
Turing TU102, -104, -106: Die Technik der Nvidia GeForce RTX 2080 Ti, 2080 & 2070
2/3Die Turing-Architektur im Detail
Die letzten Abschnitte haben sich mit den groben Änderungen der GPUs beschäftigt, primär mit der Anzahl der Einheiten. Anders als bei Pascal hat Nvidia bei Turing aber viel mehr bei den Einheiten selber geändert und auch neue hinzugefügt. Die folgenden Abschnitte gehen näher auf diese Änderungen ein und treffen, falls nicht anders erwähnt, für TU102, TU104 und TU106 zu.
-
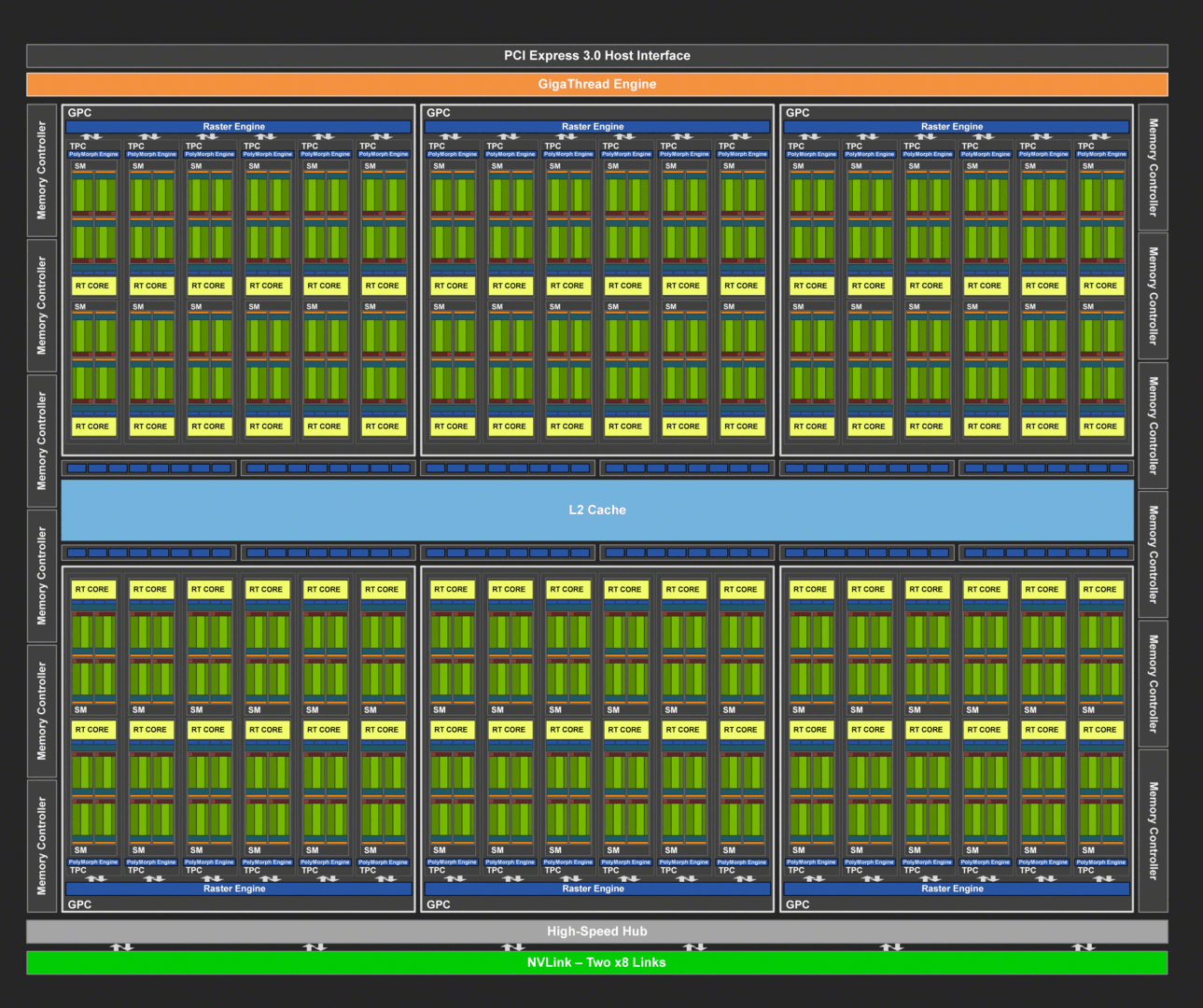 TU102-Blockdiagramm (Bild: Nvidia)
TU102-Blockdiagramm (Bild: Nvidia)

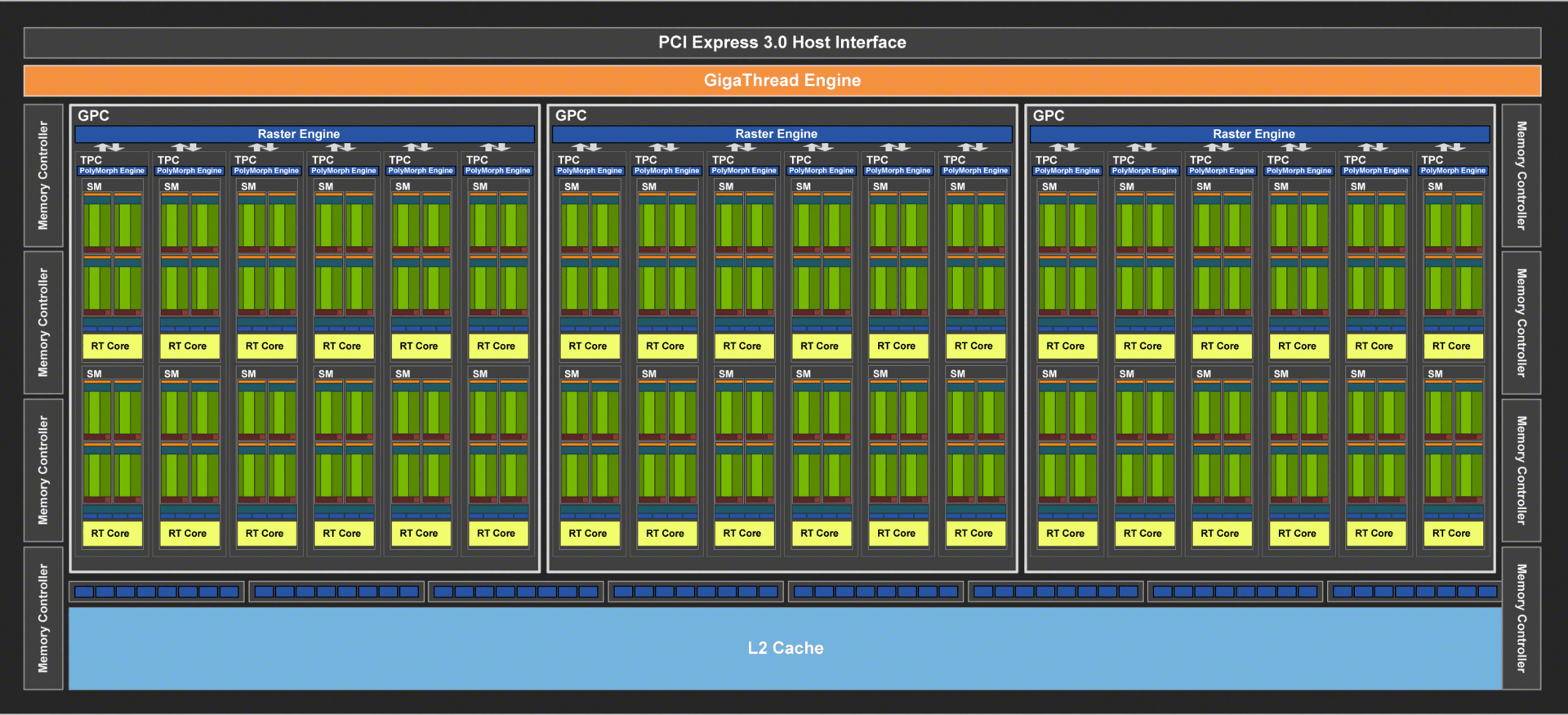
Der Streaming Multiprocessor ist komplett neu
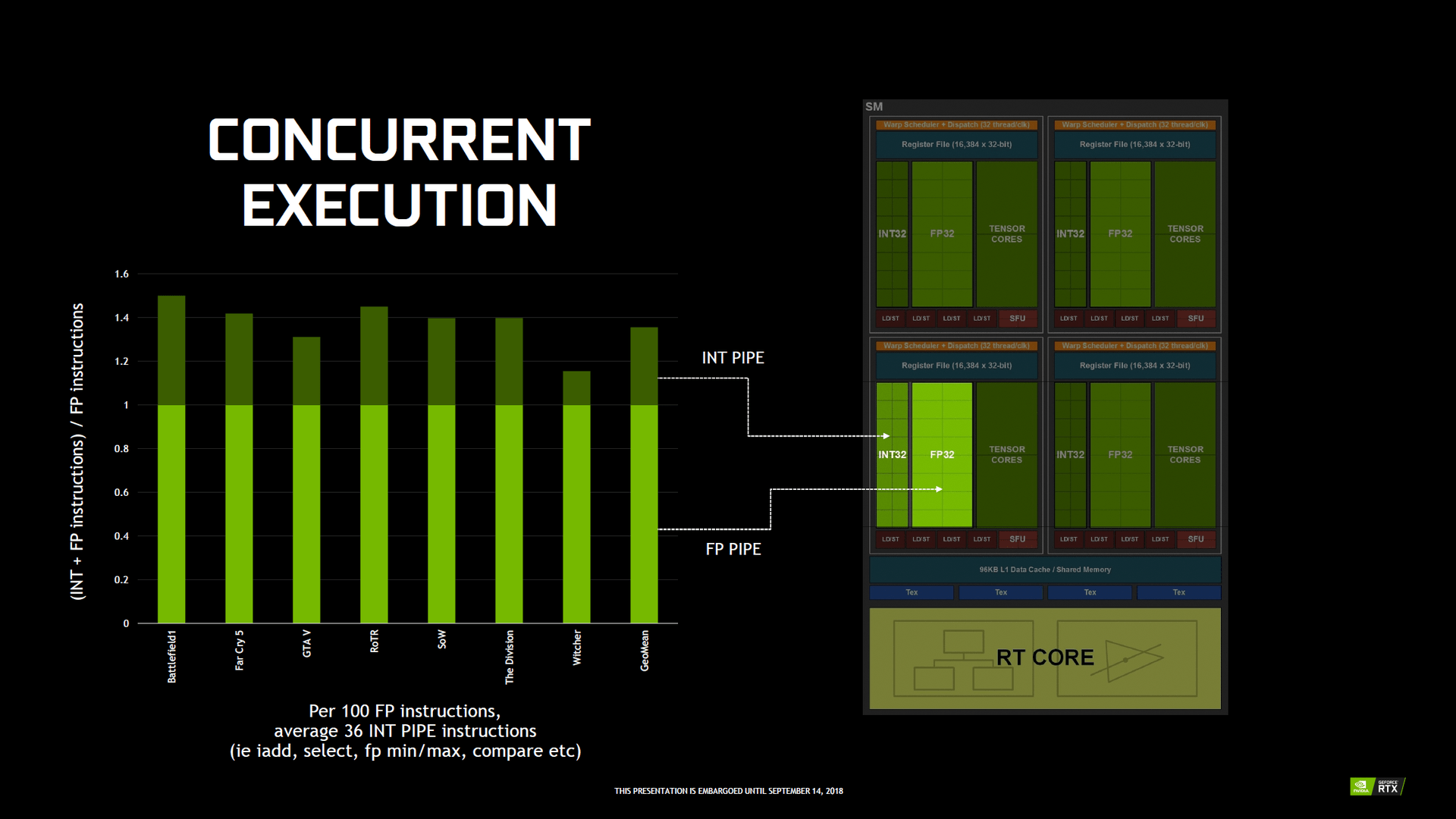
Der Streaming Multiprocessor, der Funktionsblock, der die wichtigsten Einheiten umfasst, wurde mit Turing runderneuert. Das fängt bereits beim Aufbau an. Während „Gaming-Pascal“ noch 128 ALUs pro SM bot, gibt es auf Turing pro SM nur noch 64 ALUs – genau wie bei den professionellen GPUs GP100 (Pascal) und GV100 (Volta) und übrigens auch AMDs GCN. Dadurch verändert sich die Auslastung der Einheiten beziehungsweise die Art und Weise, wie diese ausgelastet werden. Je nach Workload haben beide Systeme verschiedene Vor- und Nachteile.
| TU102 | TU104 | TU106 | |
|---|---|---|---|
| Fertigung | 12nm FFN (TSMC) | ||
| Die-Fläche | 754 mm² | 545 mm² | 445 mm² |
| Transistoren | 18,6 Milliarden | 13,6 Milliarden | 10,6 Milliarden |
| GPCs | 6 | 3 | |
| TPCs | 36 (6/GPC) | 24 (4/GPC) | 18 (6/GPC) |
| SMs | 72 (12/GPC) | 48 (8/GPC) | 36 (12/GPC) |
| Tensor Cores | 576 | 384 | 288 |
| RT Cores | 72 | 48 | 36 |
| FP32 Cores (CUDAs) | 4.608 | 3.072 | 2.304 |
| INT32 Cores | 4.608 | 3.072 | 2.304 |
| ROPs | 96 | 64 | |
| TMUs | 288 | 192 | 144 |
| Memory Interface | 384 Bit | 256 Bit | |
| L2 Cache | 6.144 KB | 4.096 KB | |
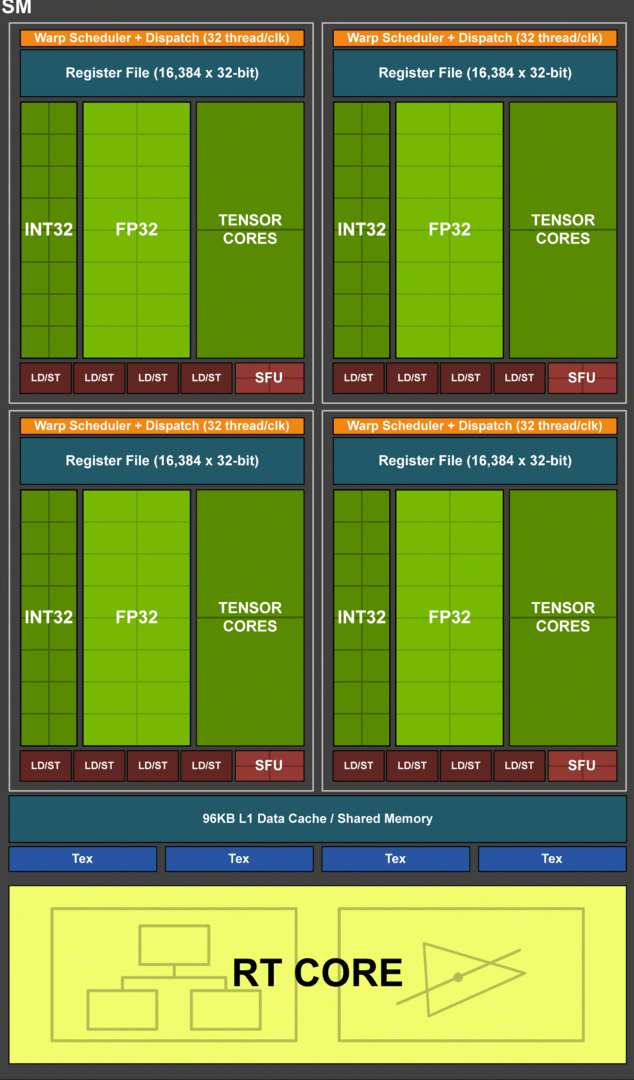
Turing mit dedizierten INT32-Einheiten
Bei Pascal können die 128 ALUs pro Takt eine FP32-Berechnung durchführen – also mit Floating-Point-Genauigkeit (Gleitzahlen). Allerdings wird in Anwendungen und Spielen nicht nur mit Floating Point, sondern ebenso mit Integer (Ganzzahlen) gearbeitet. Diese Aufgabe übernimmt bei Pascal ebenfalls die FP32-Einheit, die dann aber für FP-Berechnungen blockiert ist. Bei Turing gibt es pro SM dagegen 64 FP32-Einheiten und zusätzlich 64 weitere INT32-Einheiten, die damit zwar nicht so flexibel (und oft) einsetzbar sind, aber exklusiv für Integer-Berechnungen genutzt werden und daher die FP32-Einheiten nicht blockieren. Laut Nvidia kommen in modernen Spielen im Durchschnitt auf rund 100 Floating-Point-Berechnungen 36 Integer-Aufgaben.
-
 Nvidia Turing – Die Architektur im Detail (Bild: Nvidia)
Nvidia Turing – Die Architektur im Detail (Bild: Nvidia)

Die neuen Shadereinheiten können darüber hinaus mehr als nur Berechnungen im FP32-Format durchführen. Auch sind FP16-Befehle mit der doppelten Performance möglich (zwei FP16-Berechnungen werden auf einer FP32-ALU durchgeführt). Und auch Double Precision ist wieder mit an Bord. Allerdings gibt es auf Turing nur zwei FP64-Einheiten pro SM. Die Doppelte Genauigkeit wird also mit 1/32 der Leistung der einfachen Genauigkeit berechnet.
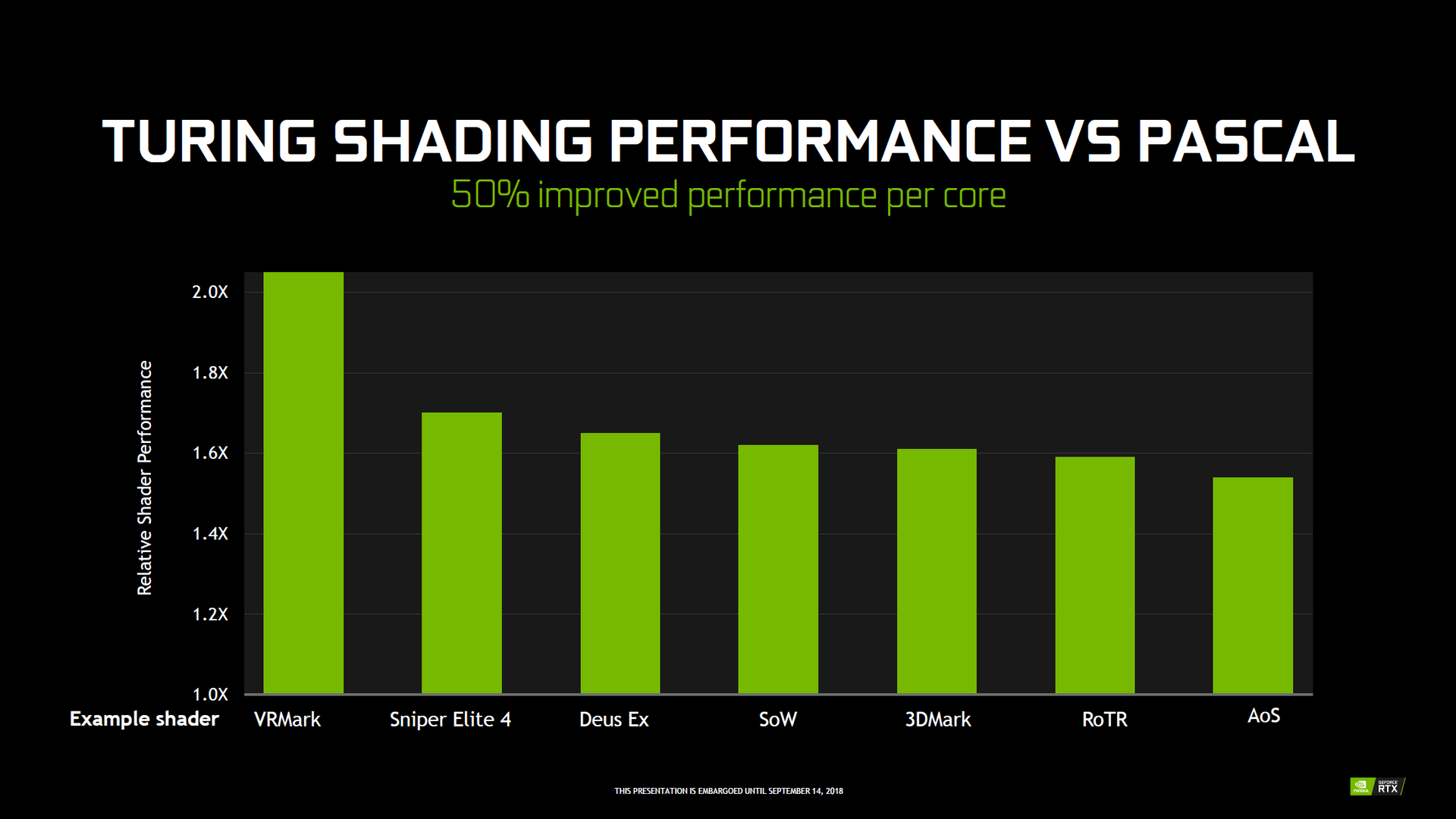
Turing-Shader mit 50 Prozent Leistungsvorteil
Pro SM gibt es darüber hinaus jetzt vier anstatt acht Textureinheiten, wobei aufgrund der halbierten Shaderanzahl pro SM das ALU:TMU-Verhältnis von Pascal geblieben ist. Dasselbe gilt für die Load-Store-Einheiten (16 pro SM bei Turing) und die Special-Function-Units (16 pro SM bei Turing). Durch die Änderungen der SM inklusive dem neuen Cache-Aufbau (siehe nächster Abschnitt) soll jede ALU von Turing etwa 50 Prozent schneller als bei Pascal arbeiten.
Tensor- und Raytracing-Kerne sind völlig neu an Turing
Bei Turing gibt es auch zwei ganz neue Einheiten in jeder SM. Zum einen haben die bisher Volta-exklusiven Tensor-Cores für KI-Berechnungen ihren Weg in Turing gefunden. Zum anderen nutzt Turing vollständig neue Raytracing-Kerne (RT-Cores).
Bei Turing gibt es pro SM acht Tensor-Cores und damit genauso viele wie bei Volta. Die Tensor-Cores bei Turing sind zwar nicht schneller, aber flexibler geworden. Sie können nicht mehr nur Matrizen-Berechnungen mit einer Genauigkeit von FP32 und FP16 durchführen, sondern ebenso mit INT8 und INT4 – bei einer entsprechend besseren Performance. Die Tensor-Cores selber sind eigentlich FP16-Einheiten, bei FP32-Befehlen arbeiten entsprechend zwei Einheiten an einer Ausführung. Spiele benötigen laut Nvidia meistens eine Genauigkeit von FP16. INT8 und INT4 sind primär für professionelle Anwendungen gedacht.
-
 Nvidia Turing – Die Architektur im Detail (Bild: Nvidia)
Nvidia Turing – Die Architektur im Detail (Bild: Nvidia)

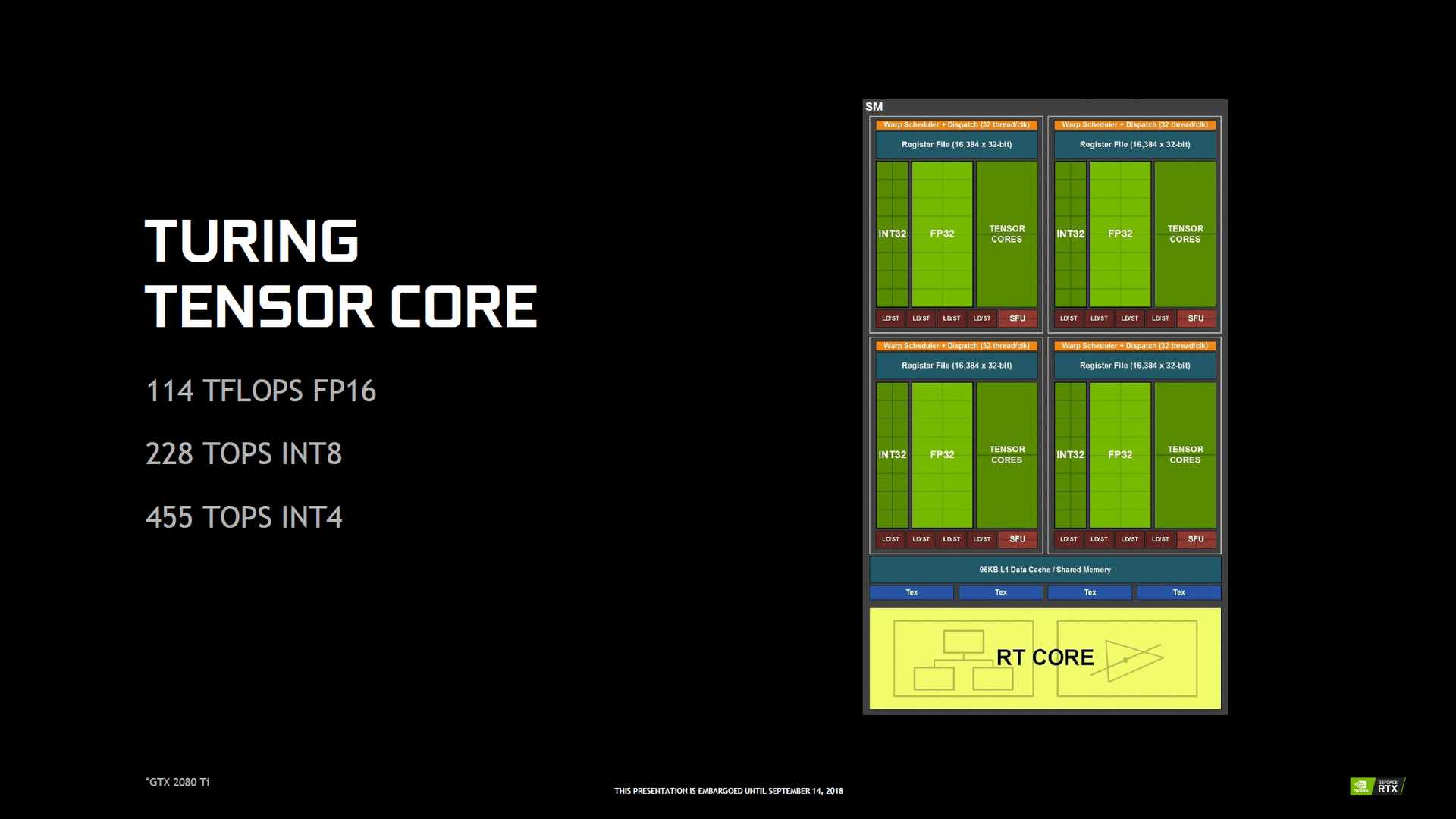
Der TU102 auf der GeForce RTX 2080 Ti kann über die normalen FP32-Einheiten FP16-Befehle mit einer theoretischen Rechenleistung von 26,9 TFLOPS ausführen. Die Rechenleistung von FP16 über die Tensor Cores liegt dagegen bei 107,6 TFLOPS – also um den Faktor 4 höher. Bei INT8 wird die Rechenleistung nochmals verdoppelt und bei INT4 vervierfacht.
Der RT-Kern in Turing beschleunigt wiederum das so genannte Bounding Volume Hierarchy (BVH) und das Ray/Triangle-Intersection-Testing (Ray Casting). Beides kann zwar genauso über die klassischen FP32-ALUs durchgeführt werden, aber auch hier ist der Geschwindigkeitsvorteil der dedizierten Einheiten entscheidend.
Der GP102 auf der GeForce GTX 1080 Ti erreicht durch die FP32-ALUs eine Performance von 1,1 Gigarays pro Sekunde. Der TU102 auf der GeForce RTX 2080 Ti kommt mit der besseren FP32-Leistung und vor allem den Raytracing-Kernen auf etwas über 10 Gigarays. Die Performance für Echtzeitraytracing wird mit Turing also etwa verzehnfacht. Die Leistungsangaben stammen aus einer Reihe von Raytracing-Benchmarks, die Nvidia selber vermessen hat.
-
 Nvidia Turing – Die Architektur im Detail (Bild: Nvidia)
Nvidia Turing – Die Architektur im Detail (Bild: Nvidia)
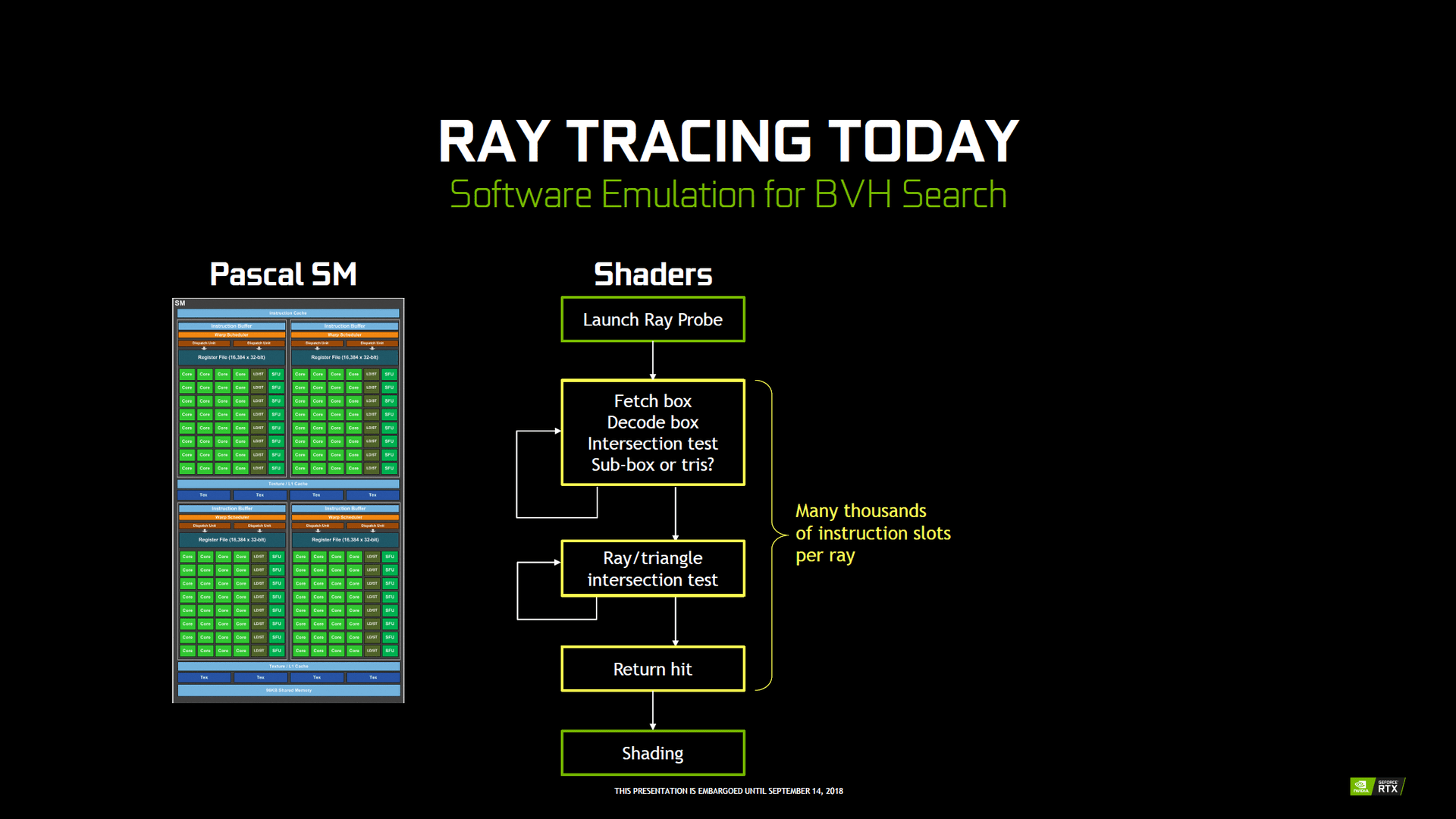
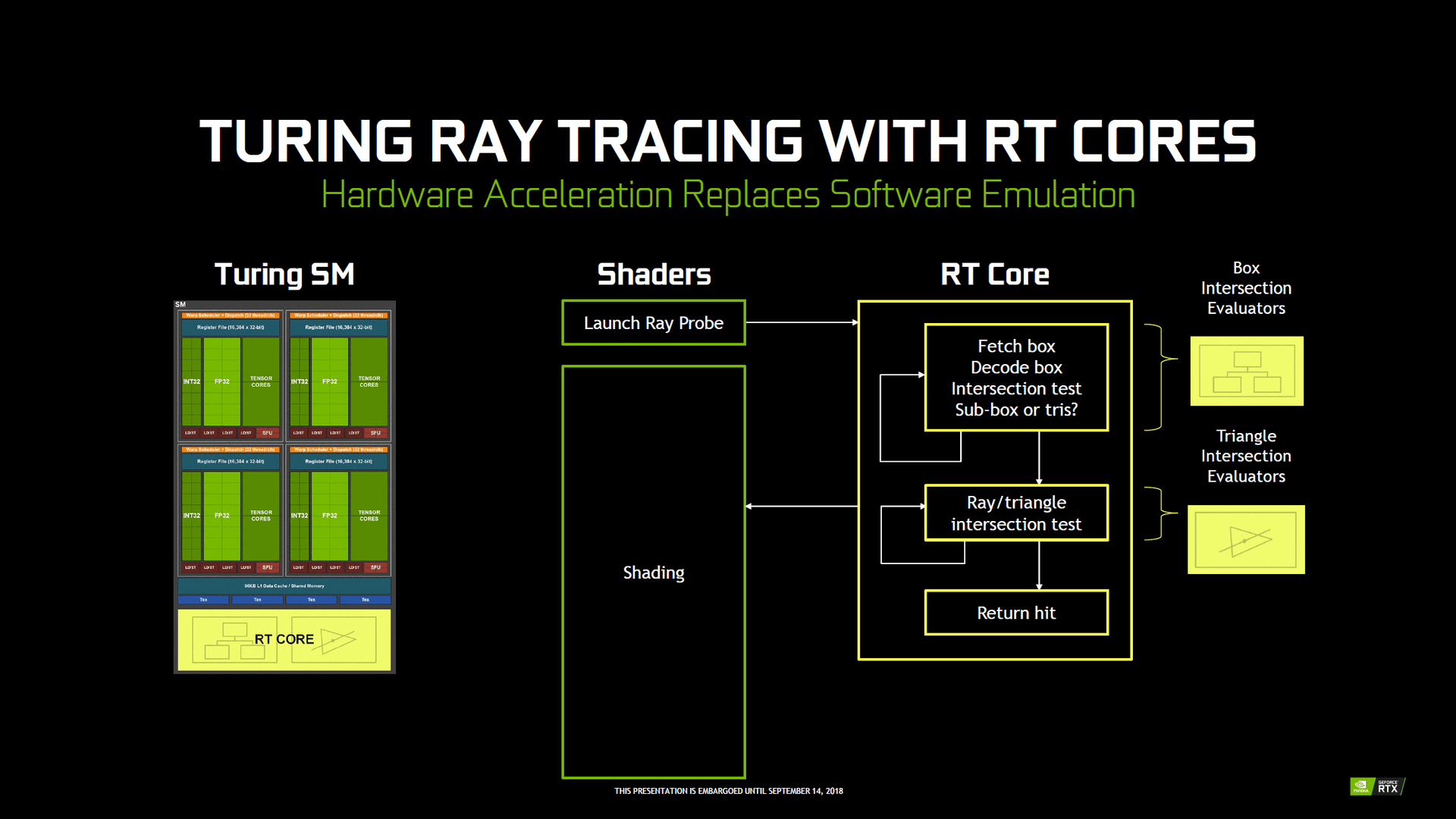

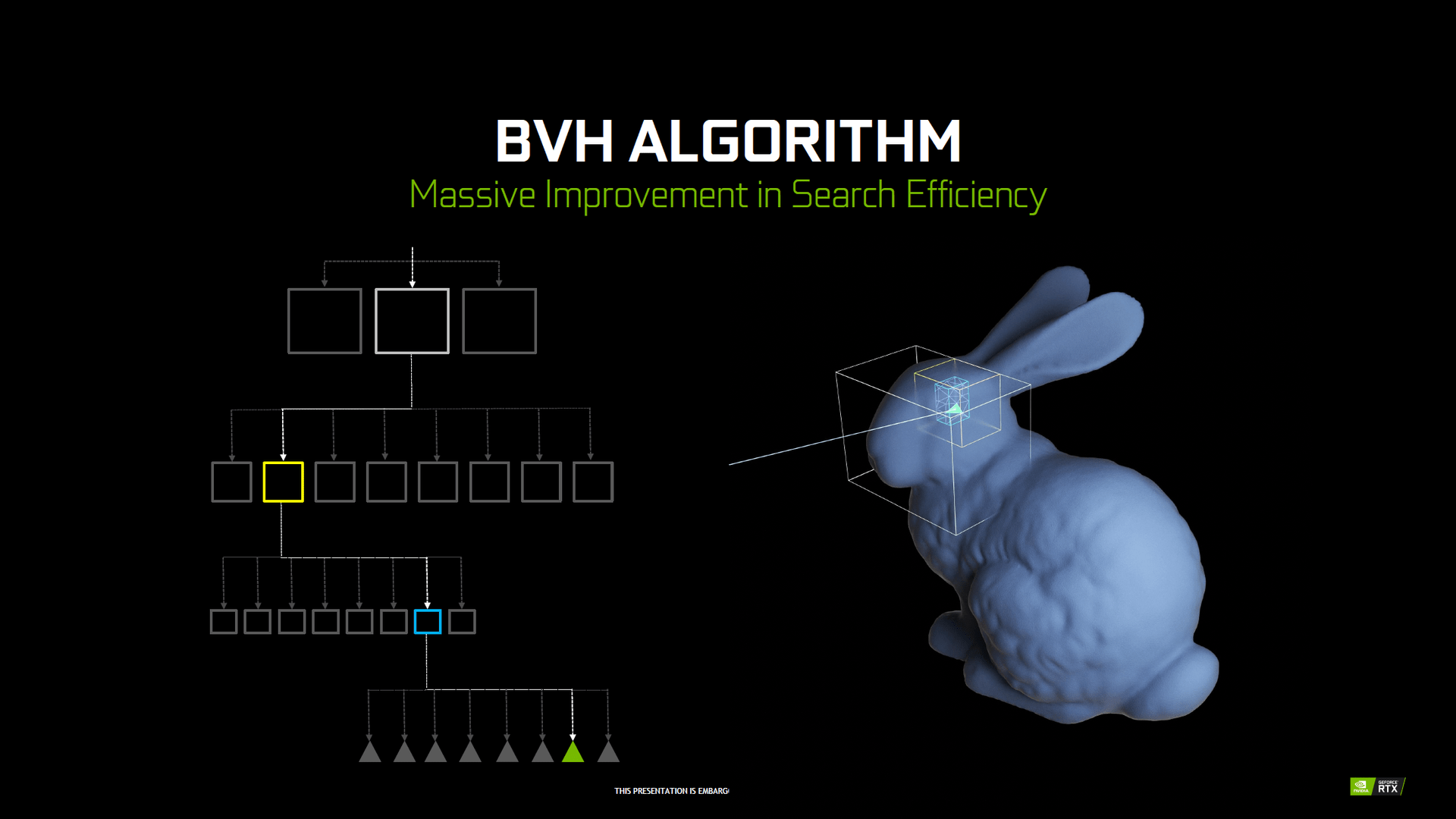
Da es heutzutage immer noch viel zu aufwendig ist, für jeden darzustellenden Pixel einen oder gleich mehrere Strahlen im Rahmen von Raytracing „abzuschießen“, teilen die RT-Kerne das Bild zunächst in größere dreidimensionale Boxen ein. Soll ein Polygon per Raytracing berechnet werden, muss zuerst getestet werden, ob dieses überhaupt sichtbar ist. Dazu wird das Frame in eine dreidimensionale Box eingeteilt, bei der dann geprüft wird, ob das Polygon sichtbar ist. Ist dies der Fall, wird die Box verkleinert und eine erneute Prüfung vollzogen – und dies wird mehrmals wiederholt, bis das Polygon dann selbst per Raytracing berechnet wird. Dadurch kann viel Rechenleistung gegenüber dem Prüfen jedes einzelnen Pixels eingespart werden. Die Einteilung in Boxen wird Bounding Volume Hierarchy (BVH) genannt, das Prüfen auf Sichtbarkeit Raycasting. Bei Raycasting handelt es sich also um eine simple Form des Raytracing, da keine weiterführenden Strahlen (Secondary Rays) genutzt werden.
Keine handfeste Aussage zum Platzbedarf der neuen Kerne
Turing-GPUs sind trotz neuer Fertigung extrem groß und bieten deutlich mehr Transistoren als Pascal-GPUs. Damit stellt sich die Frage, wie viel Platz die neuen Tensor- und Raytracing-Kerne benötigen. Eine handfeste Aussage liefert Nvidia dazu allerdings nicht. Laut Jonah Alben, SVP GPU Engineering, sind beide Einheiten zwar nicht riesig, aber auch nicht gerade klein.
Mehr Cache, GDDR6 und höhere Kompression
Nvidia hat auch den Cacheaufbau bei Turing sowohl innerhalb als auch außerhalb der SM überarbeitet. Der Registerspeicher bleibt zwar gleich: Jeder SM verfügt wie bei Pascal über einen 256 KB großen Registerspeicher pro SM. Der L2-Cache wächst mit 512 KB pro ROP-Partition (je 8 ROPs) hingegen an. Auf dem TU102 ist der L2-Cache mit 6.144 KB damit doppelt so groß wie auf dem GP102, dasselbe gilt für den TU104 gegenüber GP104 und auch den TU106 gegenüber GP106, denn der TU106 ist gegenüber dem TU104 bei den ROPs nicht beschnitten.
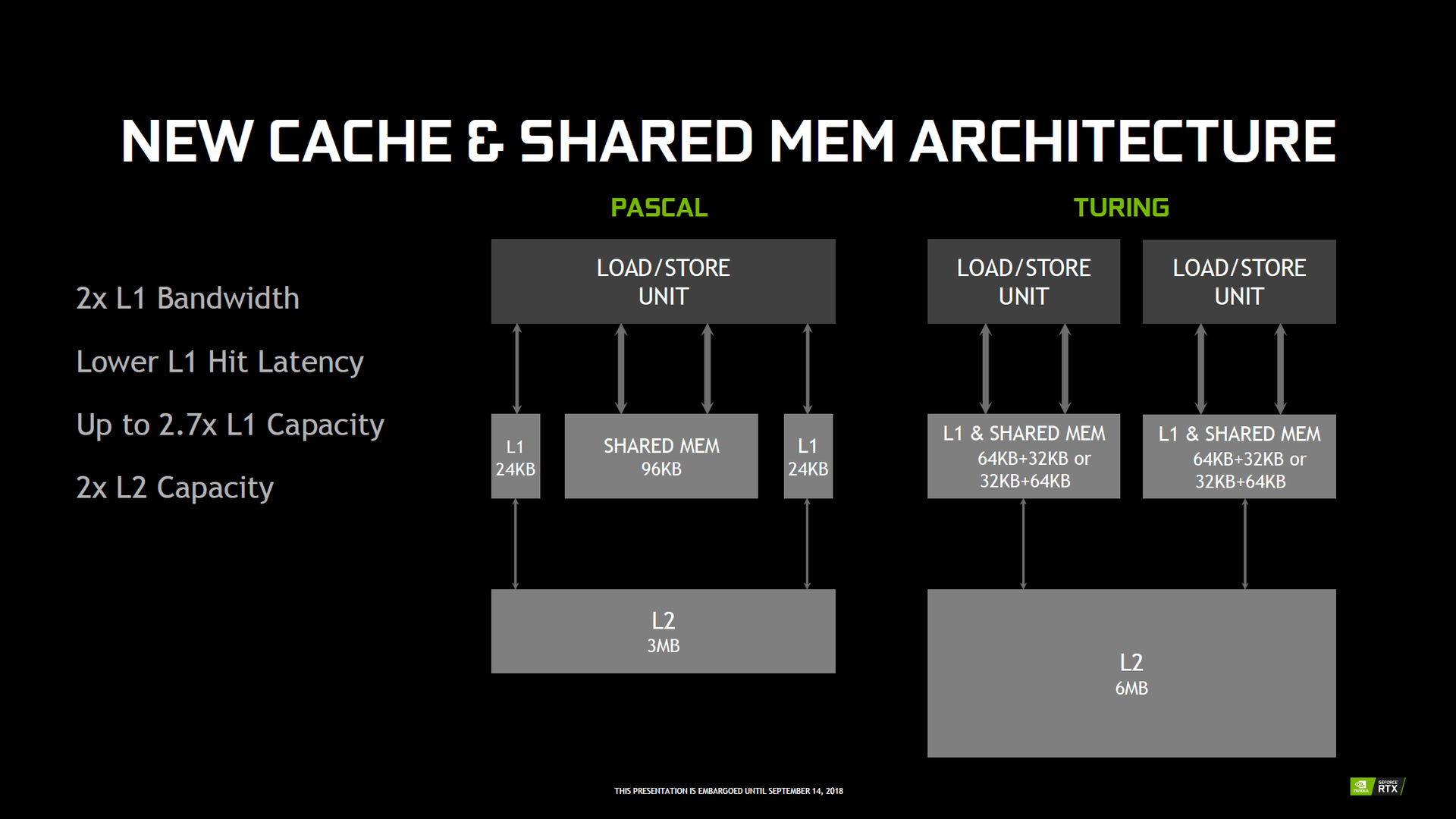
Auch beim L1-Cache und dem Shared Memory legt Turing zu und wird flexibler. So gibt es auf Pascal pro TPC zwei 24 KB große L1-Caches und einen 96 KB großen Shared Memory, in Summe also 144 KB. Bei Turing gibt es jetzt hingegen zwei 96 KB große „Cache-Blöcke“ pro TPC, die je nach Anforderungsprofil entweder mit einem je 64 KB großen L1-Cache und ein 32 KB großen Shared Memory, oder alternativ mit einem 32 KB großen L1-Cache und einen 64 KB großen Shared Memory arbeiten können. Darüber hinaus können der L1-Cache und der Shared Memory jetzt in den L2-Cache schreiben, vorher war dies nur für den L1-Cache möglich. Insgesamt sollen die Trefferquoten, also das Auffinden einer gesuchten Information im Cache, dadurch doppelt so hoch wie bei Pascal ausfallen, sich die Bandbreite verdoppeln und zugleich die Latenz reduzieren.
| GeForce RTX 2080 Ti | GeForce GTX 1080 Ti | GeForce RTX 2080 | GeForce GTX 1080 | GeForce RTX 2070 | GeForce GTX 1070 | |
|---|---|---|---|---|---|---|
| Register-File-Größe pro SM | 256 KB | 256 KB | 256 KB | 256 KB | 256 KB | 256 KB |
| Register-File-Größe insgesamt | 17.408 KB | 7.168 KB | 11.776 KB | 5.120 KB | 9.216 KB | 3.840 KB |
| L1-Cache + Shared Memory pro TPC | 192 KB | 144 KB | 192 KB | 144 KB | 192 KB | 144 KB |
| L1-Cache + Shared Memory insgesamt | 6.525 KB | 4.032 KB | 4.416 KB | 2.880 KB | 3.456 KB | 2.160 KB |
| L2-Cache | 5.632 KB | 2.816 KB | 4.096 KB | 2.048 KB | 4.096 KB | 2.048 KB |
GDDR6 und Kompression für 50 Prozent mehr Bandbreite
Auch beim Hauptspeicher gibt es Neuerungen, auch wenn der Aufbau des Interfaces im Vergleich der GPUs einer Klasse gleich geblieben ist. Allerdings unterstützt der Speichercontroller nun erstmals GDDR6, den Nvidia auf allen Turing-GPUs einsetzt. Bei den Quadro-Modellen stammt der Speicher von Samsung, bei den GeForce-RTX-Beschleunigern von Micron. Die Leistung liegt unabhängig vom Modell immer bei 14 Gbps, entsprechend taktet der Speicher immer mit 7.000 MHz. Die GeForce GTX 1080 Ti mit dem schnellsten Speicher ist bis heute die EVGA GTX 1080 Ti FTW3 Elite mit 6.000 MHz oder 12 gbps.
Um die effektive Bandbreite noch weiter zu erhöhen, hat Nvidia bei Turing die (verlustfreie) Speicherkompression verbessert. Diese soll je nach Spiel um die 20 bis 35 Prozent effektiver als beim Vorgänger arbeiten. In Verbindung mit dem schnelleren Speicher soll Turing im Schnitt also über 50 Prozent mehr effektive Bandbreite als Pascal verfügen.
-
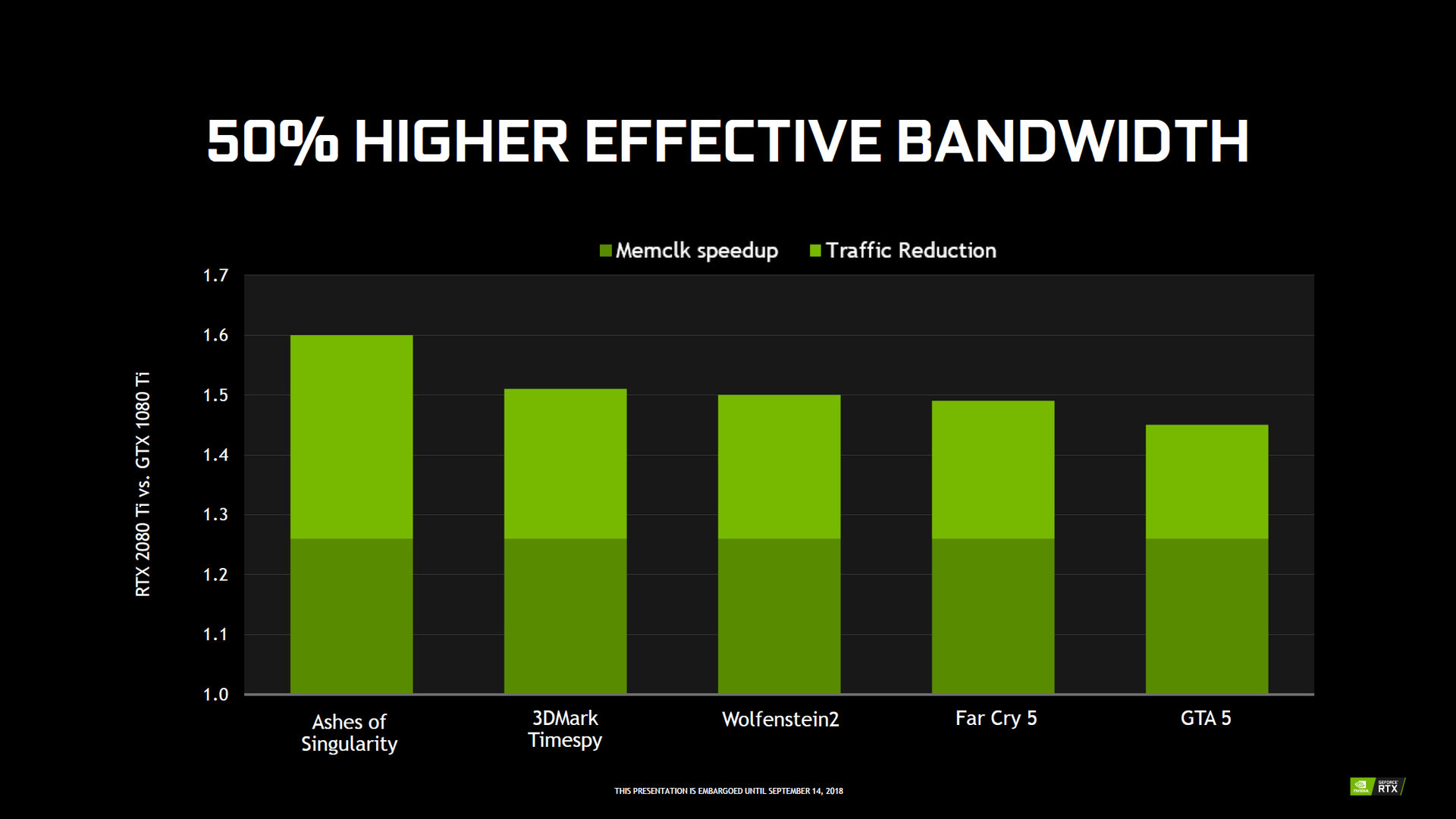 Nvidia Turing – Die Architektur im Detail (Bild: Nvidia)
Nvidia Turing – Die Architektur im Detail (Bild: Nvidia)
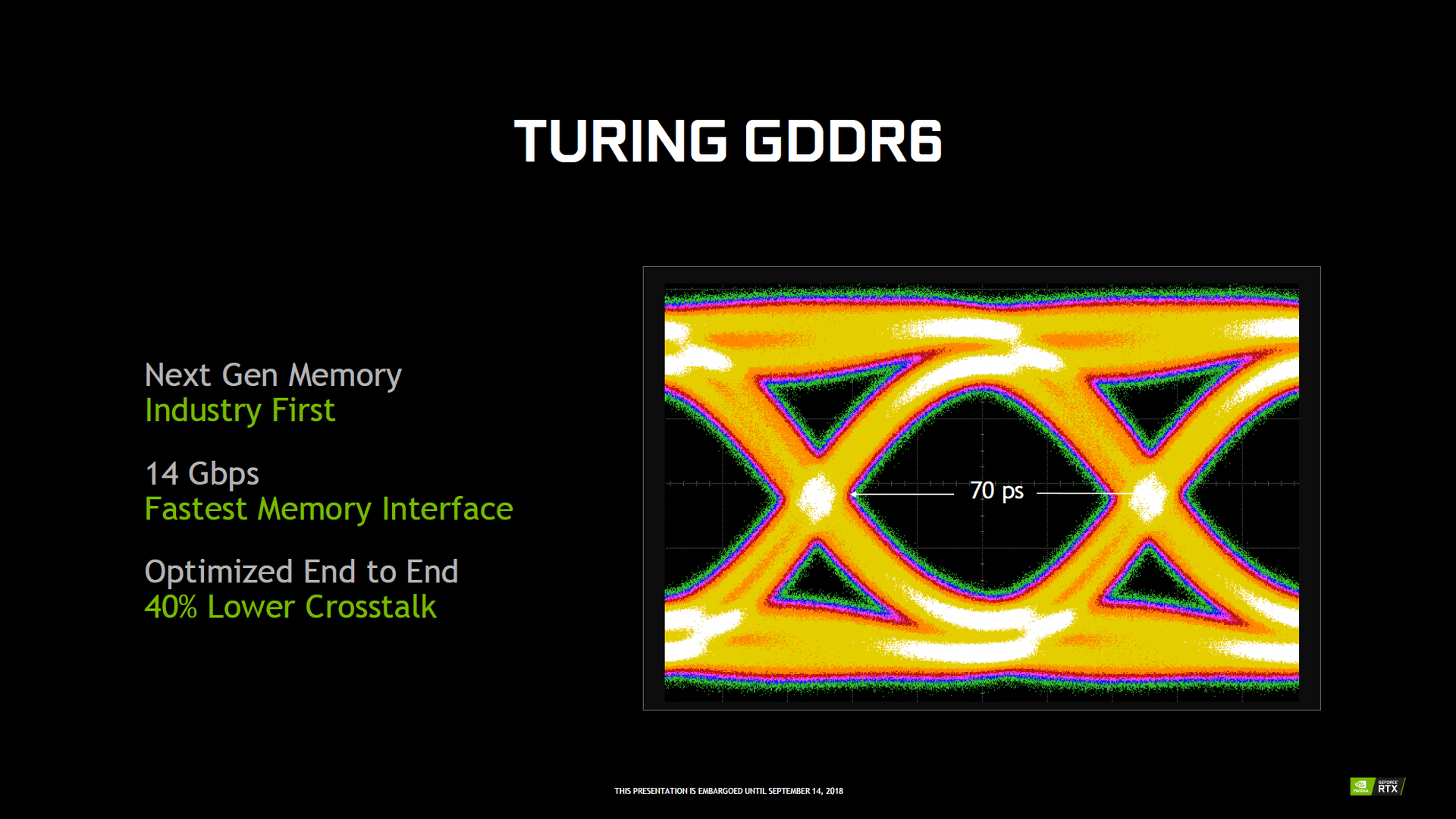
Abgesehen von einer höheren Bandbreite wurde bei GDDR6 das Clock-Gating verbessert. Deshalb soll der neue Speicher bei geringer Auslastung energieeffizienter als GDDR5(X) arbeiten – 20 Prozent Effizienzvorteil nennt Nvidia gegenüber Pascal.
VirtualLink, HDMI 2.0 und neue Video-Engine
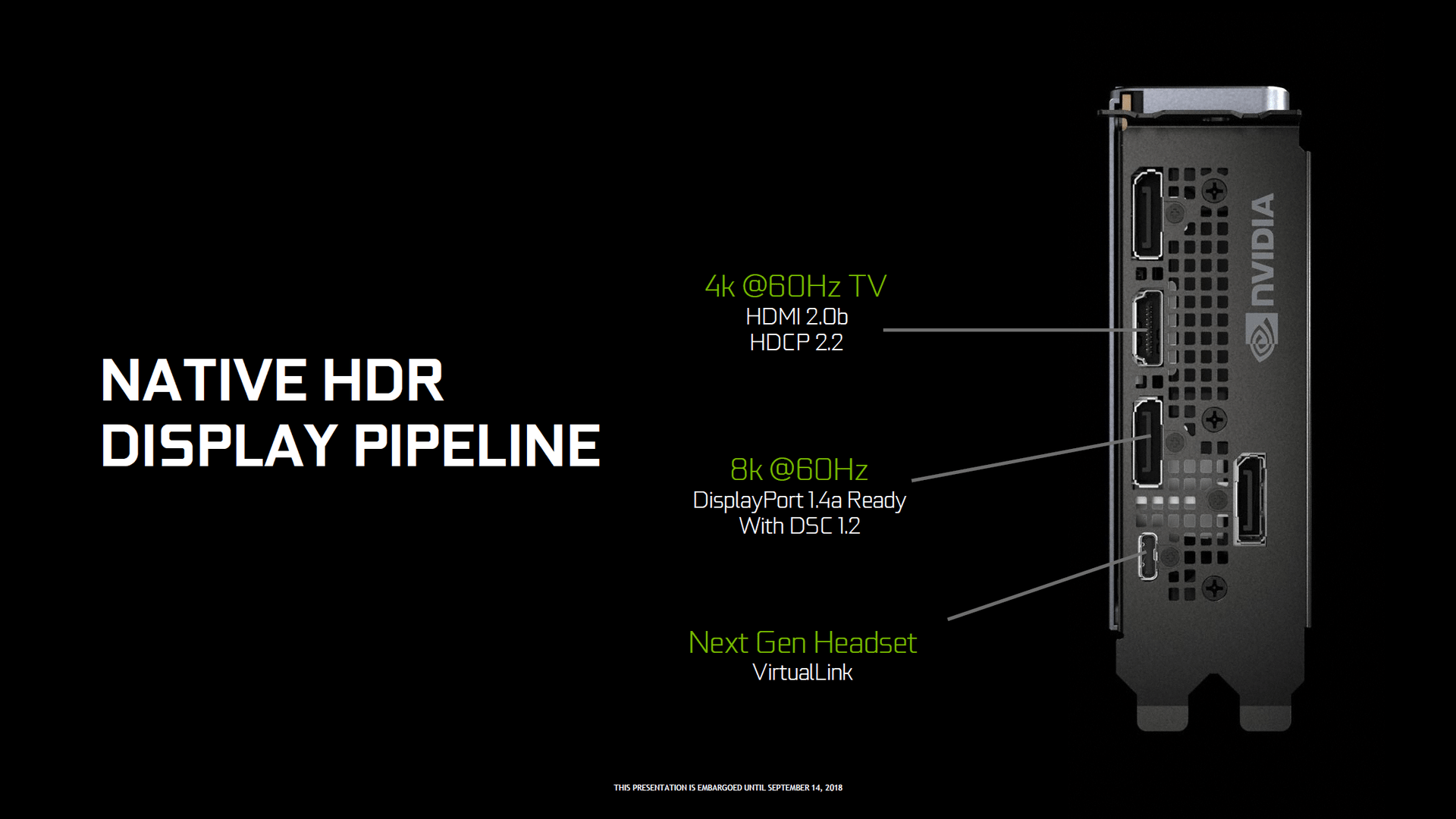
GeForce RTX 2070, GeForce RTX 2080 und GeForce RTX 2080 Ti sind die ersten Grafikkarten, die einen VirtualLink-Anschluss über USB Typ C aufweisen werden. An diesen können zukünftige VR-Headsets mit einem einzigen Kabel angeschlossen werden.
VirtualLink bietet vier HBR3-Links des DisplayPort-Standards inklusive einem Link SuperSpeed USB 3 für Motion Tracking. USB Typ C lässt dagegen nur entweder vier HBR3-Links oder zwei HBR3-Links plus zwei Links SuperSpeed USB 3 zu. Da VirtualLink auch Strom benötigt und liefert, kann der Anschluss bis zu 35 Watt zusätzlich von der Grafikkarte benötigen. Diese kommen bei Nutzung also maximal zusätzlich zu den offiziellen TDP-Angaben oben drauf.
Alle drei Turing-GPUs unterstützen DisplayPort 1.4a sowie HDMI 2.0b mit jeweils HDCP 2.2. Der neue HDMI-2.1-Standard wird also nicht unterstützt. Über DisplayPort 1.4a kann mit Hilfe der DSC-Kompression über ein Kabel ein 8K-Display mit 60 Hz und HDR angesteuert werden. Turing kann insgesamt zwei solcher Displays ansteuern. Auch der VirtualLink-Anschluss kann die 8K-Auflösung ausgeben.
-
 Nvidia Turing – Die Architektur im Detail (Bild: Nvidia)
Nvidia Turing – Die Architektur im Detail (Bild: Nvidia)
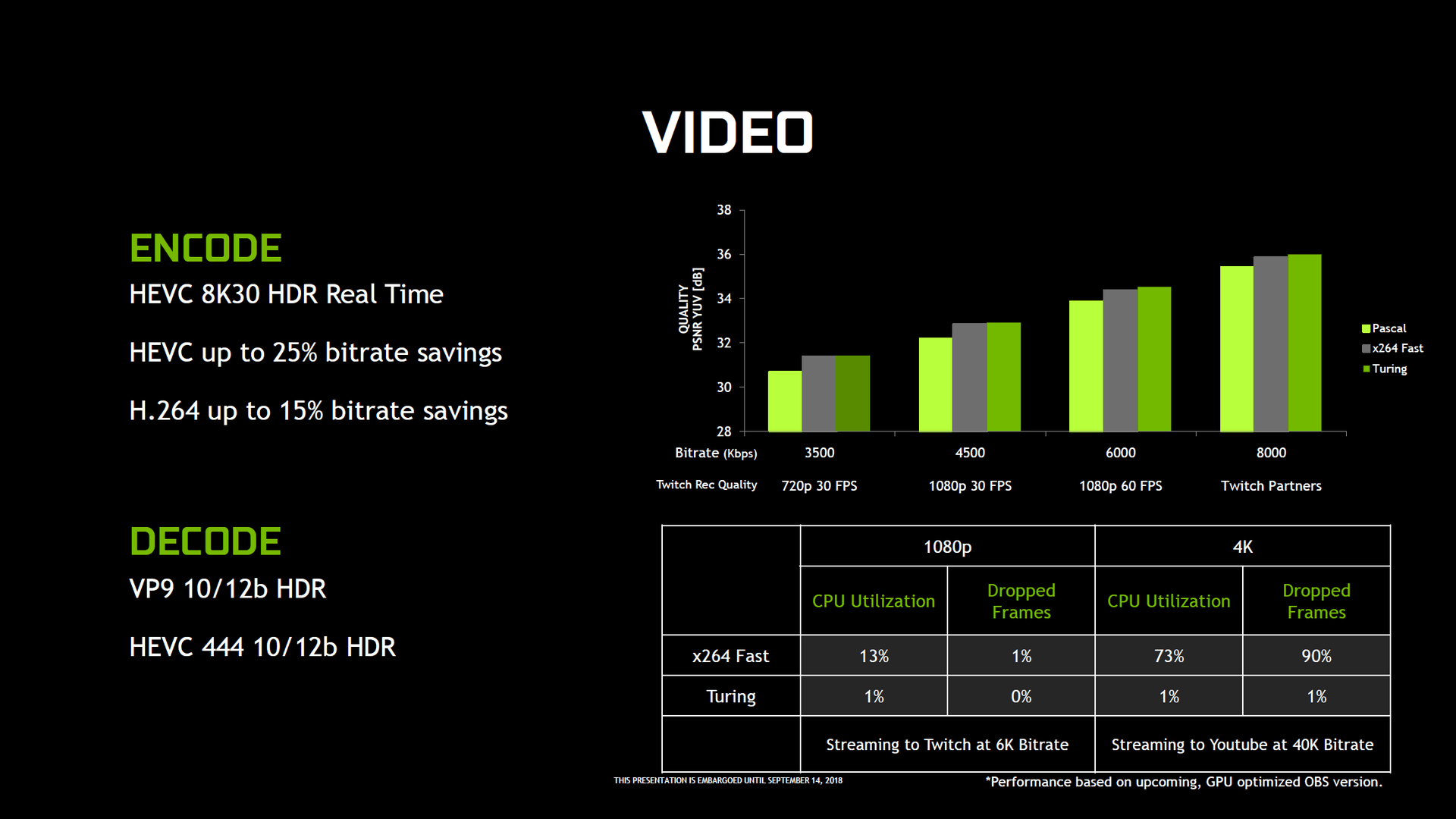
Auch bei der eingesetzten Video-Engine gibt es Verbesserungen gegenüber Pascal. Der NVENC genannte Encoder kann nun 8K-Videos mit dem HEVC-Codec (h.265) mit 30 FPS und HDR beschleunigen. Der Decoder unterstützt zudem den HEVC-Codec mit einer Farbabtastung von YUV444 bei 10 Bit oder 12 Bit HDR mit 30 FPS, den H.264-Codec mit 8K und den VP9-Codec mit 10 und 12 Bit HDR. Der Encoder soll darüber hinaus qualitativ gegenüber Pascal zugelegt haben und bei den üblichen Einstellungen für Streaming über Twitch und YouTube qualitativ besser als der Software-Renderer abschneiden.