Xe SS: Intels DLSS-Konkurrent mit KI auch für AMD und Nvidia

Intel hat zum Sneak Peek zur GPU-Architektur Alchemist für diskrete Gaming-Grafikkarten der Arc-Serie einen Konkurrenten zu Nvidia DLSS angekündigt. Xe Super Sampling, kurz Xe SS, setzt auf KI-Berechnungen, wird anders als DLSS aber nicht nur auf den eigenen Grafikkarten, sondern auch auf GPUs von AMD und Nvidia laufen.
Bei Xe SS handelt es sich wie bei Nvidia DLSS um ein intelligentes Upsampling-Verfahren, das das Rendern in einer geringeren Auflösung ermöglicht um so Rechenleistung zu sparen. Anschließend wird das Bild mittels Informationen eines neuronalen Netzwerkes aufgewertet, um eine zur ursprünglichen Auflösung vergleichbare Bildqualität zu erzielen. Das ist vor allem bei rechenintensiven Spielen mit Raytracing von großem Nutzen.
Xe SS ähnelt Nvidia DLSS sehr
Xe SS scheint dabei in der Grundfunktion sehr ähnlich wie Nvidia DLSS 2.0 (Test) zu arbeiten und unterscheidet sich damit zu AMDs aktuellen Konkurrenztechnologie FSR 1.0 (Test). Auch bei Xe SS wird das Bild in einer geringeren Auflösung gerendert und dann versucht, die Originalqualität über den Vergleich vorheriger Frames und der Kombination dieser Erkenntnisse mit dem in geringerer Auflösung gerenderten Bild wiederherzustellen. Dieser Schritt mithilfe der Informationen des neuronalen Netzwerkes ist im Grunde genau das, was Nvidia bei DLSS 2.0 macht.
Bei Xe SS erfolgt der Schritt nach den Raster- und Lichtberechnungen, aber vor dem Post Processing, das offenbar nach wie vor mit der nativen Auflösung erfolgt. Darüber hinaus werden auch die Nachbarpixel von jedem Frame einzeln analysiert und verglichen, um das optisch bestmögliche Ergebnis zu erzielen.
Xe SS hat wie DLSS eine temporale Komponente
Xe SS hat also eine temporale Komponente, was es Intels Technologie ermöglichen sollte, wie DLSS nicht vollständig in niedriger Auflösung berechnete Bildelemente mit den Informationen alter Frames wiederherzustellen. Darüber hinaus ist mit der von DLSS in der Regel zu beobachtenden hohen Bildstabilisierung zu rechnen, aber ebenso mit temporal entstandenen Bildfehlern, die das neuronale Netzwerk so gut wie möglich versuchen muss zu verhindern.
AMDs FSR arbeitet hingegen ohne neuronales Netzwerk und temporale Komponente, was zwar weniger Grafikfehler erzeugt, bezüglich Bildrekonstruktion und Stabilität aber von der im Spiel integrierten Kantenglättung abhängig ist. DLSS und dann wohl auch Xe SS ersetzen stattdessen das Anti-Aliasing komplett.
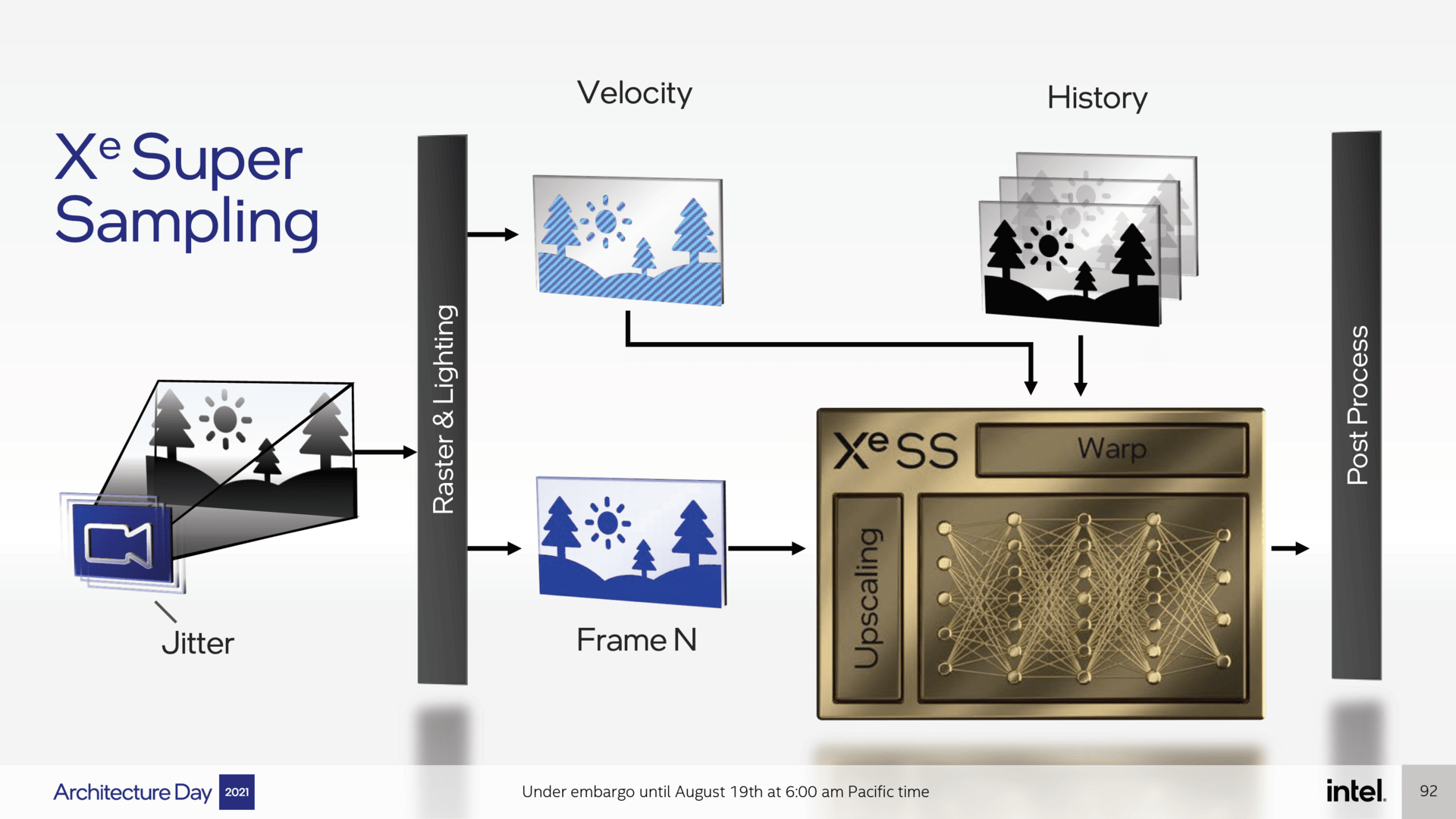
Xe SS per Matrix-Engines auf GPUs von Intel, Nvidia und AMD
Bis hier hin ähnelt Xe SS Nvidias DLSS, in einem anderen Punkt scheint die Technologie aber viel mehr AMDs FSR zu folgen: Wie FSR soll Xe SS nicht nur auf Intel-GPUs funktionieren. Auf Intels GPUs wird das neuronale Netzwerk mittels der Matrix-Engines und damit dem Äquivalent zu Nvidias Tensor-Kernen beschleunigt, was zu einer optimalen Performance und Bildqualität führen soll, aber auch auf Nvidias GPUs und sogar den GPUs von AMD ohne KI-Funktionen.
Xe SS wird dort über DP4a-Instruktionen beschleunigt und damit schlussendlich über die normalen FP32-Shader-ALUs mit einer Genauigkeit von INT8 beschleunigt. Das soll laut Intel langsamer als über die Matrix-Engines sein, wobei der Hersteller nur von einem kleinen Unterschied spricht. Wie schnell Xe SS auf Nicht-Intel-Arc-GPUs laufen wird, ist entsprechend davon abhängig, wie schnell diese mit DP4a umgehen können. Intels Arc soll Leistungssteigerungen von „bis zu 2ד erzielen, andere GPUs entsprechend weniger.
Nvidias Turing- und Ampere-Architektur kann INT8 mit DP4a über die Tensor-Kerne beschleunigen, doch ist unklar, ob das von alleine und ohne Codeanpassung mit der maximalen Performance passieren wird – ComputerBase geht aktuell nicht davon aus. Ab der Pascal-Generation gibt es DP4a darüber hinaus beschleunigt auf den normalen FP32-ALUs. AMDs RDNA 2 kann INT8 mit Rapid Packed Math über die FP32-ALUs beschleunigen, doch ob dies auch mit DP4a-Instruktionen geht, ist aktuell noch nicht gesichert. Die Redaktion versucht derzeit, diese Information von AMD in Erfahrung zu bringen, ist sich aber ziemlich sicher, dass die neuen Radeons (aber nur RDNA 2) damit umgehen können. Und auch wenn DP4a auf einer GPU nicht beschleunigt werden kann, ein Ausführen ohne Geschwindigkeitsgewinn sollte auf den FP32-ALUs immer möglich sein. Wobei dann fraglich ist, ob dies leistungstechnisch noch lohnenswert ist.
Xe Super Sampling wird Open Source
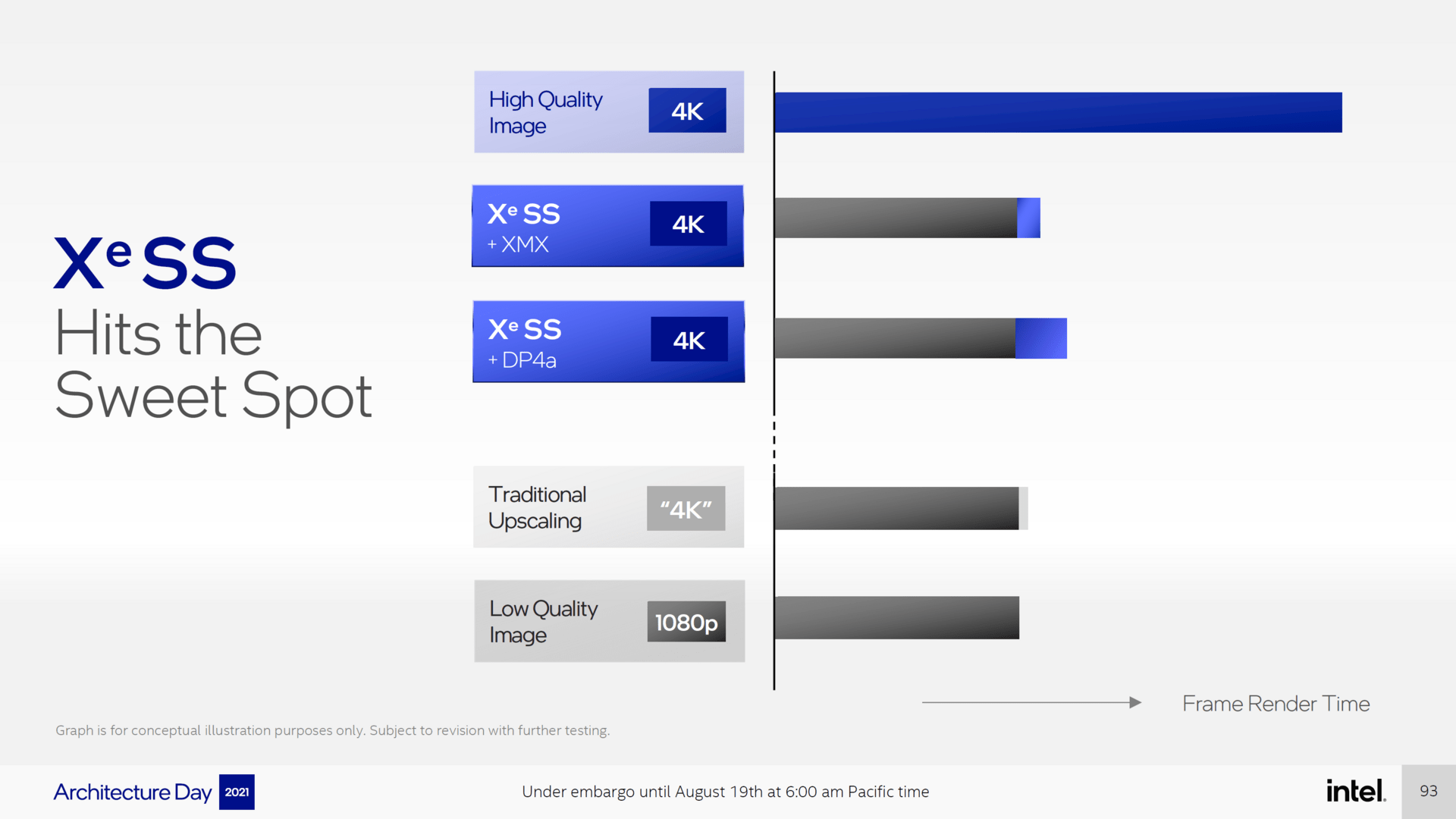
Genauere Details zu Xe SS gibt es noch nicht. Intel spricht jedoch davon, dass die grafische Qualität beim Rendern in Full HD sehr nahe an natives Ultra HD herankommen soll. In wie weit es verschiedene Qualitätsstufen geben wird, ist noch unklar. Intel hat sich in jedem Fall viel vorgenommen: Die Technologie soll es in zahlreiche Engines schaffen und nicht zuletzt deshalb leicht zu integrieren sein. In der Unreal Engine 5 soll es bereits eine Integration geben, darüber hinaus wird Xe SS zu einem späteren Zeitpunkt auch vollständig Open Source.
Im Laufe dieses Monats soll zudem ein erstes SDK für Intels Matrix-Engines erscheinen, mit dem Entwickler die Technologie in das eigene Spiel einbauen können. Eine Variante für die DP4a-Instruktionen soll im Laufe dieses Jahres folgen.

Auch wenn alles darauf hingedeutet hat, dass RDNA 2 das für Xe SS benötigte Rechenformat unterstützt, ganz gesichert war diese Information noch nicht. Doch hat AMD ComputerBase soeben bestätigt, dass RDNA 2 DP4a-Instruktionen mit Rapid Packed Math, also höherer Geschwindigkeit, beschleunigen kann. Xe SS wird damit auf Radeon-RX-6000-Grafikkarten lauffähig sein. Ältere AMD-GPUs unterstützen dagegen kein DP4a, können aber zumindest theoretisch die Berechnungen auch langsamer mittels FP32 oder FP16 durchführen.
ComputerBase hat die Informationen im Rahmen des Architecture Day 2021 von Intel vorab auf einem Event in Berlin unter NDA erhalten. Eine Einflussnahme des Herstellers auf die Berichterstattung fand nicht statt, eine Verpflichtung zur Veröffentlichung bestand nicht. Einzige Vorgabe war der frühestmögliche Veröffentlichungstermin.