AMD Zen: Der riesige Architektur-Sprung zu Excavator im Detail
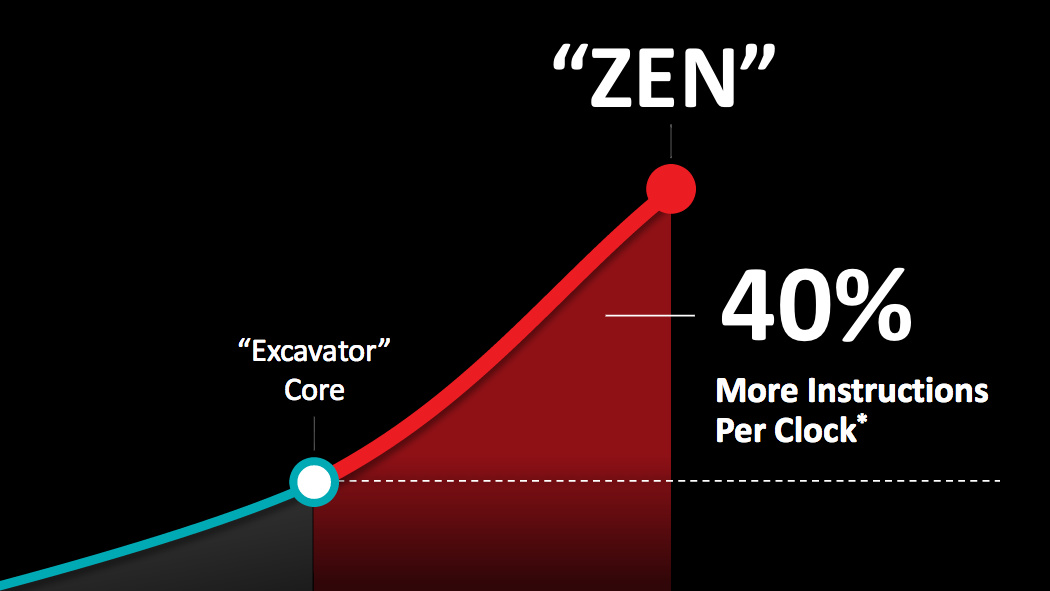
Zu Hot Chips 28 hat AMD mehr Details zur Zen-Architektur veröffentlicht. Diese zeigen, wie groß der Sprung zum Vorgänger Excavator in einigen Bereichen wirklich ist, viele Buffer wurden massiv erhöht, der Cache komplett überarbeitet und deutlich flotter gemacht. Denn das Ziel war klar: Konkurrenzfähig sein.
Zen: Ablösung für Jaguar und Excavator, extrem optimiert
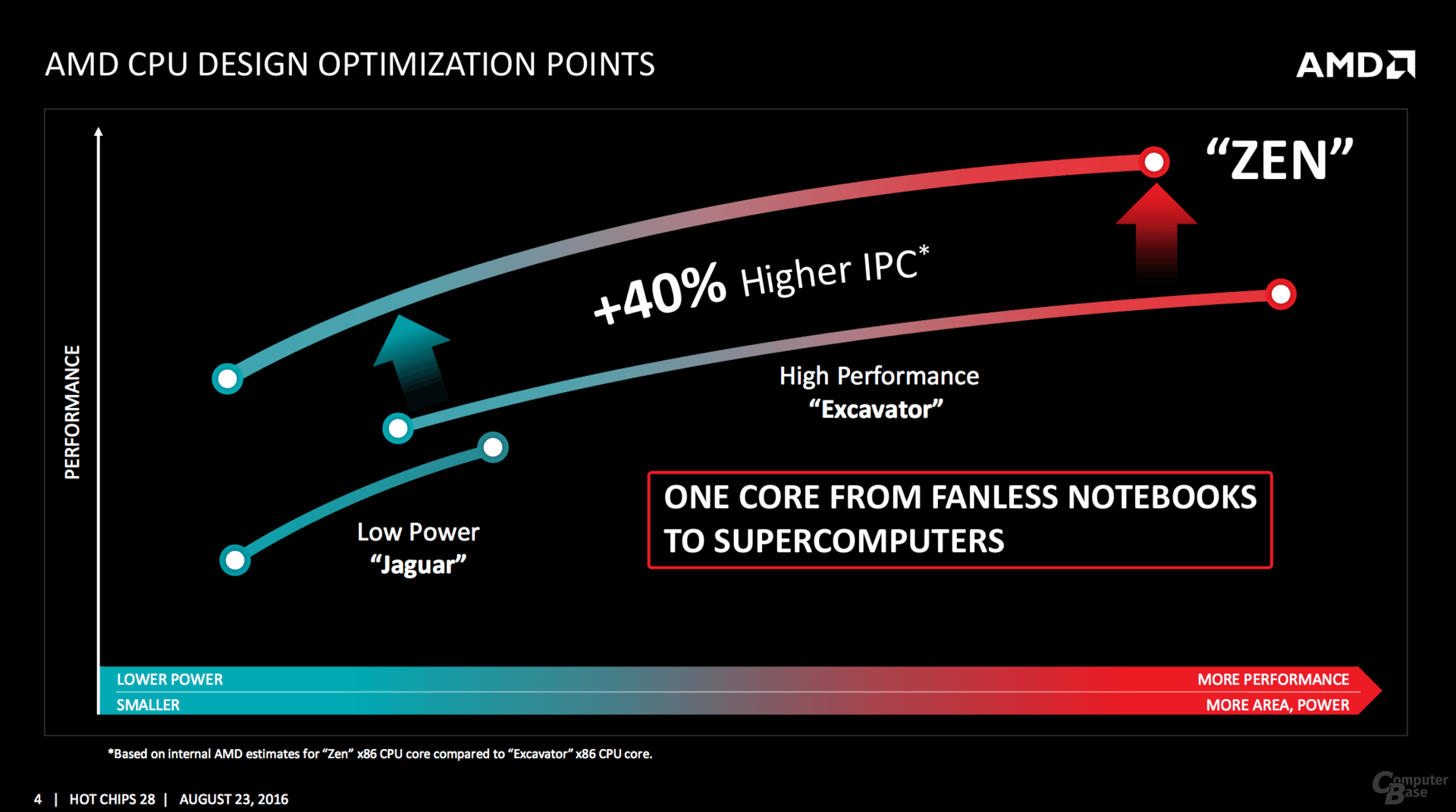
Zen wird AMDs Produkt für jeden Markt, dies stellt AMD einmal mehr klar. Die vor kurzer Zeit durchgesickerte Roadmap mit Raven Ridge, die ein Produkt mit einer TDP von nur 4 Watt zeigte, untermauert AMD am heutigen Tag. Denn der Hersteller spricht von lüfterlosen Notebooks, die mit Zen angetrieben werden sollen. Auf der anderen Seite wird die Architektur bis zum Supercomputer hochgezogen – Stichwort Naples, den 32-Kern-Prozessor zeigte AMD am vergangenen Donnerstag das erste Mal live. Doch dies könnte noch nicht einmal das Ende der Fahnenstange sein, im HPC sind spezielle CPUs denkbar, gepaart mit einer Grafikeinheit.
-
 AMD Zen: Architekturdetails zu Hot Chips 28
AMD Zen: Architekturdetails zu Hot Chips 28
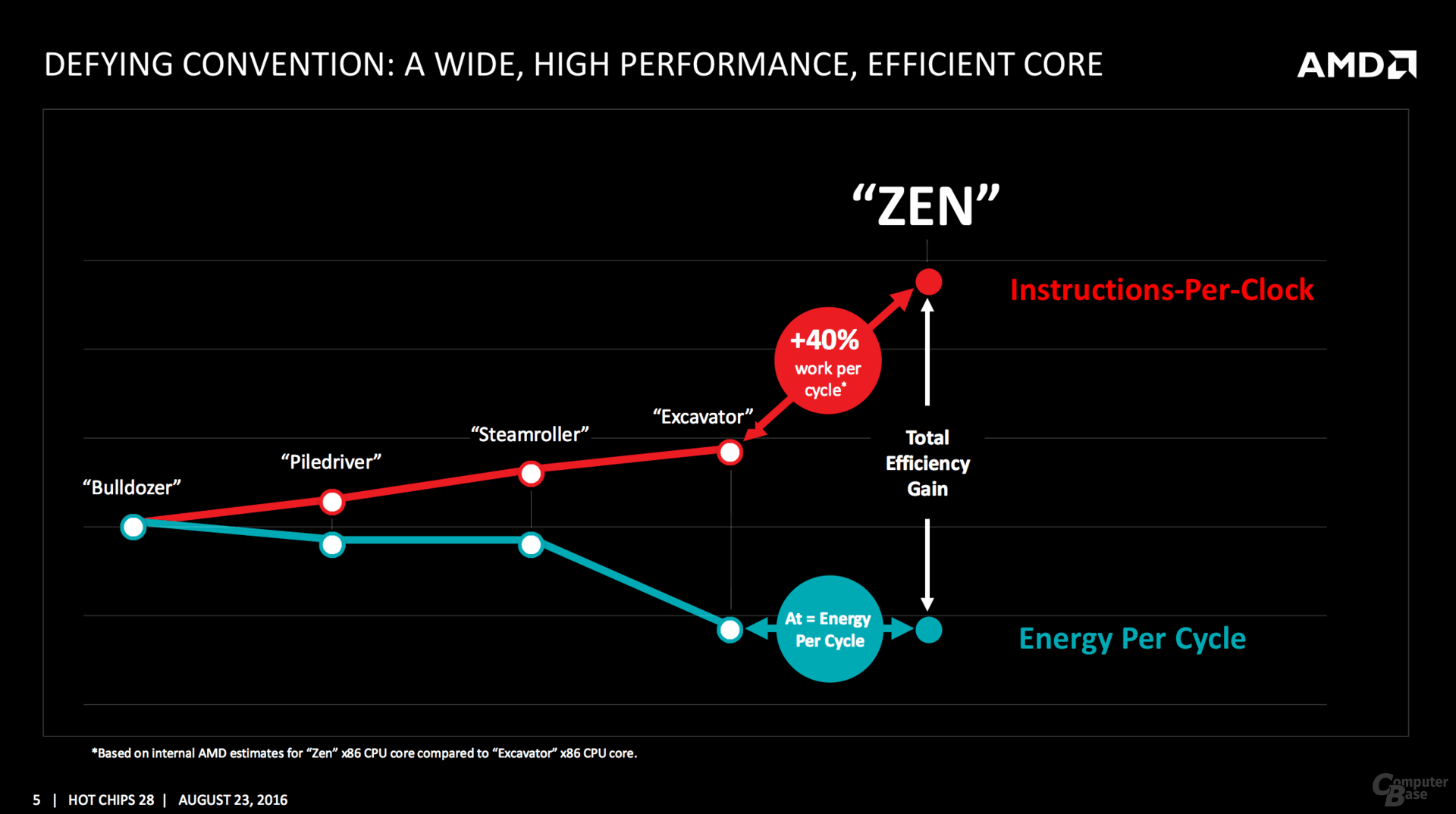

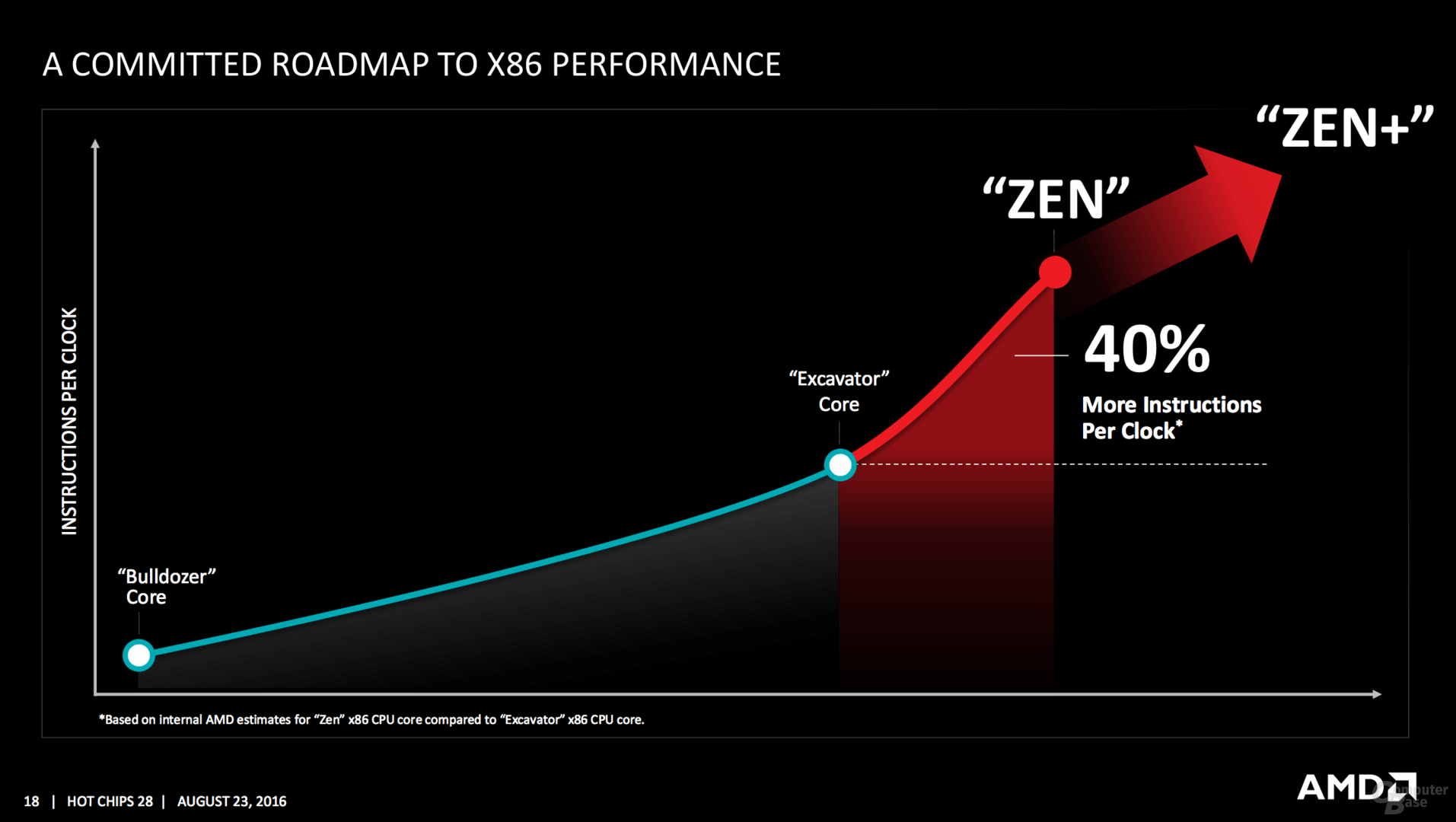
Von Excavator bleibt nichts übrig
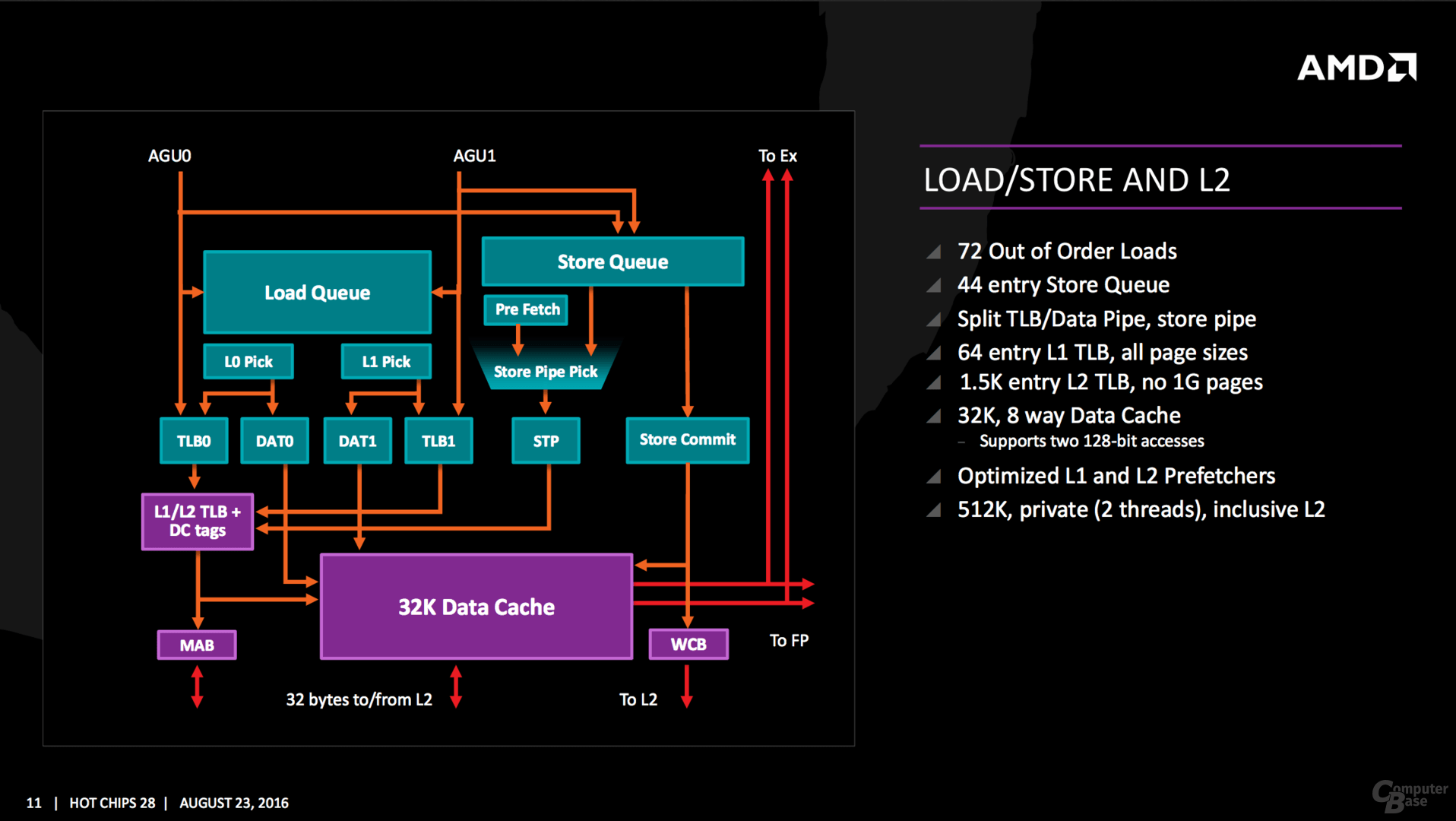
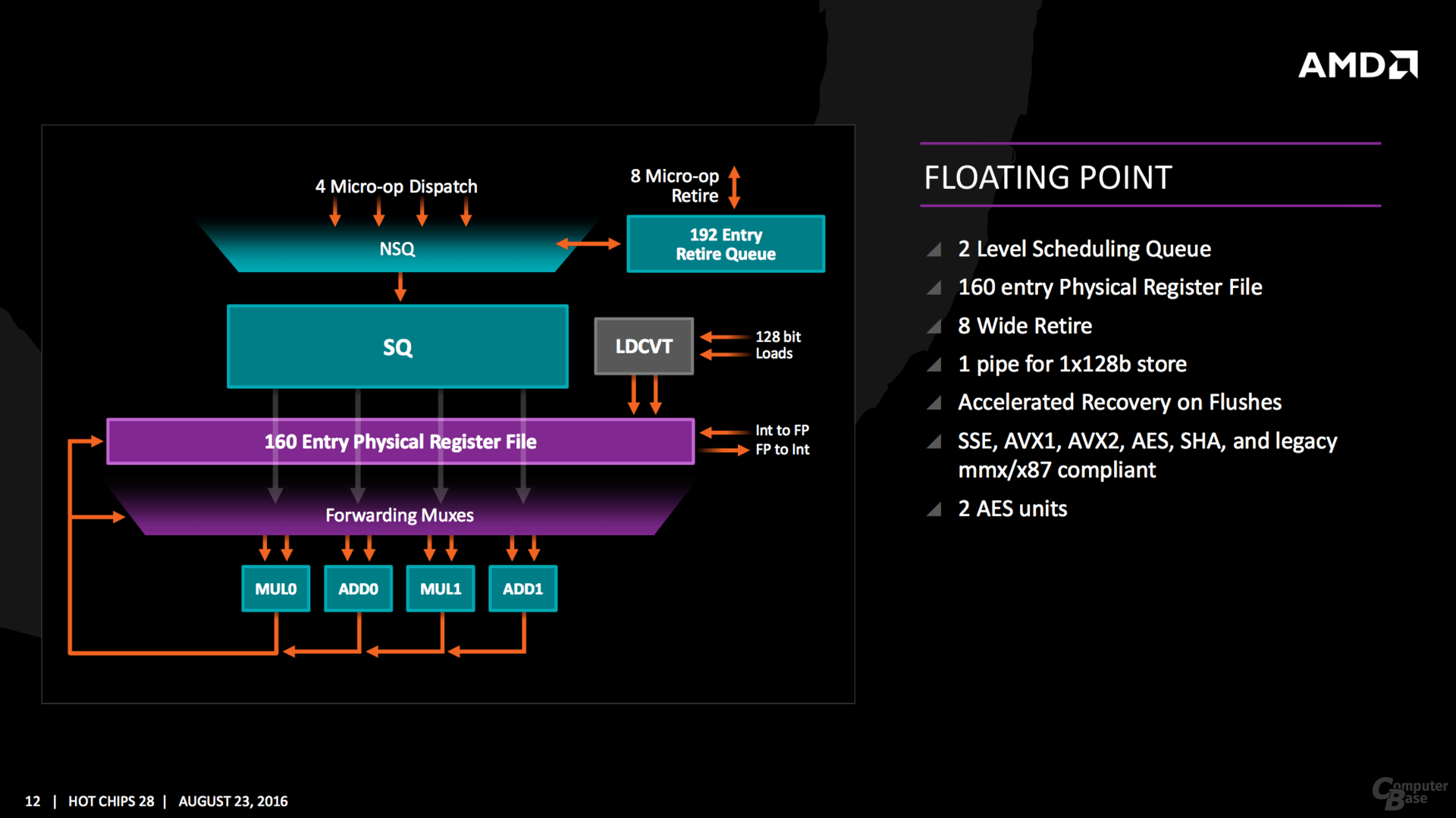
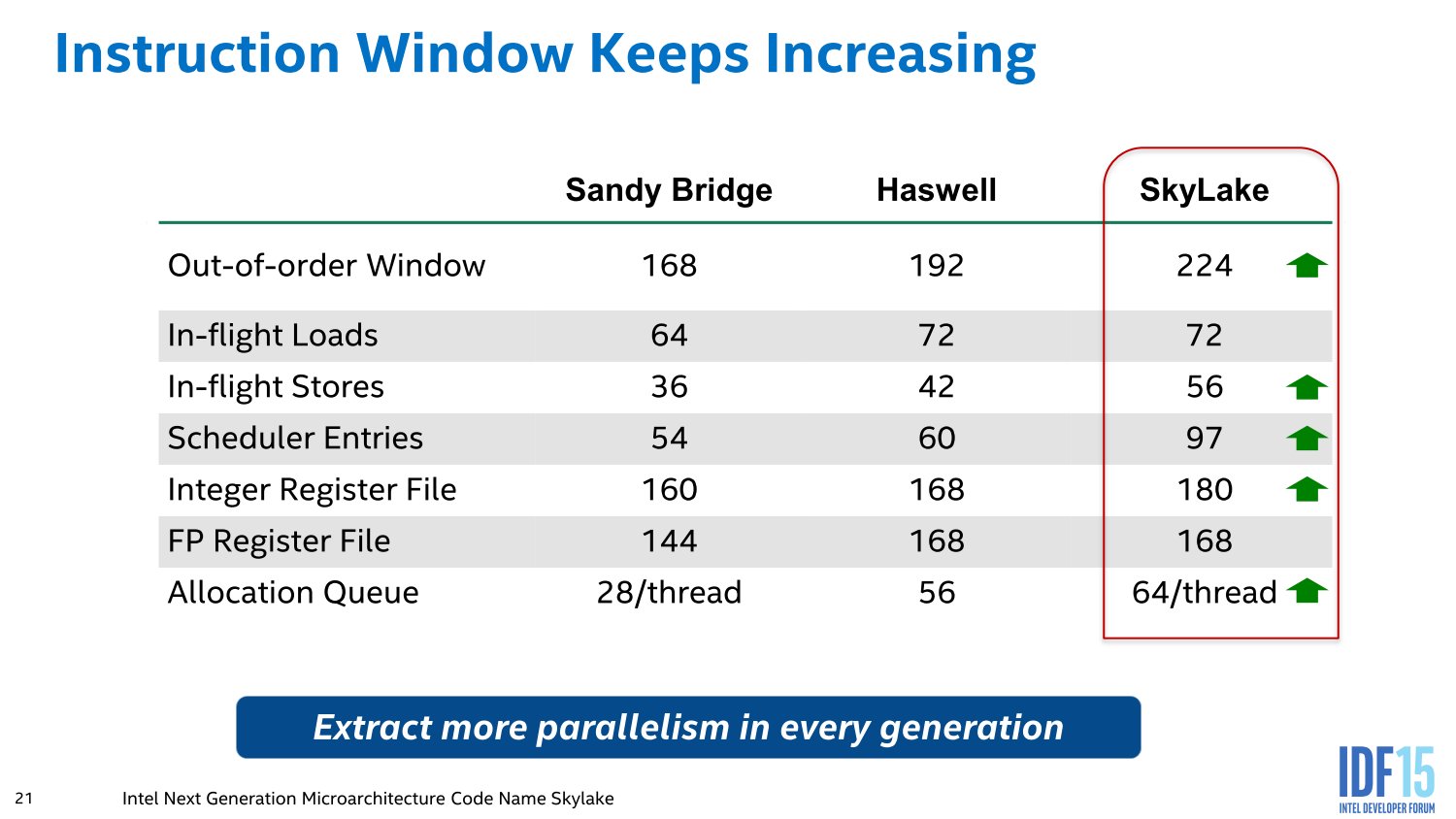
Die Änderungen im Vergleich zum Vorgänger sind brutal – aber genau dafür ist eine wirklich neue Architektur auch gedacht. Ganz neu ist ein Micro-op-Cache und Micro-op-Queue, so etwas Ähnliches verbaut Intel seit Sandy Bridge. Die Buffer-Größen für die einzelnen Segmente werden mitunter verdoppelt, in den meisten Fällen steht aber mindestens ein Plus von 50 Prozent auf der Habenseite, sei es im Integer- oder FP-Scheduler sowie den Load/Store/Retire-Queues. Auch das 168 Einträge umfassende Physical Register File in der Integer-Ebene sowie die 160 für Floating-Point-Operationen gehören zu den Neuerungen. Insgesamt sechs Instruktionen verteilt der Dispatcher an die Integer-Einheit mit vier ALUs und zwei AGUs, vier weitere Micro-ops gehen an die Floating-Point-Unit.
Die L1- und L2-Caches hat AMD extrem überarbeitet, erstmals gibt es wieder 64 KByte an der L1I-Front, dies gab es in alten Opteron-Zeiten das letzte Mal. Der 32 KByte große L1-Datencache arbeitet im Gegensatz zum Vorgängern nun mit Write Back.
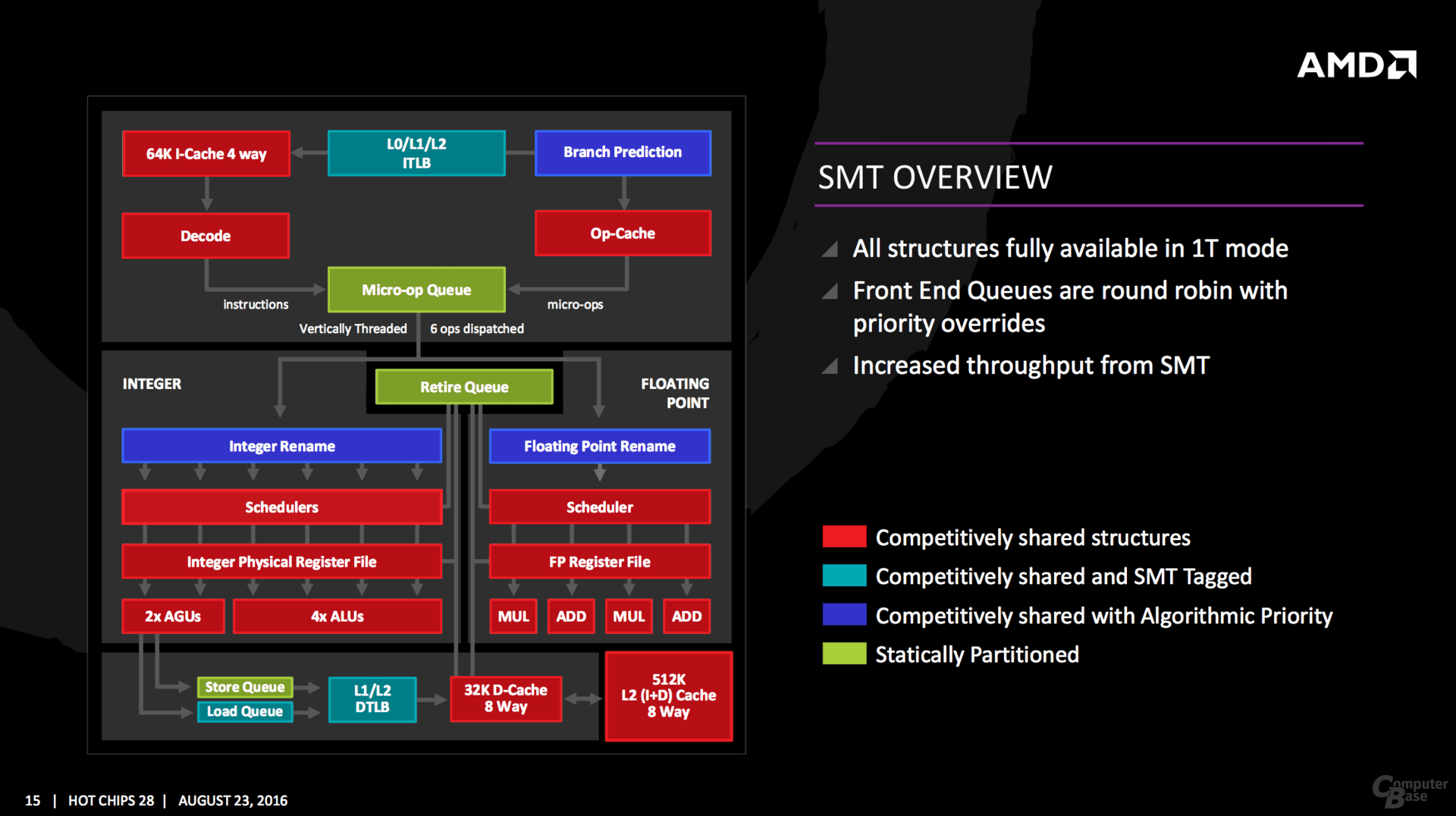
Gepaart wird das alles wie üblich mit Verbesserungen in der Sprungvorhersage, garniert mit SMT um aus einem Kern zwei Threads zu zaubern. Auch neue Instruktionen hat AMD mit im Gepäck, von RDSEED über SHA1/SHA256 bis XSAVEC/XSAVES/XRSTORS werden viele Sicherheitsfunktionen jetzt nativ unterstützt, die klassischen Features wie AVX & AES sind natürlich weiterhin mit von der Partie. Zwei Mal AVX-128 lässt sich dabei wie zuletzt erneut zu AVX-256 zusammenschalten.
Beim Blick auf die Konkurrenz und die Architektur von Haswell und Skylake von Intel zeigen sich oberflächlich gewisse Ähnlichkeiten, die Einträge bei den Schedulern und Buffern sind in einigen Fällen exakt gleich. Doch ist dies wenig überraschend, denn AMD ist nach dem gescheiterten Ausflug mit Bulldozer und einem radikal neuen Design zurück zum klassischen Profil gewechselt, welches bereits vor Jahren sehr ähnlich aussah. Ohnehin lässt dies keine Rückschlüsse auf die Leistungsfähigkeit zu, dafür sind die Informationen nach wie vor zu oberflächlich und nicht weitgehend genug – auch von Seiten Intels, die zuletzt kaum noch Details bei der Architektur preisgegeben haben. Dafür hatte AMD jedoch vor einigen Tagen einen 8-Kern-Summit-Ridge gegen Intels Broadwell-E mit acht Kernen bei gleichem Takt antreten lassen, mit dem Ergebnis, dass beide ähnlich schnell waren.
-
 AMD Zen: Architekturdetails zu Hot Chips 28
AMD Zen: Architekturdetails zu Hot Chips 28
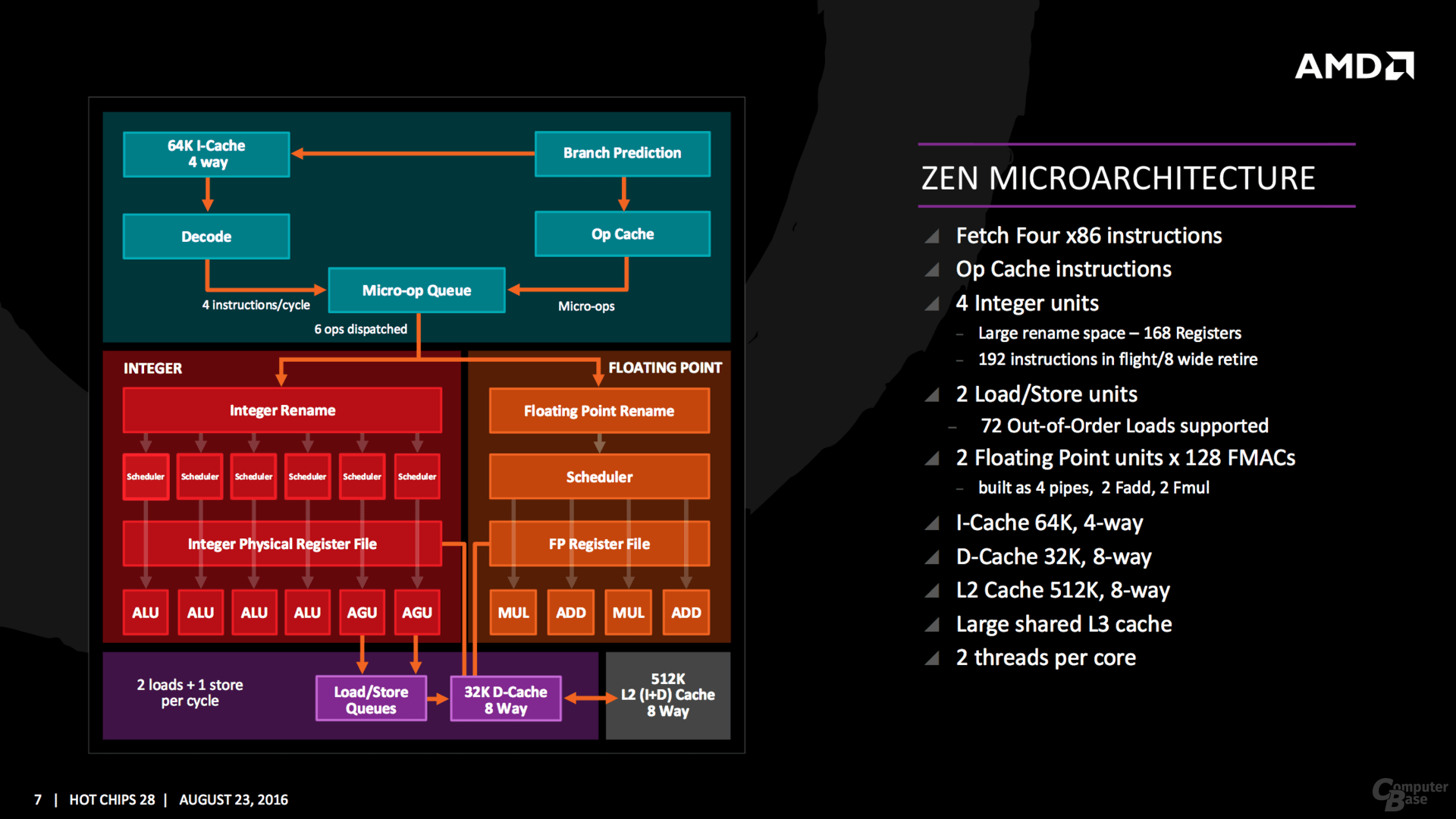
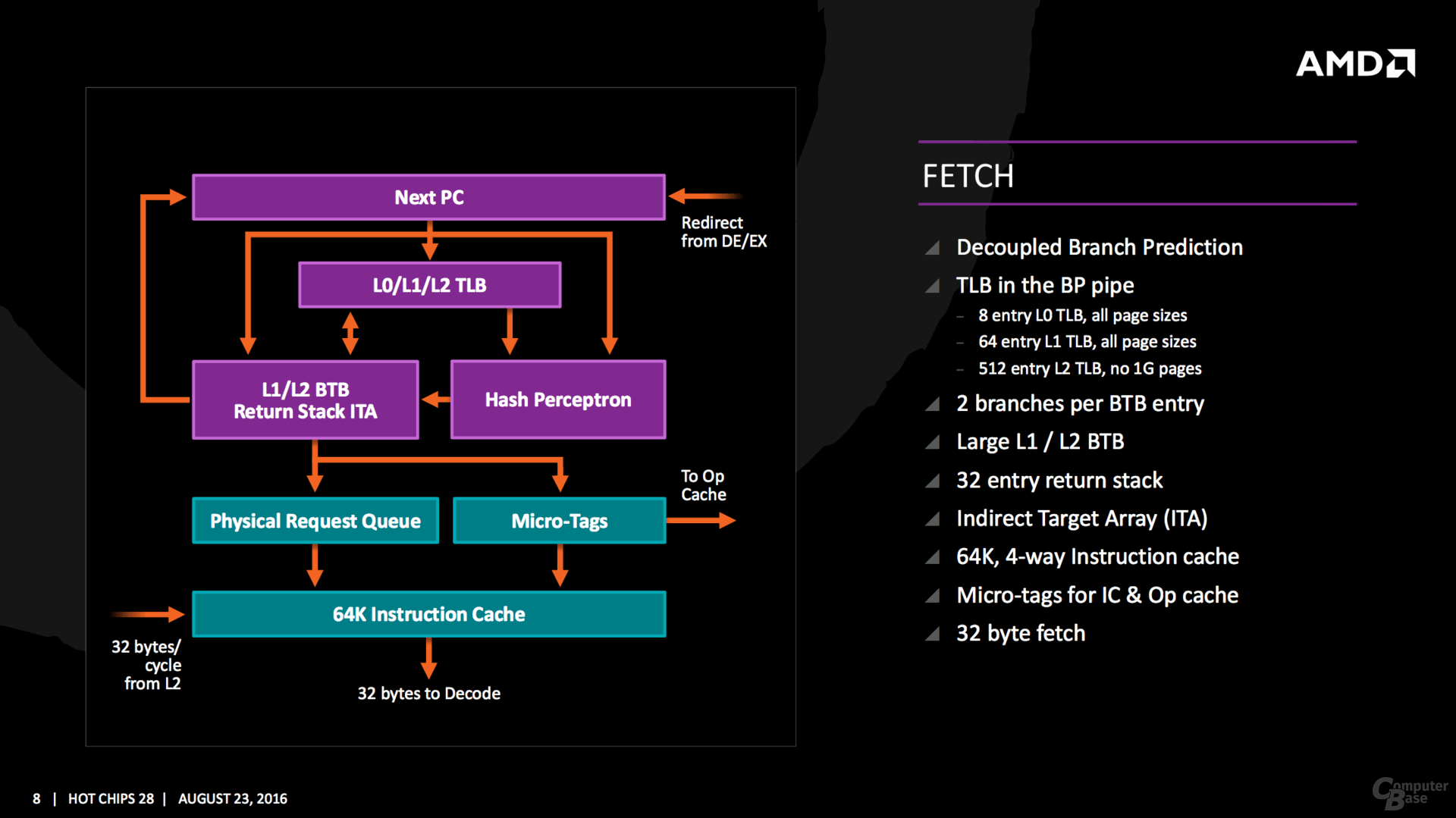
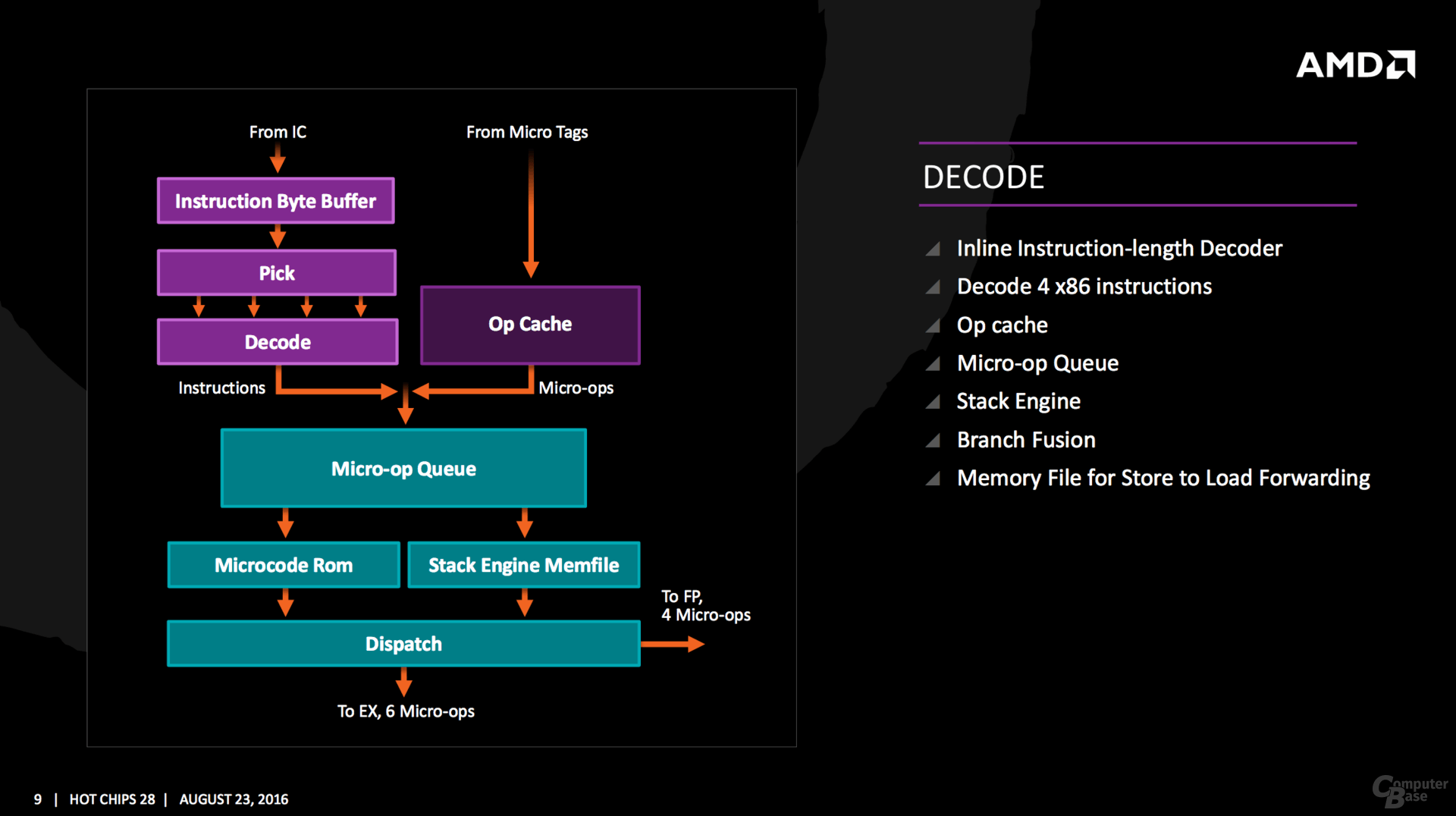
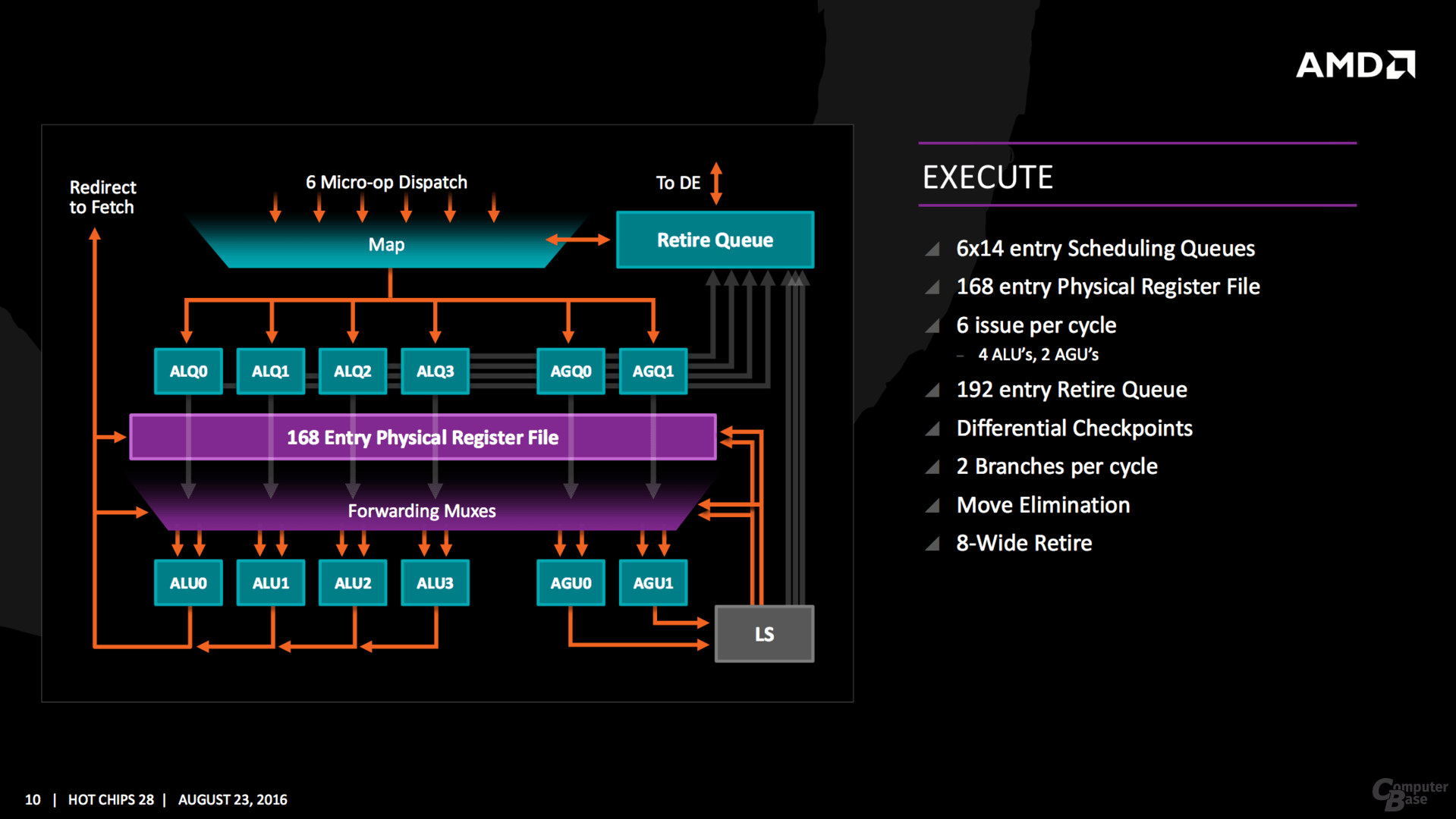
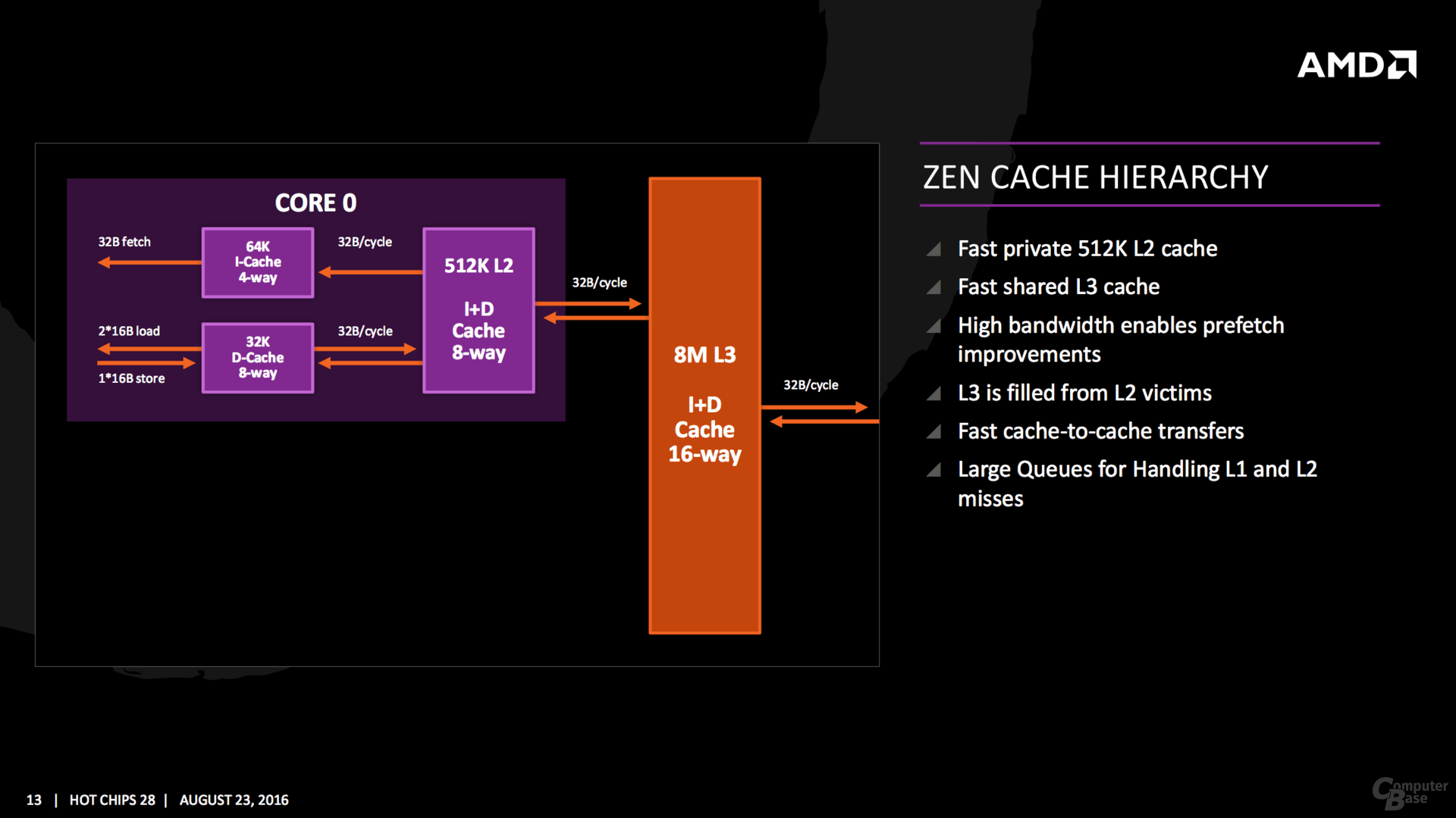
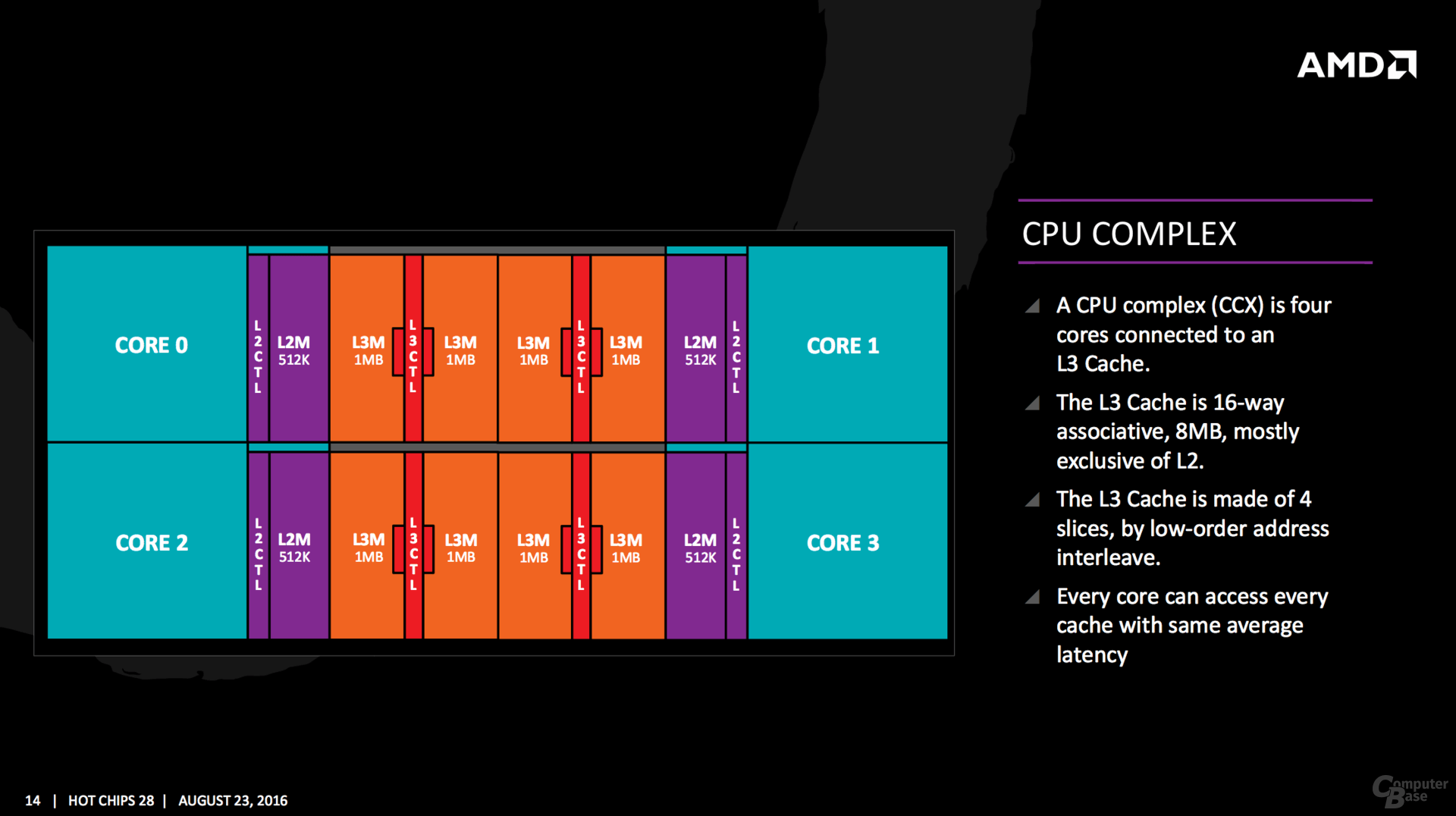
Einzelne Kerne fasst AMD mit den Caches zu einem Viererblock zusammen und nennt das neue Konstrukt CPU Complex (CCX). Auf die vier Kerne entfallen 8 MByte L3-Cache, der Cache ist dabei in mehrere Slices aufgeteilt. AMD betont aber, dass jeder Kern auf jeden Bereich des Caches im CCX mit der gleichen Latenz zugreifen kann. Während die L1- und L2-Cache-Bandbreite um den Faktor 2 gesteigert wurde, soll sie beim L3-Cache gar den Faktor 5 erreichen können.
Keine Informationen zu Speicher, I/O und sonstigem Uncore-Material
Erstaunlich ruhig verhält sich AMD bei allem, was eigentlich noch einen Prozessor ausmacht. Denn mit den Kernen allein ist es bekanntlich nicht getan, ganz vorn steht natürlich die altbekannte Northbrigde mit dem Speichercontroller, die PCI-Express-Lanes sowie jegliches weitere Material, was früher immer als Uncore klassifiziert wurde. Die Gerüchte dort gehen aktuell noch in viele Richtungen, handfeste Fakten sind rar. Hier gilt es einfach die kommenden Wochen abzuwarten, denn sollte die Vorstellung wirklich noch zum Ende des Jahres über die Bühne gehen, werden zuvor noch kleckerweise stetig weitere Informationen gestreut.
Anmerkung: Wenngleich die Präsentation von AMD erst am späten Dienstagabend Ortszeit in Cupertino über die Bühne geht, erhalten Teilnehmer wie ComputerBase vor Ort bereits am ersten Tag alle Informationen und Präsentationen, komplett ohne eine Sperrfrist. Vor Ort hat aber auch ComputerBase noch einen Termin mit AMD am Dienstag und wird die Meldung bei Bedarf aktualisieren/ergänzen.
- Bester CPU-Hersteller
- Bester Mobile-SoC-Hersteller
- Bester SSD/HDD-Hersteller
- Alle Wahlen im Überblick...