Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
ich stehe vor folgendem Problem und komme einfach nicht weiter.
Meine Tabelle sieht folgendermaßen aus:
ID Wert1 Wert2
1 x t
1 x NULL
1 y b
2 NULL c
2 NULL NULL
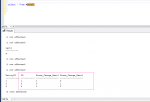
Ich möchte gerne zählen, wie oft sich die aufeinander folgenden Werte innerhalb eines Attributs (Wert1, Wert2) pro ID ändert. Die Ausgabe soll so aussehen:
Mit count distinct geht es ja nicht, da ich nicht die Anzahl der unterschiedlichen Einträge haben möchte, sondern wie oft sich ein Wert innerhalb eines Attributs (pro ID) ändert. z.B. wenn ich x y x y habe, sind das ausgehend vom ersten x als Anfangswert drei Änderungen.
Die Anzahl der Änderungen entspricht doch der Anzahl der Werte minus Eins, oder?
Falls es aber tatsächlich um Änderungen anhand einer Reihenfolge der Einträge geht (das Ausgangsposting könnte man auch so interpretieren)... das wird mit SQL schwierig, für Datenbanken sind Tabellen erst mal unsortierte Mengen, die man nur für die Ausgabe am Schluss in eine Reihenfolge bringen kann... mir würde da nur ein Weg über eine Stored Procedure mit einem Cursor einfallen.
Das was du hier hast ist eher eine logische Verknüpfung der Daten, die an eine Bedingung gekoppelt ist. D.h. entweder Auslagern der Logik in die verarbeitende Anwendung oder mit einem Cursor arbeiten.
Also wenn es für dich möglich ist, dann würde ich mir den ganzen Sernon in ein Array laden und dann mit einer foreach-Schleife und Hilfsarrays die Daten verarbeiten. Da spart man sich unglaublich viele Nerven. Ansonsten wenn du firm mit Cursorn bist kannst du das natürlich auch damit umsetzen. Ob das mit normalen SQL Statements so ohne weiteres machbar ist bezweifle ich gerade.
Die Anzahl der Änderungen entspricht doch der Anzahl der Werte minus Eins, oder?
Falls es aber tatsächlich um Änderungen anhand einer Reihenfolge der Einträge geht (das Ausgangsposting könnte man auch so interpretieren)... das wird mit SQL schwierig, für Datenbanken sind Tabellen erst mal unsortierte Mengen, die man nur für die Ausgabe am Schluss in eine Reihenfolge bringen kann... mir würde da nur ein Weg über eine Stored Procedure mit einem Cursor einfallen.
Das was du hier hast ist eher eine logische Verknüpfung der Daten, die an eine Bedingung gekoppelt ist. D.h. entweder Auslagern der Logik in die verarbeitende Anwendung oder mit einem Cursor arbeiten.
Also wenn es bspw. MySQL und PHP ist dann würde ich mir den ganzen Sernon per mysqli in ein Array laden und dann mit einer foreach-Schleife und Hilfsarrays die Daten verarbeiten.
Ich habe eine Menge von IDs und die dazugehörigen Datensätze. Zu diesen gehört auch ein Datum. Nun möchte ich nach IDs gruppiert die Menge der Änderungen pro Spalte haben.
Meine Ausgangssituation
ID-------Spalte 1---------Spalte3
1-------- x --------------Datum1 (Mein Ausgangspunkt)
1--------y--------------- Datum2 (erste Änderung)
1--------NULL --------- Datum 3 (zweite Änderung)
Schön isses nicht, aber es läuft und gibt aus was du willst.. Kann sicher noch vereinfacht werden, aber darauf habe ich keine Lust mehr.
.. und, nimms nicht persönlich; hätte ich vorher gesehen, dass di dich extra für "löse dein Problem" hier angemeldet hättest; hätte ich es wohl auch nicht gemacht, da man bei sowas zu 90% danach nichts mehr von den Leuten hört; außer sie haben probleme... whatever, da ichs ja nun schon habe:
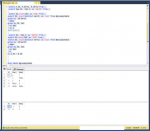
INSERT INTO #groupbytable
SELECT 1,'x','t' UNION ALL
SELECT 1,'x','NULL' UNION ALL
SELECT 1,'y','b' UNION ALL
SELECT 2,'NULL','c' UNION ALL
SELECT 2,'NULL','NULL'
select * from #groupbytable
select A.ID, A.Wert1, B.Wert2 from (
select tmp.ID, (CW1-1) as 'Wert1' from (
select ID,count(CW1) as 'CW1' from (
select ID, count(distinct Wert1) as 'cw1' from #groupbytable
group by ID,Wert1
) tmpa
group by ID, CW1
) as tmp
) as A
left join (
select ID, (CW2-1) as 'Wert2' from (
select ID,count(CW2) as 'CW2' from (
select ID, count(distinct Wert2) as 'cw2' from #groupbytable
group by ID,Wert2
) tmpb
group by ID, CW2
) as tmp
) B
on A.ID = B.ID
drop table #groupbytable
und das im Anhang kommt raus...
Ergänzung ()
Anhang
Ergänzung ()
Anmerkung 2: Ich habe das nochmal mit echtem NULL statt 'NULL' probiert, da gehts wohl nicht so einfach.
Der Workaround wäre dass du es genauso wie ich in eine temp DB reinschreibst und die Spalten mit NULL durch einen ungültigen Wert auffüllt. Dafür müsstest du dir deine Daten mal anschauen und dann klappt das schon. Aber da gibt es sicher noch andere Möglichkeiten. Das Problem ist, dass in deinem Beispiel auch nicht erkenntlich ist, ob in der DB ein "NULL" oder NULL drinnen steht.
boah hast recht; hab ich garnicht genau gelesen. was ist denn das für eine Schwachsinnige Anforderung an einer Datenbank. Sowas geht dann wohl nur indem man eine Hilsspalte einführt mit einer fortlaufenden ID und dann mit einem While LOOP das ganze durchparst...
Ich würde hier aber nochmal die gestellte Anforderung hinterfragen; da sowas i.d.R. schwachsinnige Anforderungen sind.
Ergänzung ()
Dreckscode hoch tausend.. aber läuft.. siehe Anhang
Hab noch zu Testzwecken die Testdaten angereichert...
Ergänzung ()
Hier der Code:
Code:
IF OBJECT_ID('tempdb..#sourcetable') IS NOT NULL DROP Table #sourcetable
IF OBJECT_ID('tempdb..#tmptable') IS NOT NULL DROP Table #tmptable
IF OBJECT_ID('tempdb..#result') IS NOT NULL DROP Table #result
IF OBJECT_ID('tempdb..#result_tmp') IS NOT NULL DROP Table #result_tmp
create table #sourcetable
(
ID int,
Wert1 nvarchar(10),
Wert2 nvarchar(10)
)
create table #tmptable
(
RowNo int,
ID int,
Wert1 nvarchar(10),
Wert2 nvarchar(10)
)
create table #result_tmp
(
ID int
)
create table #result
(
EntityID int,
ID int,
State_Change_Wert1 int,
State_Change_Wert2 int
)
INSERT INTO #sourcetable
SELECT 1,'x','t' UNION ALL
SELECT 1,'x',NULL UNION ALL
SELECT 1,'y','b' UNION ALL
SELECT 2,NULL,'c' UNION ALL
SELECT 2,NULL,NULL UNION ALL
SELECT 4,'x','t' UNION ALL
SELECT 4,'x',NULL UNION ALL
SELECT 4,'y','b'
select * from #sourcetable
insert into #tmptable (RowNo,ID,Wert1,Wert2)
select row_number() over(order by id),ID,Wert1,Wert2
from #sourcetable
update #tmptable set Wert1 = 'UNGUELTIG' where Wert1 is NULL
update #tmptable set Wert2 = 'UNGUELTIG' where Wert2 is NULL
insert into #result_tmp (ID)
select distinct ID
from #sourcetable
insert into #result (EntityID,ID)
select row_number() over(order by id),ID
from #result_tmp
DECLARE @i INT;
DECLARE @max INT;
DECLARE @tmp int;
DECLARE @changes_w1 INT;
DECLARE @changes_w2 INT;
DECLARE @laststate_w1 nvarchar(10);
DECLARE @laststate_w2 nvarchar(10);
DECLARE @i_result int;
DECLARE @max_result int;
set @max = (select max(RowNo) from #tmptable);
set @i_result = 1;
set @max_result = (select max(EntityID) from #result);
WHILE @i_result <= @max_result
begin
set @tmp = (select ID from #result where @i_result = EntityID);
set @laststate_w1 = (select wert1 from #tmptable where RowNo in (select min(RowNo) from #tmptable where ID = @tmp));
set @laststate_w2 = (select wert2 from #tmptable where RowNo in (select min(RowNo) from #tmptable where ID = @tmp));
SET @i = (select min(RowNo) from #tmptable where ID = @tmp) + 1;
set @changes_w1 = 0;
set @changes_w2 = 0;
WHILE @i <= @max
BEGIN
if @tmp = (select ID from #tmptable where RowNo = @i)
BEGIN
IF @laststate_w1 <> (select Wert1 from #tmptable where RowNo = @i)
BEGIN
set @laststate_w1 = (select Wert1 from #tmptable where RowNo = @i);
set @changes_w1 = @changes_w1 + 1;
END
IF @laststate_w2 <> (select Wert2 from #tmptable where RowNo = @i)
BEGIN
set @laststate_w2 = (select Wert2 from #tmptable where RowNo = @i);
set @changes_w2 = @changes_w2 + 1;
END
END
SET @i = @i + 1;
END;
update #result set State_Change_Wert1 = @changes_w1 where EntityId = @i_result;
update #result set State_Change_Wert2 = @changes_w2 where EntityId = @i_result;
set @i_result = @i_result + 1;
end --result lopp
select * from #result
joa ist aber nicht unbedingt immer die eigene Schuld. Da wo ich arbeite haben wir z.b. keine relationen in der Datenbank mittels primary/foreign key abgelegt - das macht alles die Programmlogik je nachdem was gerade abgebildet werden soll.
da kommt man mit solchen 0815 Datenbankkonzepten nicht weit, und da muss ich auch oft solche Auswertungen fahren weil irgendwer das als report haben muss.
meiner Meinung nach lässt sich das Problem in dieser Datenstruktur überhaupt nicht lösen.
In einer SQL-Tabelle haben die Einträge per Definition keine Reihenfolge - woher soll dann die Reihenfolge kommen, nach der der Wechsel der Einträge bestimmt wird.
Führe ich ein Select auf den Wert1 aus, kommt je nach Lust und Laune des Optimizers x-x-y oder mal x-y-x, ... raus.
Um die Problemstellung lösen zu können sollte tatsächlich noch eine weitere Spalte mit einer weiteren Id oder einem Zeitstempel oder Sonstwas, was innerhalb der Id eine Reihenfolge vorgibt.
per default sind aber z.b. in oracle die sequenzen, die zur bestimmung der eindeutigen ID (meist prim key) generiert werden - aufsteigend und 'not cycling' - daher hat man zumindest in oracle eine eindeutige sortierung nach erstellungszeitpunkt (nicht änderungszeitpunkt) der Zeile...
muss nicht so sein, ist aber meist so. daher auch das (order by id) woraus er die rownum generiert. für sich allein ist rownum wirklich kein absolutes kriterium für eine reihenfolge.
Ja, auf irgendwas musst du dich da verlassen. Dafür halt das ROW_NUMBER ; aber wenn das nicht konstant ist kann man da nichts machen. Ein Zeitstempel oder o.ä. ; über den man rankt wäre natürlich besser.
Ich vermute aber stark, dass MS SQL da im hintergrund noch irgendwelche Timestamps hat über der im Zweifel rankt; so dass das praktisch aufs gleiche ruasläuft.
@corto: Mit den PrimaryKeys hast du im Prinzip recht, das würde auch in MsSQL funktionieren - aber die Tabelle des TE enthält eben keinen PrimaryKey. Ebenso könnte man eine Identity-Spalte der Tabelle hinzufügen, die automatisch beim Insert den nächst höheren Wert einträgt und darüber eine Reihenfolge sicher stellt.
@pizza4ever: wenn du bei MsSQL die Row_Number nutzt musst Du zwingend den Over-Clause mit angeben, der dann definiert, nach welcher Spalte/Funktion sortiert werden soll um die Reo_Numder zu generieren.
Das eiinzige was von Haus aus evtl. für eine Reihenfolge taugen könnte ist die physikalische Adresse der Tabellenzeile über %%physloc%%. Diese ist immer für jede Zeile eindeutig, aber ob sie tatsächlich aufsteigend nach dem Zeitpunkt des Inserts ist, weiss ich nicht.