Intel und Nvidia in MLPerf: In AMDs Abwesenheit debütiert H200 und Gaudi2 stichelt

Nvidia und Intel feiern ihre neuen Erfolge im neuen MLPerf-Inference-Benchmark. Viele Partner sind dabei, AMD macht weiterhin nicht mit. Zuletzt hatte das Unternehmen zwar angekündigt, künftig ebenfalls Ergebnisse einzureichen, doch bis dato ist das nicht geschehen. Nvidia dominiert so weiterhin ganz klar das Feld.
MLPerf: Der neue Quasi-Standard
MLCommons hat sich mit den MLPerf-Benchmarks in den letzten drei Jahren nach und nach zu einem Industriestandard hinsichtlich der Einordnung und Klassifizierung der Leistungsfähigkeit von Hardware in modernen AI-Workloads gemausert. Stetige Weiterentwicklungen gepaart mit viel Zuspruch aus der Industrie durch fast alle großen Namen helfen letztlich beiden Seiten.
@MLPerf Inference v4.0 results are out! This round includes two new benchmarks focused on gen AI: @Meta’s Llama 2 70B model and @StableDiffusion XL. See the complete results and learn more: https://t.co/VlUiYqRM1k#GenAI #LLM
— MLCommons (@MLCommons) March 27, 2024
Intel und Nvidia dominieren das Teilnehmerfeld
Voran gehen dabei Intel und Nvidia, ohne deren Hardware es nur wenige Einträge in den neuen Benchmark-Ranglisten geben würde. Zwar machen auch andere wie Chip-Anbieter wie Qualcomm, Google oder Microsoft mit eigener Hardware mit, über die OEMs und ODMs wird jedoch in der Regel die aktuell gängige und vorallem frei verfügbare Hardware verbaut. Partner wie Asus, Lenovo, Supermicro, Dell oder HPE sind es dann, die ihre Systeme dann auf Basis von Intel und Nvidia (& Co) ebenfalls einreichen können, was wiederum die Herstellerangaben untermauert oder mitunter gar noch etwas bessere Ergebnisse bringt. Wenn ein halbes Dutzend Systeme ganz ähnlicher Natur beim Kunden auch die ähnliche Leistung erzielt, ist das für Nvidia und Intel eine weitere positive Botschaft, die in ihren Presseaussendungen nicht nur einmal aufgegriffen wurde.
Platzhirsch Nvidia zeigt Preview von H200
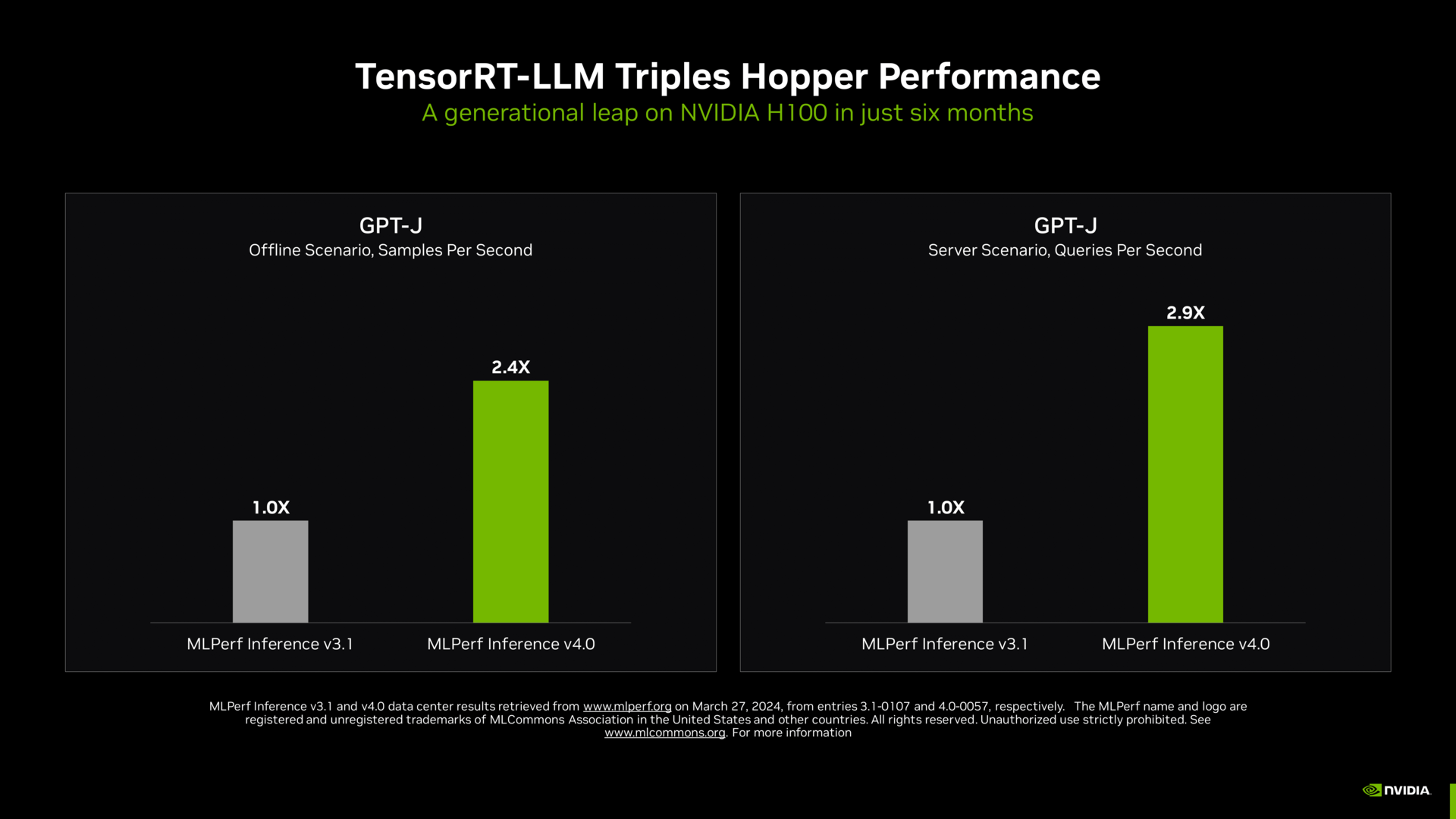
Für Nvidia sind nahezu alle öffentlich nachvollziehbaren Benchmarks im Bereich der GPU-Beschleuniger eine One-Man-Show. Das kostet die Firma natürlich aus, erklärt aber auch stets, dass man nun nicht auf der Stelle stehen bleiben werde. Und so kommt die Leistungssteigerung von H100 in der aktualisierten Version von MLPerf Inference 4.0 auch nicht einfach so daher. Denn in der sich stetig entwickelnden AI-Welt mit immer größeren Szenarien gilt es, auch in Sachen Software stetig am Ball zu bleiben. Nvidia will dies mit den drastischen Leistungssteigerungen im neuen Test verdeutlichen.
Das eigentliche Pfund ist aber der neue H200, der in diesen Tagen ausgeliefert wird und in Kürze von Partnern verfügbar wird. Für viele modernste und größere LLMs und GPTs bringt H200 gegenüber H100 ein deutliches Upgrade. Vor allem der zusätzliche und schnellere Speicher löst Flaschenhälse für gewisse Anwendungen, sodass in der Preview-Version bereits bis zu 45 Prozent mehr Leistung von H200 gegenüber H100 zu sehen ist.
The H200 upgraded GPU memory helps unlock more performance than the H100
on the Llama 2 70B workload in two important ways.
With larger GPU memory capacity, the Llama 2 70B fits in a single H200, rather
than splitting the model across multiple GPUs. This feature eliminates the need for
tensor parallel or pipeline parallel execution, reducing communication overhead and
improving inference throughput.
Second, the H200 GPU features greater memory bandwidth than the H100,
relieving bottlenecks in memory bandwidth-bound portions of the workload,
enabling improved Tensor Core utilization and greater inference throughput.
Nvidia
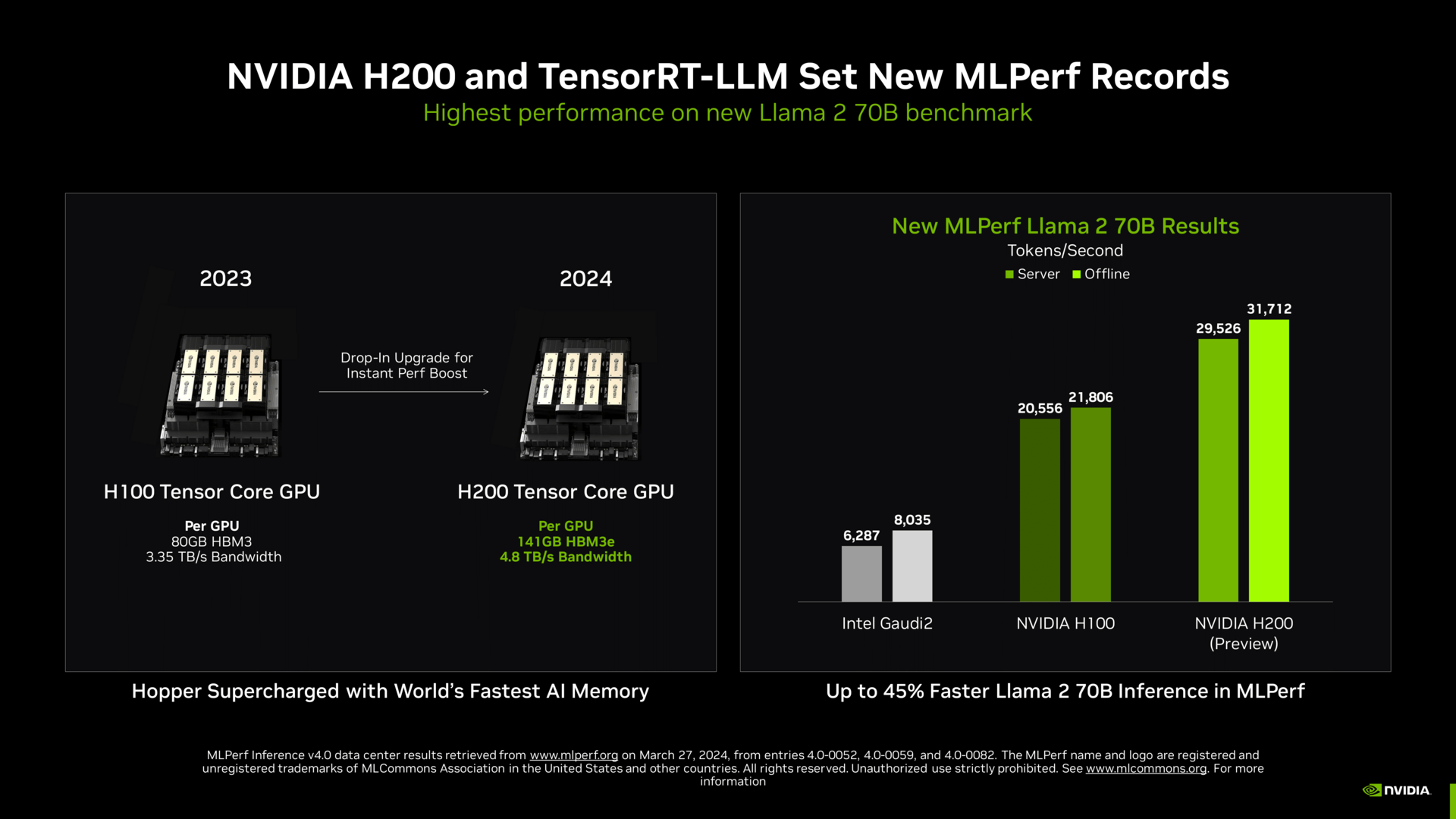
Eine Custom-Kühlungen und dadurch gesteigerter TDP-Spielraum in Partner-Systemen kann allein bis zu 14 Prozent mehr Leistung bringen – in dem Fall im Endergebnis bereits inkludiert. H200 auf gleichem TDP-Level von 700 Watt liefert 28 Prozent mehr Leistung als H100, bei 1.000 Watt mit den erwähnten Anpassungen 45 Prozent mehr Leistung als H100.

Noch ist H200 ein Preview, erklärt Nvidia und verweist dabei auf die Bestimmungen von MLCommons. Das Testergebnis muss dafür rund einen Monat vor öffentlicher Bekanntgabe übermittelt werden, dann können alle Beteiligten an MLCommons dies begutachten und Fragen stellen. Wenngleich Nvidia betont, dass nun finale Hardware, die genau so aussieht, ausgeliefert wird, entstand das Ergebnis noch mit einem „Vorserienmuster“. Als Einsender darf Nvidia diese Werte aber selbst publizieren, das dürfen andere entsprechend ebenfalls. In der kommenden Ausgabe dürfte es vermutlich eine kleine Schwemme an offiziell abgenickten H200-Tests geben. Und das ist nicht alles, auch GH200 ist bereits in ersten Tests nicht nur von Nvidia vertreten.
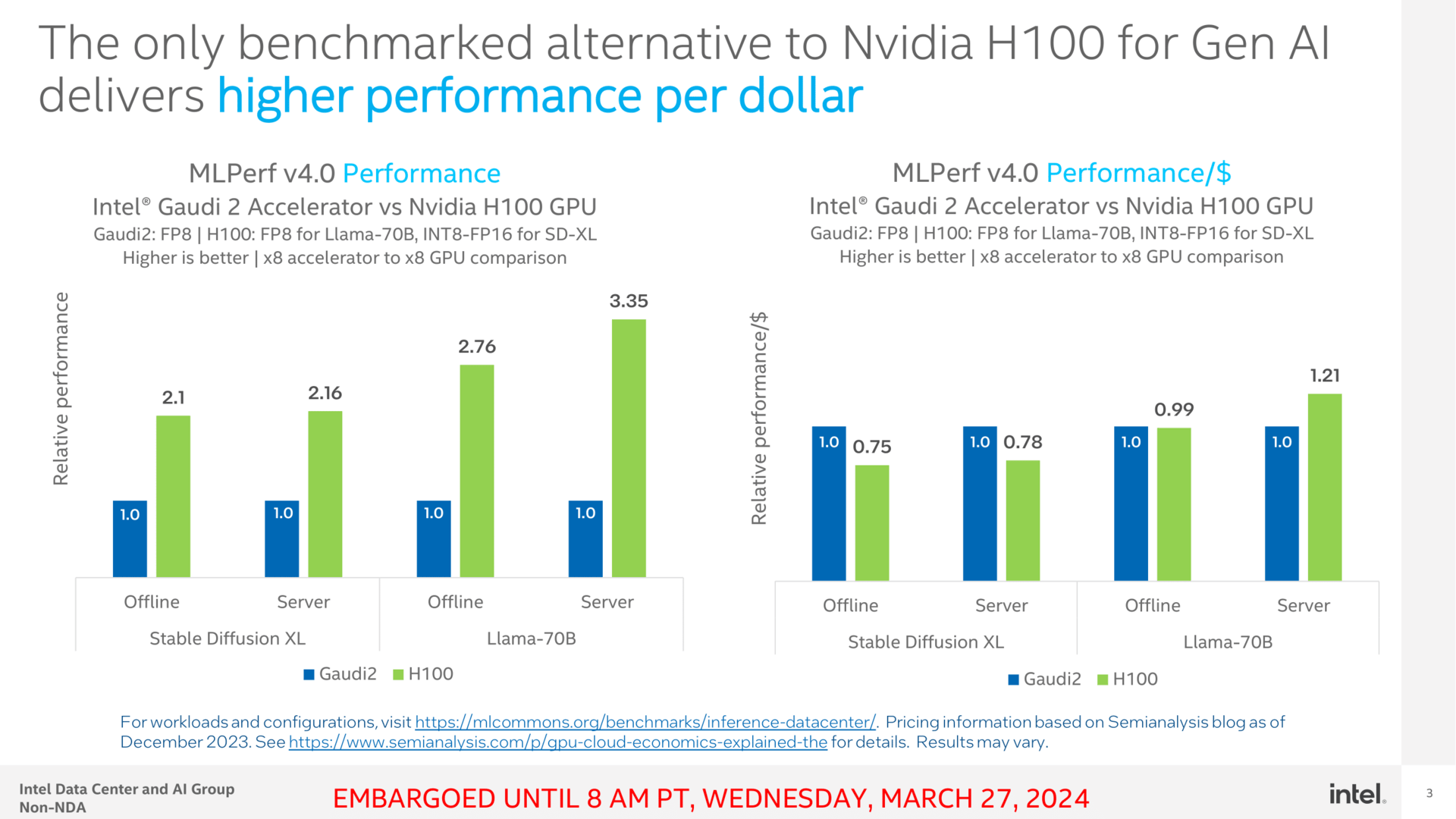
Intel genießt den Platz 2 als einzige getestete Alternative zu Nvidia
Es ist beinahe jedes Quartal kurios, wenn Intel zur unter Embargo abgehaltenen Veranstaltungen im Vorfeld der Veröffentlichung lädt, denn eigentlich erwartet man jedes Jahr ein anderes Unternehmen an dieser Stelle. Aber da AMD weiterhin keine für die Öffentlichkeit bestimmten Ergebnisse publik macht, kostet Intel dies entsprechend aus und verkauft sich als einzige getestete Alternative zu Nvidia – und kann dabei sogar Nvidia noch ein wenig sticheln, wenngleich das eher dem Vergleich Mücke zu Elefant gleichkommt.
Aber genau diese Mücke wird Intel auch weiterhin sein, denn mit Gaudi2 und dessen stetiger Optimierung schafft sich das Unternehmen einen Stand im Markt, der in Zukunft direkt auf Gaudi3 wechseln soll.
The @MLPerf results are in!
— Intel (@intel) March 27, 2024
We’re raising the bar with competitive solutions for your high-performance, high-efficiency deep learning inference needs — even on challenging LLMs. Read more about the results. https://t.co/qsFQ4rWlqT#IntelXeon #IntelGaudi #Intel pic.twitter.com/CuaMBiyvhE
Gaudi2 muss derweil nicht über rohe Leistung, sondern Preis und Performance punkten. Intel sieht sich sich selbst dabei sehr gut aufgestellt, Nvidia relativiert auf Nachfrage etwas und weist darauf hin, dass Total Cost of Overnership (TCO) mehr umfassen als einen Blick auf die naheliegenden Kosten. Nvidia beschreibt diese Komponente mit „versatility“. Soll heißen, dass Hopper vielseitiger einsetzbar, flexibler für neuere Möglichkeiten ist.
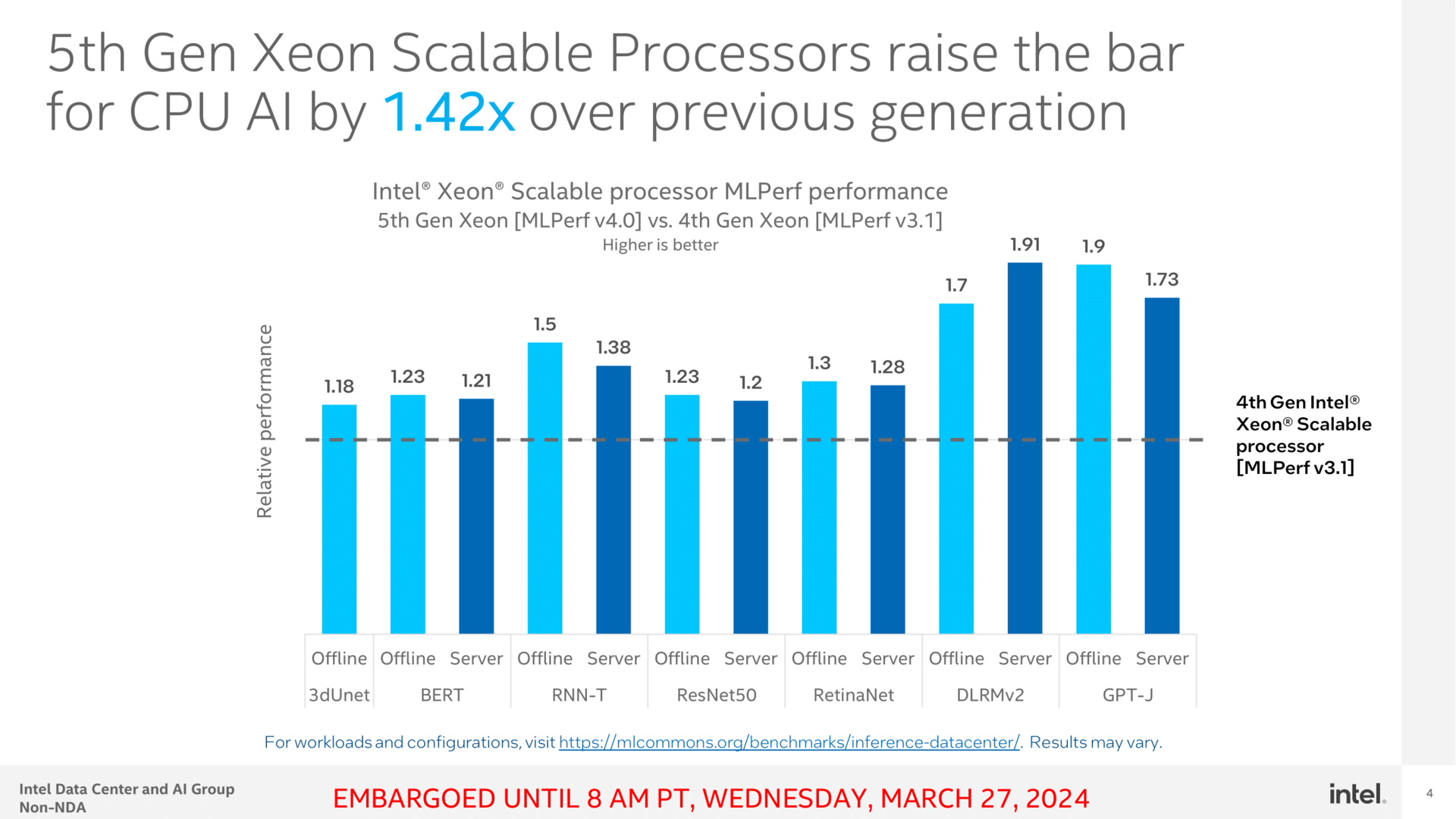
Auch Intels Xeon darf sich in Benchmarks beweisen. AMDs Epyc-CPUs sind zwar auch in den Listen zu finden, dann aber nur als Grundlage für beispielsweise Hopper-Systeme, nicht aber, um selbst getestet zu werden. Und so zeigt Intel bei den CPUs ein solides Wachstum von Sapphire Rapids auf Emerald Rapids, welches zum Teil durch die optimierte Software und zum Teil eben durch das Mehr an Kernen, L3-Cache und Takt realisiert wird. Bis zu 42 Prozent mehr Leistung nur über die CPU sind dennoch alles andere als wenig.
Ohne Zeiteinsatz, Software und Treiber geht nichts
Intel betont wie Nvidia stets, dass die Anpassung und Optimierung durchaus nicht trivial ist und Zeit und Einsatz erfordert. Stolz zeigt der Hersteller deshalb mit jedem neuen Turnus seine Verbesserungen – Nvidia verfährt dabei ganz ähnlich. Beide Unternehmen hatten unabhängig voneinander vorab deshalb erneut zu NDA-Pressebriefings geladen und ihre Fortschritte und Entwicklungen allein in den letzten Monaten dargelegt.
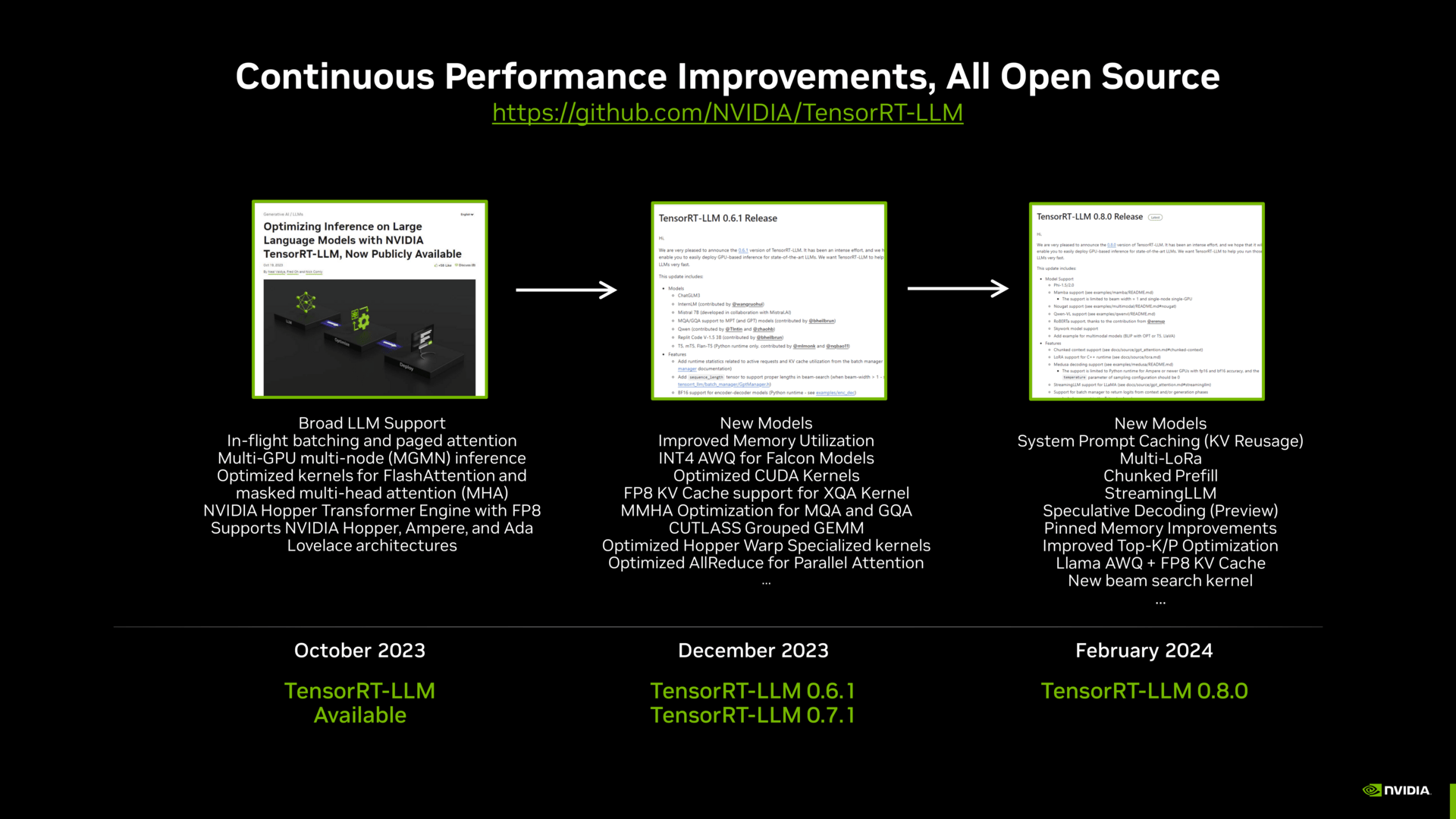
Denn der Wunsch nach einem externen Benchmarks rund um das Thema Machine Learning, Training und Inferencing ist nicht nur bei den Herstellern, sondern auch in der Industrie vorhanden. Denn AI ist zwar in aller Munde, aber greifbar und messbar und dann am Ende auch aussagekräftig sind bisherige Angaben nur für die wenigsten.
Und so bleibt die Neuvorstellung der Werte am Ende auch einmal mehr ein Fingerzeig auf AMD, der es als Hersteller nach wie vor nicht für die Öffentlichkeit genehmigt hat, ältere oder neuere Lösungen hier an den Start zu bringen – auch nicht über Partner. So bereitet AMD damit Intel und Nvidia eine schöne Bühne, diese kosten das auch dementsprechend aus, wie Intel direkt zum Start mit „Intel Gaudi2 Remains Only Benchmarked Alternative to NV H100 for Gen AI Performance“ anmerkt.
Dabei redet AMD zuletzt gern über die verbesserte Software-Suite und stabilere Treiber, verfängt sich dennoch aber weiterhin auch in vielen Problemen und teilweisen Grabenkämpfen, sodass frei zugängliche und nachvollziehbare Ergebnisse für jedermann heute erneut Fehlanzeige bleiben. Dass Partner die Systeme längst haben und auch nutzen, zeigen sie auf Channel-Portalen beispielsweise mit Benchmarks von Supermicro-Systemen mit MI300X.

MLCommons bleibt, B100 und Gaudi3 kommen
Die Benchmarks von MLCommons sind derweil gekommen um zu bleiben. Zu Beginn des Jahres wurde der neue MLPerf Client angekündigt, der fürs Client-Segment angepassten Tests umfassen wird – also Desktop-PC-AI-Benchmarks. Hier wird neben Intel, Nvidia, Arm, Microsoft und Qualcomm auch AMD direkt als Partner genannt.
Nvidia erklärte im Rahmen des Pressegesprächs auch schon an Blackwell-Systemen zu arbeiten und sobald diese fertig sind, entsprechende Benchmarks über MLCommons zu publizieren. Ein genaueres Datum nannte der Hersteller aber auch auf Rückfrage erwartungsgemäß nicht.
Bei Intel wiederum steht Gaudi3 vor der Tür. Zur Frühjahrsmesse Intel Vision 2024 ab 9. April legt Intel den Fokus nicht nur erneut auf das Thema AI, sondern will Partner und Kunden über den Stand bei Gaudi3 informieren und den Start des neuen AI-Beschleunigers vorbereiten. Auch die Presse soll dann entsprechende Details erhalten.
ComputerBase hat Informationen zu diesem Artikel von Intel und Nvidia unter NDA erhalten. Die einzige Vorgabe war der frühestmögliche Veröffentlichungszeitpunkt.