Raytracing in Spielen VI: Raytracing in Hardware beschleunigen
2/3Der Strahlengang durch den Raum sowie die anschließende Bestimmung der Schnittstelle zwischen Polygon und Strahl können durch Beschleunigungsstrukturen deutlich vereinfacht werden. Dabei handelt es sich um räumliche Aufteilungen, die die Polygone nach ihrer Nähe zur Kamera sortieren und so die Bestimmung vereinfachen.
Beschleunigungsstrukturen
Ein Beispiel für eine Beschleunigungsstruktur lieferte bereits im Jahr 2008 einer der früheren Raytracing-Artikel. Die Beschleunigungsstrukturen bleiben in statischen Szenen gleich, müssen aber in dynamischen Szenen laufend aktualisiert werden. Sie liegen typischerweise im VRAM der GPU.
Ein Beispiel für eine Beschleunigungsstruktur ist der k-dimensionale Baum (k-d-Baum), der bereits 1975 für die Sortierung von Daten vorgeschlagen wurde. Um einen k-d-Baum zu erstellen, wird der Raum immer wieder in zwei Hälften, die gleich viele Polygone enthalten, geteilt. Der Vorgang endet, wenn nur noch ein Polygon im letzten Teilraum übrig ist. Soll geprüft werden, in welchen Raum der Strahl trifft, werden nur die Räume, die getroffen werden, weiter betrachtet. Polygone in einem Raum, der nicht getroffen wird, können hingegen auf einen Schlag verworfen werden.

Dadurch lässt sich deutlich schneller das erste Polygon, das der Strahl treffen wird, ermitteln, ohne alle Polygone einzeln überprüfen zu müssen. Verbesserte Versionen eines k-d-Baums teilen den Raum so, dass die Polygone in den beiden Hälften gleich wahrscheinlich von einem Strahl getroffen werden können, sie beziehen also Verdeckungen durch andere Polygone mit ein.
Eine neuere Beschleunigungsstruktur ist die Hierarchie der umschließenden Volumen (Bounding Volume Hierarchy, BVH). Sie teilt den Raum in beliebig viele, quaderförmige Boxen ein. Ein fundamentaler Unterschied zum k-d-Baum ist, dass sich die Boxen bei der BVH überlappen können, um mehr Flexibilität zu ermöglichen. Die Struktur einer BVH ist so besonders leicht für jede Szene konstruierbar. Allerdings kann es sein, dass ein Strahl in den überlappenden Bereich läuft und so mehr Boxen auf Schnittstellen geprüft werden müssen, als in einem k-d-Baum. Trotzdem sollen beide vergleichbare Vorteile für die Schnittstellenbestimmung liefern.
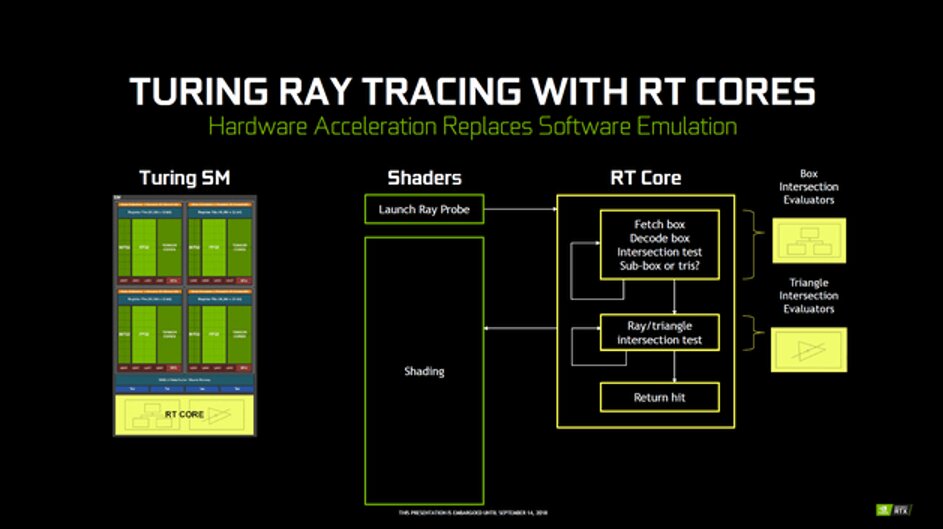
Besonders in den letzten zehn Jahren wurden die Konstruktion und die Nutzung von BVHs in der Forschung vorangetrieben. Auch Nvidia nutzt BVH als Beschleunigungsstruktur in seinen RT-Cores. Alle zugehörigen Berechnungen beim Strahlengang durch den Raum, werden von den RT-Cores zusammen mit der Schnittstellenbestimmung ausgeführt.
Anforderungen der Raytracing-Pipeline
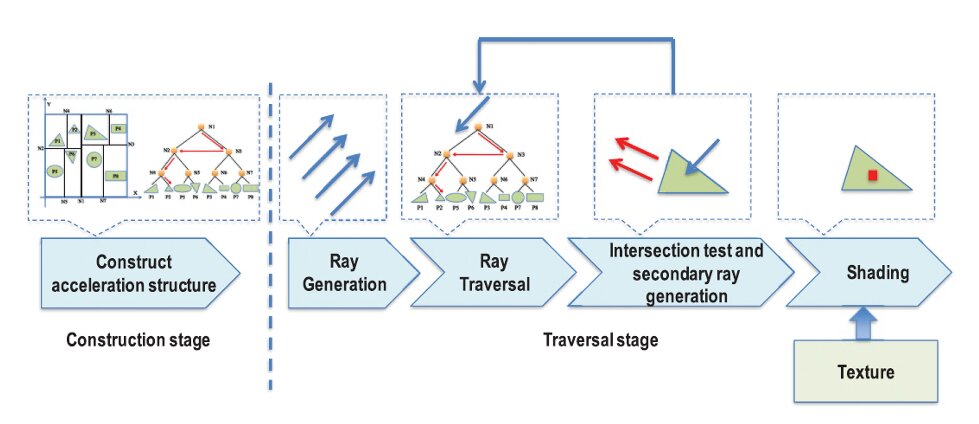
Die Raytracing-Pipeline stellt besondere Anforderungen an die Hardware, um performant berechnet werden zu können. Wirft man einen genaueren Blick auf die Pipeline, lässt sie sich in fünf Schritte unterteilen. Sie bestehen aus
1. der Konstruktion der Beschleunigungsstruktur, 2. der Strahlengeneration, 3. dem Strahlenflug durch den Raum (berechnet vom BVH-Algorithmus), 4. der Schnittstellenbestimmung sowie 5. dem Shading.
Der erste Schritt ist außen vor, da er nicht für jeden Strahl einzeln durchgeführt werden muss. Schritte 2-5 ergeben zusammen den ersten Schritt des auf der vorigen Seite besprochenen Raytracing-Algorithmus. Die Schritte 3 und 4 benötigen dabei am meisten Rechenleistung. Allerdings verlangen alle Schritte nach einer Vielzahl an Anpassungen in Grafikkarten.
Raytracing ist ein Prozess, der sich leicht parallelisieren lässt, da jeder Strahl vom Verlauf der anderen Strahlen unabhängig ist. Da Grafikkarten enorm viele Shader enthalten, könnte man davon ausgehen, dass diese für Raytracing bereits optimal seien.
Ray tracing is believed to be a classical example of embarrassingly parallel applications.
Das Problem mit Grafikkarten ist allerdings, dass sie für die Rasterisierung darauf optimiert wurden, vielfach exakt die gleichen Instruktionen auf verschiedene Daten anzuwenden. In der Informatik spricht man von „Single-Instruction, Multiple-Data“ (SIMD). Beim Raytracing verhalten die Strahlen sich allerdings jeweils unterschiedlich, wenn sie auf spiegelnde, diffuse bzw. beschattete Oberflächen treffen, weswegen sich die Instruktionen pro Strahl unterscheiden. Das bedeutet, dass sich für unterschiedliche Strahlen mit hoher Wahrscheinlichkeit auch verschiedene Rechenwege ergeben. Wenn ein Shader, dessen Strahl kein Polygon getroffen hat, auf einen Shader warten muss, der mit mehrfachen Sekundärstrahlen duch Reflexionen beschäftigt ist, verringert sich die Shader-Auslastung erheblich. Herkömmliche Rasterizer-Architekturen nach SIMD sind also bei Raytracing im Nachteil.
CPUs auf der anderen Seite arbeiten mit einer großen Bandbreite an Instruktionen, die auf denselben Datensatz angewandt werden, also „Multiple-Instructions, Single Data“ (MISD). Auch diese Architektur ist für Raytracing nicht optimal, weil die Speicheranbindung deutlich weniger Bandbreite als bei Grafikkarten bietet.
Die einzelnen Raytracing-Schritte im Detail
Der erste Blick gilt dem BVH-Algorithmus, der für den Strahlengang durch den Raum verantwortlich ist. Ideal für den BVH-Algorithmus wäre ein Mischfall zwischen SIMD und MISD, bei dem jeder Rechenkern viele verschiedene Instruktionen abarbeiten und auf viele verschiedene Daten mit hoher Bandbreite zugreifen könnte. Dies nennt man „Multiple-Instructions, Multiple-Data“ (MIMD).
Intels mittlerweile eingestellte Xeon Phi auf Basis der Larrabee-Architektur sind solche MIMD-Beschleuniger. Ein bedeutsamer Nachteil von MIMD-Hardware sind die höheren Kosten in Form des Platzverbrauchs pro Kern im Vergleich zu Grafikkarten-Shadern. Dies kommt durch die erhöhte Flexibilität und Unabhängigkeit der Kerne, die mehr Transistoren benötigt. Damit einher gehen ein erhöhter Strombedarf und somit mehr Abwärme. Besser sind speziell für den BVH-Algorithmus entwickelte ASICs, die den Flug der Strahlen im Raum hocheffizient mit kleinstem Platzbedarf berechnen können.
Die anderen Schritte wie die Strahlenerzeugung, die Konstruktion der Beschleunigungsstruktur sowie die Schnittstellenbestimmung sind sehr Compute-intensiv und beinhalten eine große Menge an Gleitkomma-Berechnungen (FLOPS). Diese Art von Berechnungen sind für Grafikkarten relativ gut zu meistern, solange ausreichend Rechenleistung in der benötigten Genauigkeit zur Verfügung steht. Für die Konstruktion der Beschleunigungsstruktur gibt es seit 2012 komplett parallelisierte Algorithmen, die gut auf Grafikkarten ausgeführt werden können. Dadurch kann die Beschleunigungsstruktur auch in Echtzeit aktualisiert werden.
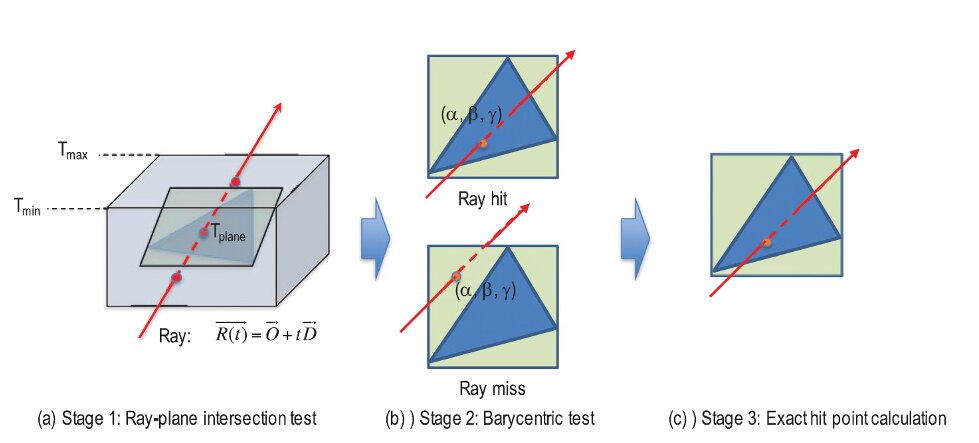
Die Schnittstellenbestimmung ist bei Raytracing essentiell und weil der Leistungsbedarf mit steigender Strahlendichte rasant anwächst, ist es sinnvoll, die Berechnung in eine eigene Recheneinheit auszulagern. Dabei kann man den Vorgang, die Schnittstelle zwischen Strahl und Polygon zu bestimmen, in drei Schritte aufteilen. Im ersten wird getestet, ob der Strahl generell die Ebene trifft, in der das Polygon liegt. Im zweiten Schritt wird mit reduzierter Genauigkeit unter Verwendung von baryzentrischen Koordinaten geprüft, ob das Polygon getroffen wird. Als letztes wird dann der exakte Trefferpunkt bestimmt. Durch die doppelte Prüfung können besonders viele Strahlen früh verworfen werden. Außerdem werden dadurch weniger Rechenwerke für den dritten Schritt als für die anderen Schritte benötigt, was Chipfläche spart und die Effizienz erhöht.
Zahlenformate und Speicherzugriffe
Eine Besonderheit ist die Wahl des Zahlenformats für die Berechnungen, die in den Shadern vorgenommen werden. Grafikkarten bearbeiten am schnellsten Gleitkomma-Berechnungen, daher liegt es nahe, alle Koordinaten der Szene als Gleitkommazahlen abzuspeichern. Gleitkommazahlen haben allerdings den Nachteil, dass ihre Genauigkeit relativ zur Zahlengröße ist, bei großen Zahlen also zwischen zwei benachbarten Zahlen größere Abstände als bei kleinen Zahlen liegen. Werden die Koordinaten dann, wie bei der Konstruktion des BVH üblich, auf den Bereich zwischen 0 und 1 normiert, wird die Zahl der zur Verfügung stehenden Koordinaten immer kleiner, je weiter man sich von der 0, dem Ursprung, entfernt.
Eine Lösung dieses Problems ist die Verwendung von Festkommazahlen, die eine Variation der Ganzzahlen (Integer) darstellen. Allerdings müssen dann die Rechenwerke der Grafikkarten viel mehr Integerberechnungen verarbeiten, als üblich. Möglicherweise ist das der Grund, warum die Turing-Architektur von Nvidia die Berechnungen von Floating-Point und Integer parallelisiert hat, obwohl dies eine Vergrößerung der benötigten Chipfläche zur Folge hat. Allerdings hat so eine Parallelisierung auch für die herkömmliche Rasterisierung Vorteile.
Eine weitere Herausforderung ist der Speicherzugriff während der Berechnung des BVH-Algorithmus. Der Speicherbedarf selbst ist für die Beschleunigungsstruktur moderat, allerdings erfolgen die Speicherzugriffe unzusammenhängend und in großer Zahl. Besonders schwerwiegend ist die Tatsache, dass moderne GPUs darauf optimiert sind, schnell auf zusammenhängende Blöcke des Speichers zuzugreifen, was beim BVH-Algorithmus nicht der Fall ist. In einer experimentellen Studie wurde ein Raytracing-Chip so umgesetzt, dass Teile der Beschleunigungsstruktur komplett in den Cache passten und Strahlen, die die gleichen Teile der Szene passierten, als Gruppe berechnet wurden. Allein durch diese Maßnahmen konnte der Bedarf an Speicherbandbreite um 80 bis 85 Prozent reduziert werden. Leider ist davon auszugehen, dass solche Optimierungen erst machbar werden, wenn Spiele ausschließlich auf Raytracing setzen, statt wie zurzeit einen kombinierten Ansatz zu verfolgen.
Denoising
Eine sinnvolle Möglichkeit zur Reduzierung des Leistungsbedarfs von Raytracing ist die Nutzung von Denoising (Rauschunterdrückung). Werden weniger Strahlen verschossen als eigentlich notwendig, bildet sich in dunklen und beschatteten Bereichen ein deutlich sichtbares Rauschen. Dieses kann durch räumliches Filtern effektiv entfernt werden, wie es zum Beispiel im Renderprogramm Blender seit 2017 verfügbar ist. Dadurch kann die Renderzeit bei (annähernd) gleicher optischer Qualität deutlich reduziert werden. In Spielen wird eine Kombination aus räumlichen und temporalen Filtern verwendet, was weitere Performance-Verbesserungen ermöglicht.
Theoretisch können Nvidias RTX-Grafikkarten auch ein AI-Denoising über die Tensor-Cores beschleunigen. In Spielen wird es allerdings bisher nicht verwendet. Stattdessen werden die Tensor-Cores für DLSS benutzt. Blender wiederum unterstützt AI-Denoising im Rahmen von Nvidia Optix seit Ende 2019 und nutzt dafür auch die Tensor-Cores. Andere Renderprogramme wie Octane und Luxion KeyShot bieten ebenfalls Plug-ins zur Nutzung der Tensor-Cores. Warum dies Spielen vorenthalten bleibt, ist nicht bekannt.