Large Language Models und Chatbots: Die Technologie hinter ChatGPT, Bing-Chat und Google Bard

KI-gestützte Chatbots wie ChatGPT, Bard und Bing Chat sind in aller Munde: Künstliche Intelligenz hat den Massenmarkt erreicht. Allen diesen Modellen liegen sogenannte (Large) Language-Models – zu Deutsch „Sprachmodelle“ – zugrunde. ComputerBase erklärt, wie sie funktionieren.
Eine Übersicht
Künstliche Intelligenz ist ein gigantisches Fachgebiet mit abertausenden wissenschaftlichen Publikationen jedes Jahr. Viele Fachbegriffe entstammen anderen Bereichen wie der Statistik, Mathematik, Physik oder Informatik – in diesem Artikel werden daher alle Begriffe in ihrem Kontext eingeführt. Da es sich um einen Grundlagenartikel handelt, werden manche Aspekte zwecks Verständlichkeit vereinfacht und kein vorheriges Wissen vorausgesetzt. Zugleich ist der Umfang des Artikels bewusst auf Language-Models und Chatbots limitiert. Einige Abstecher in andere Themenbereiche sind allerdings unvermeidbar.
Language-Models lernen natürliche Sprache
Sämtliche KI-basierte Chatbots nutzen unter der Haube ein sogenanntes Language-Model. Bei modernen Language-Models handelt es sich um statistische Modelle, die natürliche Sprachen wie Deutsch oder Englisch modellieren. Grundsätzlich lassen sich diese Modelle in zwei Teile aufspalten: Architektur und Parameter. Die Architektur eines Modells ist genau das: Ein hohles Gerüst, das genau definiert, wie das Modell aussieht und in welcher Reihenfolge welche Operationen ausgeführt werden sollen. Die Parameter (auch Gewichte genannt) eines Modells enthalten das Wissen eines Modells. Sie bestimmen darüber, wie stark unterschiedliche Eingaben gewichtet werden sollen und wie sie interagieren. Das Präfix „Large“ wird in der Literatur üblicherweise hinzugefügt, um darauf hinzudeuten, dass das Modell über eine große Anzahl an Parametern verfügt – diese machen die Modelle ausdrucksstärker. Das bedeutet, sie können prinzipiell leichter oder schneller komplexe sprachliche Beziehungen und Bedeutungen lernen.
Deep Learning
Das Stichwort „Lernen“ zeigt den Bezug zum Feld des „Deep Learning“ auf. Deep Learning lässt sich vereinfacht so beschreiben: Nachdem die Architektur eines Modells definiert wurde, werden die Gewichte des Modells mit zufälligen Zahlen gefüllt und eine Eingabe (dazu später mehr) nach der anderen durch das Modell – in der von der Architektur vorgegebenen Reihenfolge – geschickt. Am Ende des Modells wird eine Ausgabe berechnet und mit einer Ausgabe verglichen, die idealerweise hätte produziert werden sollen. Da die Gewichte mit zufälligen Zahlen initialisiert wurden, ist es sehr unwahrscheinlich, dass die korrekte Ausgabe produziert wurde. Hier kommt das „Learning“ ins Spiel: Anhand einer vordefinierten Funktion kann der Fehler (die „Abweichung“) zwischen produzierter und gewollter Ausgabe berechnet und die Gewichte des Modells so angepasst werden, dass es nächstes Mal bei der gleichen Eingabe wahrscheinlich die richtige Lösung produziert.
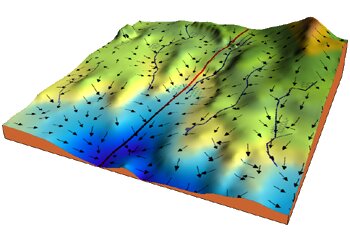
In der Praxis wird dafür üblicherweise ein Algorithmus namens „Gradient Descent“ (Gradientenverfahren) eingesetzt. Diesen kann man sich vereinfacht so vorstellen, dass er von einem Berg den schnellsten Weg ins Tal findet, indem er vom aktuellen Punkt aus immer die Richtung mit dem steilsten Abstieg (Gradienten) findet und dann einen kleinen Schritt in diese Richtung macht. Mit jedem Schritt kommt man dem Tal ein kleines Stück näher. Deep Learning wendet diese Technik auf die Fehlerfunktion an, indem es kleine Anpassungen bei den Parametern eines Modells vornimmt, um ein Tal mit niedrigem Fehler zu finden. Das Training eines Modells besteht darin, die Fehlerfunktion über einen vorgegebenen Datensatz (die Trainingsdaten) zu minimieren: Jeder Datenpunkt des Datensatzes wird durch das Modell gespeist, der Fehler bezüglich der gewollten Ausgabe berechnet und die Gewichte entsprechend angepasst.
Der häufig in Deep-Learning-Papieren erwähnte Fachbegriff „Learning Rate“ bezeichnet die Größe eines Schrittes, das heißt, wie weit man dem lokalen Gradienten folgen möchte. Das ist wichtig, weil Fehlerfunktionen von Deep-Learning-Modellen viele Täler haben und manche besser sind als andere. Wer immer große Schritte macht, könnte über ein gutes Tal hinwegschreiten. Wer zu kleine Schritte macht, könnte in einem schlechten Tal hängen bleiben. Zusätzlich gibt es weitere Tricks wie Momentum (Schwung), die dafür sorgen, dass diejenigen, die lange in die gleiche Richtung laufen, Geschwindigkeit aufbauen (wie ein Ball, der einen Berg hinunterrollt) und so schneller ans Ziel kommen.
Vom Text zur Eingabe
Im Inneren eines Language-Models arbeiten diese mit Zahlen, sie sollen aber natürliche Sprache – also Wörter, Sätze, Dokumente – verarbeiten. Auf dem Weg vom Text zur Eingabe in ein Language-Model finden mehrere Schritte statt, um die Sprache dem Modell verdaulich zu machen. Zuerst wird eine Technik namens Tokenization (Tokenisierung) angewandt, um einen Satz in seine Bestandteile (Tokens) zu zerlegen. Für einen Menschen, der Deutsch oder Englisch spricht, wären die Bestandteile eines Satzes üblicherweise Wörter. Für Language-Models ist das nicht ideal, da ein Bestandteil der Tokenization ist, ein Vokabular (also die Menge der Tokens, die das Modell kennt) zu definieren.
Das Vokabular wird notwendigerweise über die Trainingsdaten definiert – wenn man nun einfach alle Wörter nehmen würde, die in den Trainingsdaten enthalten sind, dann würde das Modell früher oder später bei der tatsächlichen Benutzung auf ein Wort stoßen, das nicht im Vokabular ist. Um das zu vermeiden, lässt sich das Vokabular als das Alphabet definieren. Die Rechenleistung, die ein Modell benötigt, um eine Ausgabe zu produzieren, aber von der Länge der Eingabe abhängt, würde drastisch ansteigen, wenn jeder Satz in seine Buchstaben zerlegt würde. Die meisten Language-Models nutzen daher sogenannte „Subword Tokenization“ wie „Byte Pair Encoding“ oder „SentencePiece“ – das sind Algorithmen, die ebenfalls auf den Trainingsdaten trainiert werden und Regeln lernen, um seltene Wörter in kleinere Bestandteile zu zerlegen. Das erlaubt Subword-Tokenizern, Sätze in möglichst kurze Sequenzen von Tokens zu zerlegen und zugleich ungesehene Wörter tokenisieren zu können. Beispielsweise könnte der Satz „Ich habe eine neue GPU!“ in die Tokens [„Ich“, „habe“, „eine“, „neue“, „GP“, „##U“] tokenisiert werden, wobei die beiden Rauten anzeigen, dass ein Token ein vorhergehendes fortführt.
Um nun einen Satz in ein Language-Model zu geben, wird dieser zuerst tokenisiert und die Tokens dann anhand einer Tabelle (da das Vokabular fixiert ist, kann jedem Token des Vokabulars eine Reihe der Tabelle fest zugeordnet werden) in eine numerische Repräsentation (jedes Token wird ein Vektor, also eine Liste an Zahlen) umgewandelt. Die numerischen Repräsentationen sind Parameter des Modells, sie werden also zu Beginn eines Trainings zufällig initialisiert und dann über den Trainingsprozess hinweg angepasst, um die Fehlerfunktion zu minimieren.
Der geniale Trick
Bisher wurde mehrfach erwähnt, dass eine Fehlerfunktion zwischen der tatsächlichen und einer gewünschten Ausgabe eines Modells einen Fehler berechnet. Doch wo die gewünschte Ausgabe herkommt, wurde nicht erklärt. Das Problem ist, dass das Beschaffen solcher Labels (gewollte Ausgaben) sehr teuer und zeitintensiv ist. Um Sprache zu lernen, kann man sich aber eines einfachen Tricks bedienen: Anhand einer Sequenz von Tokens sagt das Modell das nächste Token voraus. Da in den Trainingsdaten die vollständige Sequenz vorhanden ist, ist das nächste Token also bekannt und die Fehlerfunktion zwischen vorhergesagtem nächsten Token und tatsächlichem nächsten Token lässt sich ohne Probleme berechnen.
In der Praxis gibt das Modell einen Vektor (eine Liste von Zahlen) aus, der die gleiche Länge wie das Vokabular des Modells hat. Dieser Vektor enthält manche höhere und manche kleinere Zahlen und wird in eine Wahrscheinlichkeitsverteilung umgewandelt (das heißt, die Summe aller Zahlen des neuen Vektors ist 1) und die Fehlerfunktion zwischen dieser Verteilung und dem Label berechnet. Das Label wird dabei in einen sogenannten One-Hot-Vektor umgewandelt – das ist nichts anderes als ein weiterer Vektor, der überall 0 ist – außer in einer einzigen Zeile (die dem entsprechenden Token entspricht, die der Vektor darstellt). Die Parameter des Modells werden dann mittels „Gradient Descent“ angepasst, um die Wahrscheinlichkeit des korrekten Tokens in der Ausgabe des Modells anzuheben und alle anderen Wahrscheinlichkeiten abzusenken.
Wie trainierte Modelle Sprache generieren
Bisher wurde das Training eines Language-Models beschrieben – nach dem Training stellt sich jedoch ein weiteres Problem: Wie kann ein nun trainiertes Modell Sprache generieren, also beispielswise Nutzern antworten? Zur Erinnerung: Ein Language-Model modelliert die Wahrscheinlichkeiten für das nächste Token auf Basis der bisherigen Tokens eines Satzes. Um nun ein trainiertes Modell dazu zu bewegen, eine Ausgabe zu produzieren, kann eine initiale Eingabe in das Modell gegeben und dann die Wahrscheinlichkeiten für das nächste Token berechnet werden. Nun bestehen verschiedene Möglichkeiten, aber eine einfache Methode ist, das Token mit der höchsten Wahrscheinlichkeit zu wählen und an die Eingabe heranzuhängen. Mit dieser überarbeiteten Eingabe, die nun ein Token länger ist als zuvor, wird das Modell nach den Wahrscheinlichkeiten für das nächste Token gefragt. Dieser Prozess wird so lange wiederholt, bis entweder eine vorgegebene Länge erreicht oder ein spezielles Stop-Token generiert wird (als vereinfachtes Beispiel kann man sich ein Satzendzeichen wie einen Punkt oder Ausrufezeichen vorstellen). Diese Technik wird „autoregressive Generation“ genannt, da die Ausgabe des Modells immer wieder als Eingabe in das gleiche Modell genutzt wird.
Arten von Language-Models
Was bisher beschrieben wurde, sind sogenannte Left-to-Right-Language-Models (also links nach rechts), die so heißen, weil Sprachen als Sequenzen von Tokens beschrieben werden, die von Satzanfang bis Satzende Schritt für Schritt generiert/modelliert werden. In der Literatur gibt es weitere Arten von Language-Models, die gegebenenfalls in beide Richtungen modellieren (bidirektional). Das ist beispielsweise bei Machine-Translation (maschineller Übersetzung) wichtig: Hier wird ein Eingabesatz in der Ursprungssprache erst verarbeitet und dann autoregressiv die Ausgabe in der Ausgabesprache generiert. Die Tokens sollten aber nicht einfach stumpf übersetzt werden, sondern müssen eventuell ihre Reihenfolge verändern. Zum Beispiel der Satz „Where can I find the supermarket?“ würde mit naiver Übersetzung zu „Wo kann ich finden den Supermarkt?“ statt des korrekten „Wo kann ich den Supermarkt finden?“.
Die Art des Language-Models macht sich in der Architektur bemerkbar. Prinzipiell wird zwischen Encoder-, Encoder-Decoder- und Decoder-Modellen unterschieden. Ein Encoder-Modell nimmt eine Eingabe und verarbeitet sie bidirektional und gibt am Ende aktualisierte Vektoren für jedes Token aus – diese können dann beispielsweise für Klassifikation genutzt werden (etwa für jedes Token, ob es ein Adjektiv, Adverb oder Substantiv ist). Decoder-Modelle hingegen sind für Textgenerierung geeignet, sie entsprechen den zuvor beschriebenen Modellen, die ein Token nach dem anderen produzieren. Encoder-Decoder-Modelle kombinieren beide Ansätze und entsprechen dem vorherigen Beispiel der maschinellen Übersetzung – sie nehmen eine Eingabe, verarbeiten sie mit einem Encoder, um neue Vektoren zu erhalten, und nutzen diese neuen Vektoren als Kontext für einen Decoder, um eine Ausgabe zu generieren.
Die namensgebenden Transformer
Im Namen des populären Chatbots ChatGPT steckt „GPT“, kurz für „Generative Pre-trained Transformer“. Transformer sind ein integraler Bestandteil quasi aller modernen Language-Models. Dabei handelt es sich um eine Encoder-Decoder-Architektur, die 2017 in dem Papier Attention is all you need vorgestellt wurde. Je nach Modell werden entweder nur Transformer-Encoder-Blöcke (beispielsweise BERT), Transformer-Decoder-Blöcke (zum Beispiel GPT) oder beide (wie bei T5) verwendet.
Konzeptuell sind Transformer ziemlich einfach: Eine Sequenz von Vektoren (die die Eingabe darstellen) wird zu drei verschiedenen Sequenzen von Vektoren transformiert: Queries (Anfragen), Keys (Schlüssel) und Values (Werte). Zwischen jedem Paar von Tokens wird nun ein sogenannter Attention-Score berechnet, indem die entsprechenden Query- und Key-Vektoren miteinander multipliziert werden, woraus sich eine einzelne Zahl ergibt. Nun ergibt sich für jedes Token eine Liste mit Attention-Scores bezogen auf alle anderen Tokens, die nun normalisiert (sodass sich die Liste auf 1 summiert) werden kann. Für ein gegebenes Token spiegelt jeder dieser normalisierten Attention-Scores nun wider, wie wichtig die entsprechenden anderen Tokens für dieses Token sind. Der Vektor des Tokens wird dann aktualisiert, indem die Attention-Scores mit den zugehörigen Value-Vektoren multipliziert und aufsummiert werden. Intuitiv bedeutet das, dass der Vektor eines Token jetzt nicht mehr nur widerspiegelt, welches Token er repräsentiert, sondern auch den Kontext (die anderen Tokens der gleichen Sequenz), in dem das Token vorkam. Beispielsweise kann ein Modell so zwischen dem Wort „Bank“ in den Sätzen „Ich sitze auf der Bank“ und „Ich muss zur Bank“ unterscheiden.
Vom Language-Model zum Chatbot
Spätestens seit OpenAIs ChatGPT und darauf folgend Googles Bard und Microsofts Bing Chat sind Chatbots in aller Munde. Während moderne Chatbots auf Language-Models basieren, sind sie nicht strikt identisch. Zum einen werden Chatbots üblicherweise auf – zumindest teilweise – anderen Daten (Chatprotokollen) trainiert und zum anderen ein größerer Fokus auf Faktualität und Unbedenklichkeit der Ausgaben gelegt. Dafür werden manche Chatbots wie Googles LaMDA (auf dem Bard basiert) beispielsweise mit Zugang zu externen Datenbanken wie Wikipedia ausgestattet, die sie durchsuchen können, um Fakten zu finden. Perfekt sind die Modelle trotz dieser Fähigkeiten nicht, wie sowohl Googles Bard als auch Microsofts Bing Chat mehrfach mit ausgedachten Fakten bewiesen. Auch innerhalb der KI-Branche stoßen Chatbots und Language-Models dafür auf Kritik, so unter anderem seitens Metas Chief-AI-Scientist und Turing-Award-Gewinner Yann LeCun.
LLMs are still making sh*t up.
— Yann LeCun (@ylecun) January 22, 2023
That's fine if you use them as writing assistants.
Not good as question answerers, search engines, etc.
RLHF merely mitigates the most frequent mistakes without actually fixing the problem. https://t.co/XnDxF8Q9Zr
Zuletzt besitzen Chatbots eine fundamentale Eigenschaft, die normale Language-Models nicht aufweisen: Sie haben ein „Gedächtnis“. Bei der Benutzung eines Chatbots muss dieser notwendigerweise die bisherige Interaktion im Hinterkopf behalten, um sinnvolle Antworten auf Folgefragen zu generieren. Language-Models hingegen haben diese Beschränkung nicht, da sie nicht speziell für Dialoge entwickelt werden. In der Praxis wird diese Dialogfähigkeit in Chatbots über Tricks in die unterliegenden Language-Models implementiert. Aus Gründen der Rechenleistung (und/oder des Speicherbedarfs) besitzen alle Language-Models eine maximale Kontextgröße, also wie viele Tokens sie als Eingaben und Ausgaben verarbeiten können. Um einem Language-Model zu erlauben, sich an bisherige Dialoge zu erinnern, werden diese einfach bis (nahe) zur maximalen Kontextlänge vor der Eingabe des Nutzers angehangen. Bei ChatGPT sind das beispielsweise die letzten 4.000 Tokens der Konversation. Somit kann das Modell die Ausgabe davon abhängig machen, was es selbst und der Nutzer zuvor geschrieben haben. Über lange Dialoge hinweg verlieren aktuelle Chatbots allerdings dementsprechend den Bezug zum vorher Gesagten, weil nicht mehr alle Tokens in die Kontextlänge passen.
Ein Blick in die Zukunft
In den nächsten Jahren werden Language-Models und Chatbots immer fähiger werden. Auf einem technischem Level bedeutet das, dass die Modelle sich an längere Dialoge erinnern und zuverlässig Referenzen für Fakten geben werden können. Die wichtigere und weit weniger absehbare Entwicklung wird die Gesellschaft durchgehen in Bezug darauf, wie diese Technologien sicher und effizient genutzt werden können. Auch Urheberfragen bezüglich Texten, die von Language-Models produziert wurden, werden sich vermehrt stellen.
Dieser Artikel war interessant, hilfreich oder beides? Die Redaktion freut sich über jede Unterstützung durch ComputerBase Pro und deaktivierte Werbeblocker. Mehr zum Thema Anzeigen auf ComputerBase.
- Bester Maus- und Tastatur-Hersteller
- Bester PC-Gehäuse-Hersteller
- Bester NAS-Hersteller
- Alle Wahlen im Überblick...