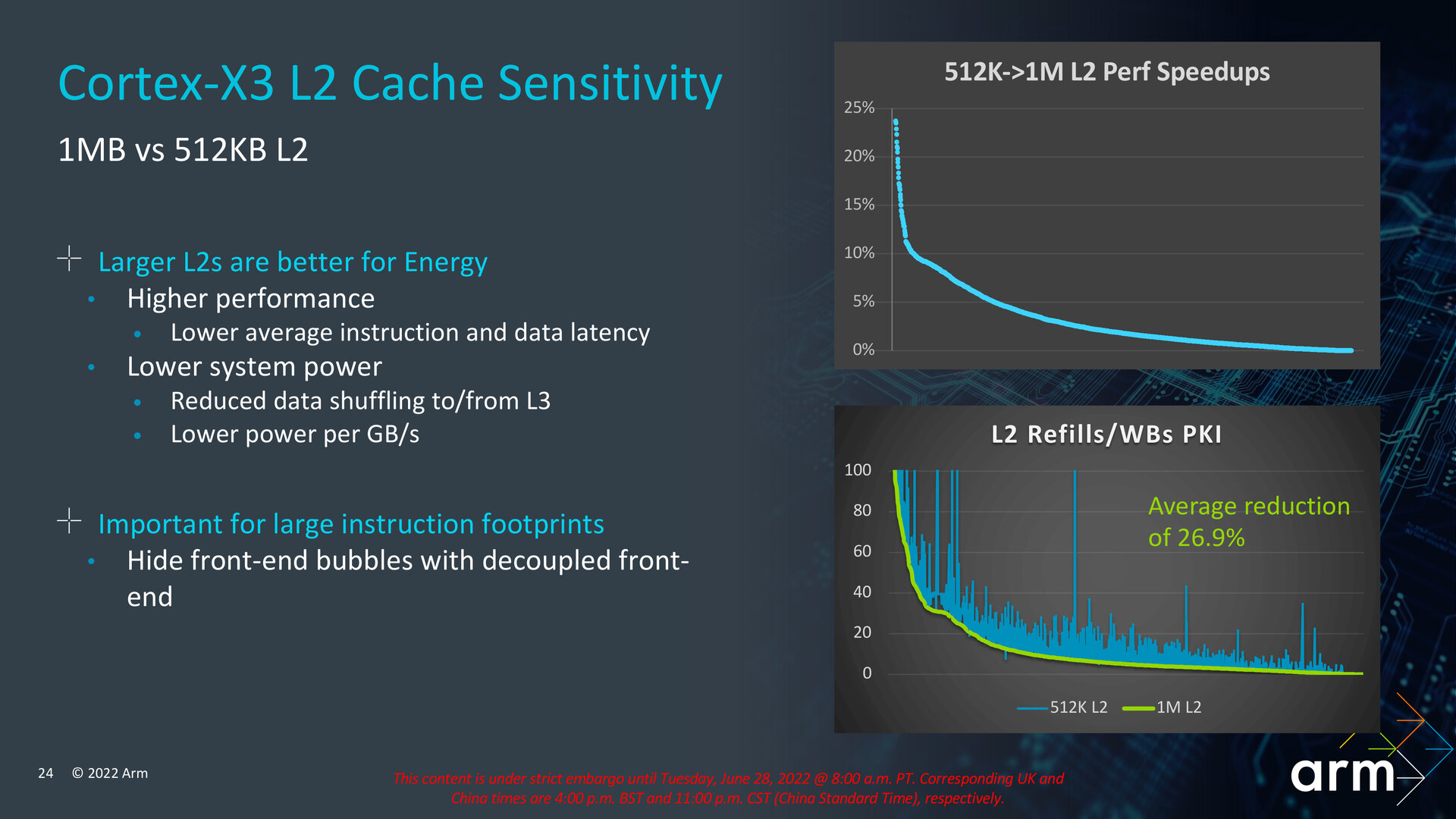
Arm rät zu 1 MB L2-Cache
Der Cortex-X3 kann je nach Wunsch eines Chip-Herstellers mit 512 KB oder 1 MB L2-Cache konfiguriert werden. Arm sieht obgleich des größeren Platzbedarfs auf dem Die und der damit verbundenen höheren Kosten allerdings die Vorteile von 1 MB überwiegen. Dazu zählen mehr Leistung durch reduzierte Latenzen und ein verringerter Verbrauch, weil weniger Daten hin und her geschoben werden müssen. High-End-SoCs bekannter Hersteller dürften ohnehin wieder auf die größere Implementierung mit 1 MB setzen.