Was ist Hyper-Threading?: Die Grundlagen erklärt
2/4Was ist Hyper-Threading?
Die Idee von Hyper-Threading kommt eigentlich aus dem Serverbereich, wo häufig Rechnersysteme mit mehr als nur einem Prozessor zum Einsatz kommen. Mit zwei Prozessoren ist es z.B. möglich, zwei Threads pro Taktzyklus zu verarbeiten, da jede CPU unabhängig mit Aufgaben beschäftigt werden kann. Wenn eine Anwendung vom Programmierer in mehrere Threads aufgeteilt wurde, lässt sich so die Geschwindigkeit deutlich steigern, wenn nicht sogar nahezu verdoppeln. Insbesondere bei Webserver-Applikation kann man nahezu von einer Verdoppelung der Leistung sprechen.
Die Hyper-Threading Technologie ist hierbei nichts anderes, als die Technik, die dieses simultane Multi-Threading in einem einzigen physikalischen Prozessor (mit Einschränkungen) ermöglicht. Dieser eine Prozessor spaltet sich somit in zwei logische Prozessoren auf, wobei sich die beiden logischen/virtuellen Prozessoren einen Teil der physischen Ausführungs-Ressourcen teilen, wobei die Umsetz-Logik (Architecture State) für jeden Prozessor einzeln und somit doppelt vorhanden ist. Ziel ist es, die vorhanden Ressourcen effektiver auszunutzen.
Was ist neu am Kern?
In der Theorie klingt Hyper-Threading eigentlich recht simpel. Doch was musste Intel nun wirklich dem bisherigen Pentium 4 Prozessorkern hinzufügen, um aus einem physischen Prozessor zwei logische machen zu können? So überraschend die Antwort auch sein mag, aber „hinzufügen“ ist in diesem Zusammenhang eigentlich nicht das richtige Wort. Viel besser wäre die Frage, welche schon immer vorhandenen Ressourcen nun endlich mal aktiviert werden. So verfügt jeder ausgelieferte Pentium 4 mit Northwood-Kern (und vermutlich auch mit Willamette-Kern) über alle nötigen Transistoren, die für Hyper-Threading gebraucht werden. Intel spricht davon, dass 5 Prozent bzw. 2 bis 3 Millionen Transistoren der relativen CPU Bestandteil von Hyper-Threading sind. An der Größe und den Transistoren ändert sich zu den bisherigen Pentium 4 somit nichts.
Eine Übersicht über den Pentium 4 Prozessor-Kern (Northwood) offenbart uns die Regionen, die nun mit Hyper-Threading vom Staub befreit werden und endlich zeigen können, was in ihnen steckt.
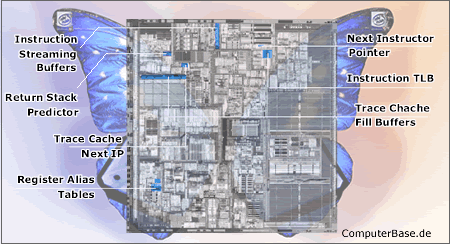
Darüber hinaus besitzt jeder virtuelle Prozessor seinen eigenen Interrupt-Controller (APIC), die Ressourcen wie Trace Cache (TC) / L1-Cache, L2-Cache, Queues und Key-Buffers werden geteilt.
Beim Trace Cache, der decodierte Instuktionen (micro-operations oder µops) enthält, wird, wenn beide virtuellen Prozessoren Zugriff auf den Cache haben möchten, jedem Prozessor abwechselnd mit jedem Takt Zugriff gewährt. Sollte ein virtueller Prozessor aufgrund eines Cache-Miss auf weitere Daten vom Hauptspeicher warten und somit quasi „blockiert“ (stalled) sein, so steht der gesamte Trace Cache dem jeweils 'anderen Prozessor' zur Verfügung. Ähnlich wird auch mit den internen Caches des Prozessors verfahren. Wenn ein virtueller Prozessor also gar nicht genutzt wird, ergibt sich durch die Teilung dieser beiden Ressourcen kein Nachteil.
Anders sieht das jedoch in der Out-Of-Order Execution Engine, hier speziell beim Allocator, aus. So verfügt die Out-of-Order Execution Engine über mehrere Zwischenspeicher zum Wieder-Ordnen (Reorder), Nachverfolgen (Tracing) und Aufteilen (Sequencing) von Operationen. Der Allocator hat die Aufgabe, diesen Zwischenspeicher zu füllen. Der Pentium 4 Northwood-Kern verfügt über 126 Re-Order Buffer Einträge, 128 Integer und 128 Floating-point Physical Register sowie 48 Load und 25 Store Buffer Entries. Ein Teil dieser Buffer wird bei aktivem Hyper-Threading geteilt, so dass jeder virtuelle Prozessor genau die Hälfte der Buffer füllen darf. Dies betrifft die Re-Order, Load uns Store Buffers. Jeder virtuelle Prozessor darf hier maximal 63, 24 bzw. 12 Einträge hinterlassen. Ist das Limit erreicht, wird der Allocator die Ressourcen dem anderen virtuellen Prozessor zuweisen. Sollten sich im Aufgabentopf (µop queue) nur decodierte Instuktionen für einen Prozessor befinden, so wird der Allocator versuchen, für diesen jedem Takt Ressourcen zuzuweisen, die Teilung bleibt jedoch bestehen.
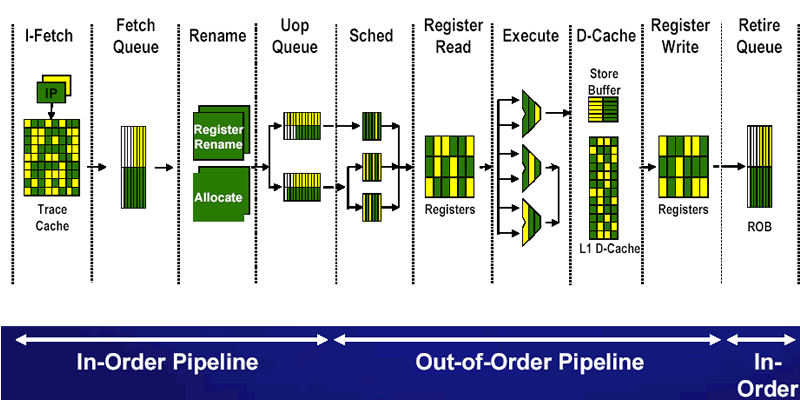
Wenn der Allocator seine Arbeit vollendet hat, landen die µops in zwei weiteren Queues. Diese sind ebenfalls partitioniert und zwar so, dass jeder Prozessor maximal die Hälfte aller Einträge für sich verbuchen kann. Aus diesen beiden Queues (Memory Operation Queue und Genereal Instruction Queue) bedienen sich anschließend die fünf µop Scheduler abwechselnd aus den Topf jedes virtuellen Prozessors, um den Ausführungseinheiten Aufgaben zur Verarbeitung zuzuteilen.