ATi Radeon HD 2900 XT im Test: Platzhirsch oder kleiner Bruder der GeForce 8800?
3/38Technik im Detail Part 1
Allgemeines:
Nach einer langen Zeit des Wartens ist das Geheimnis nun gelüftet: Wie sieht die neue R600-GPU von ATi aus? Wie funktioniert diese? Wie viele Einheiten hat sie? Wie schnell kann sie damit sein? Was kann sie Besonderes? Nachdem bereits über mehrere Monate hinweg diverse Male mehr oder weniger richtige Gerüchte den Weg in das World Wide Web gefunden hatten, herrscht nun (zumindest größtenteils) Gewissheit. Schauen wir uns den R600 sowie dessen Ableger RV630 und RV610 einmal genauer an. Der R600, der auf dem Flaggschiff Radeon HD 2900 XT verbaut wird, setzt sich aus etwa 700 Millionen Transistoren zusammen und wird in einem speziell für ATi entwickelten 80-nm-Prozess bei TSMC mit der Bezeichnung „80HS“ gefertigt. Anders als manche Gerüchte glauben machen möchten, wird ein R600 im kleineren 65-nm-Prozess erst mit einer späteren Chipversion erscheinen. Anders dagegen die kleineren Brüder der R600-Familie, die schon jetzt in der 65-nm-Größe produziert werden. Das Mid-Range-Produkt RV630 („65+“; Radeon HD 2600 Pro und Radeon HD 2600 XT) ist 390 Millionen Transistoren groß, während die Low-End-Variante RV610 („65+“; Radeon HD 2400 Pro und Radeon HD 2400 XT) aus 180 Millionen Transistoren besteht.
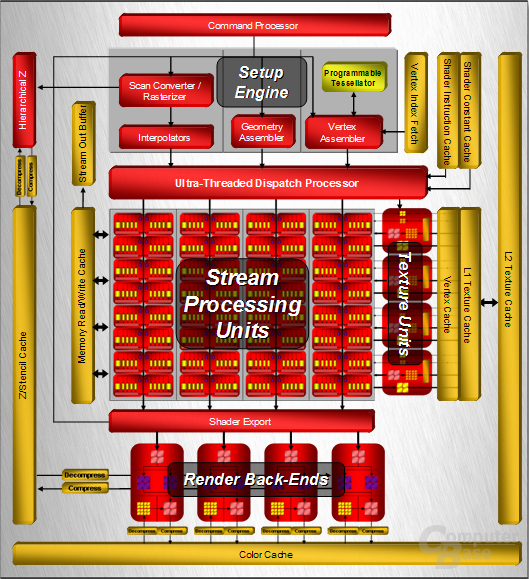
Alle drei Grafikchips sind mit einer Unified-Shader-Architektur (USA) ausgerüstet, weswegen es keine separaten Pixel-, Vertex- sowie die in der Direct3D-10-API neu hinzugekommenen Geometry-Shadereinheiten mehr gibt. Stattdessen sind die Arithmetic Logical Units (ALU) dazu in der Lage, alle drei möglichen Berechnungsarten nacheinander auszuführen, weswegen es zumindest theoretisch keinen Leerlauf der ALUs mehr gibt. Bei der klassischen Architektur mit getrennten Shadereinheiten ist es dagegen des Öfteren der Fall, dass beispielsweise alle Pixelshadereinheiten während eines Taktes maximal ausgelastet sind, während die Vertexshader Däumchen drehen. Dass der ATi R600 (wir bezeichnen im Text die gesamte R600-Familie allgemein als R600, obwohl dessen Derivate RV630 sowie RV610 ebenfalls gemeint sind) kompatibel mit der Direct3D-10-API ist, muss an dieser Stelle kaum noch erwähnt werden.
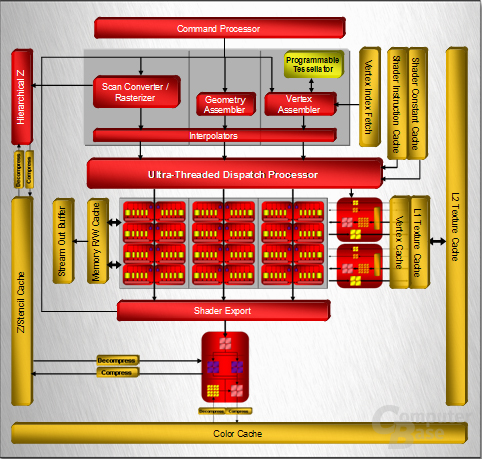
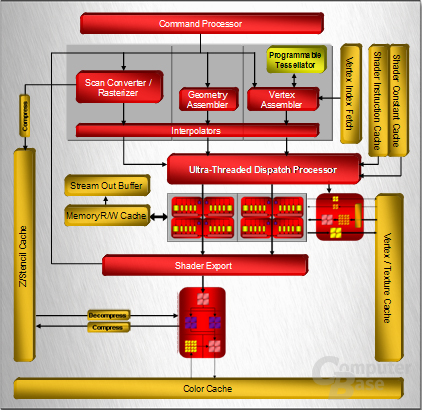
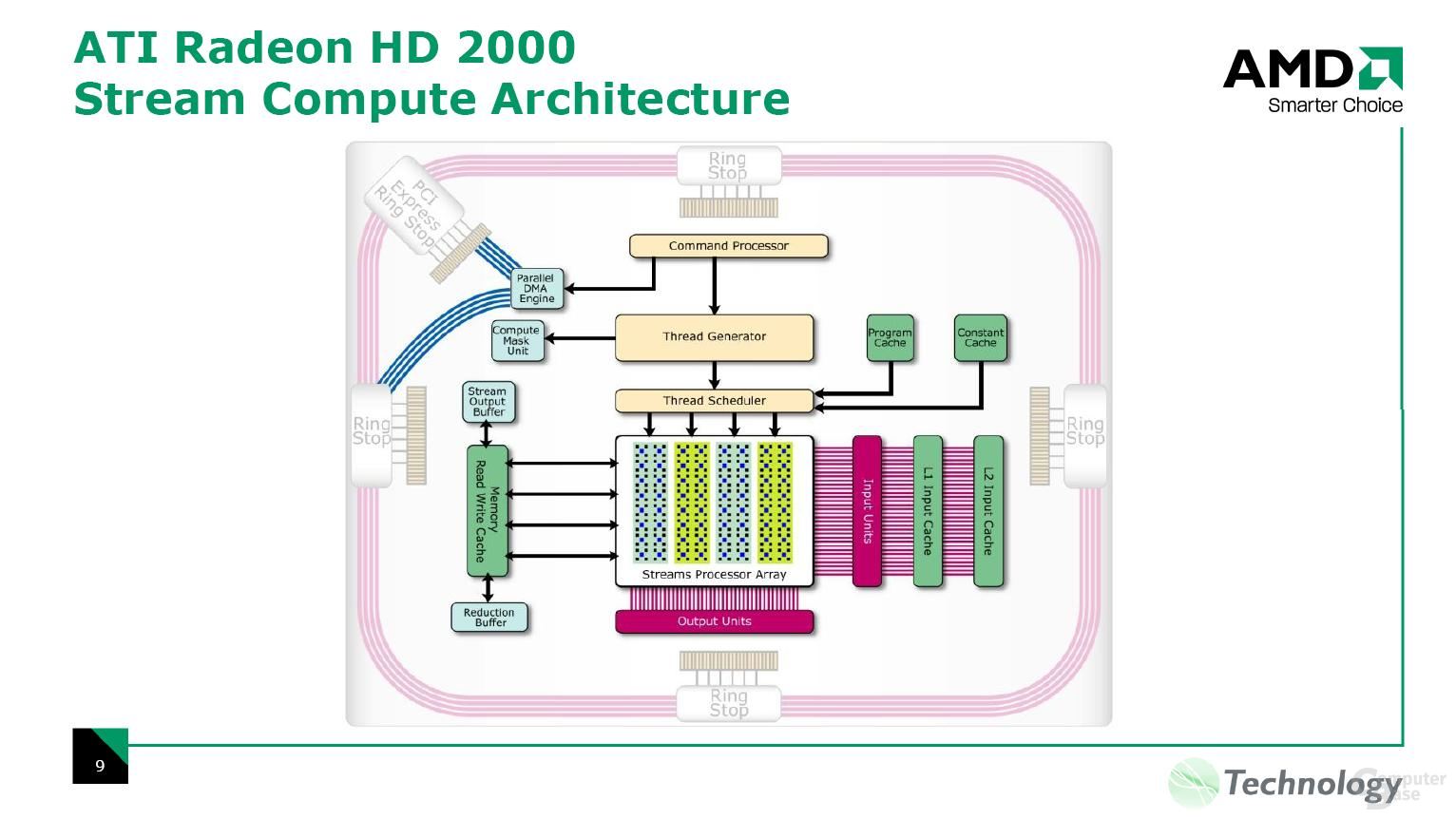
Die Entwicklung vom R600 begann im Jahre 2003, womit die GPU fünf Jahre lang im Labor verbracht hat. Das Chipdesign orientiert sich nach eigenen Angaben an dem Xenos, dem 3D-Beschleuniger in der Xbox 360, wobei sich im Laufe der Zeit einige Sachen geändert haben. Die Grundarchitektur ist zwar dieselbe geblieben, viele Einzelheiten sind jedoch modifiziert worden, da sich die Anforderungen einer PC-Grafikkarte von denen einer Spielekonsole unterscheiden. Nun kurz zu den technischen Spezifikationen, wobei wir auf diese im weiteren Verlauf des Textes genauer eingehen werden. Der R600 bietet dem Kunden je nach Zählweise 320 oder 64 Shadereinheiten, wobei sich diese von den ALUs in einem R580 sowie dem G80 von nVidia unterscheiden – alleine deswegen wird schon deutlich, dass man nur durch das Wissen um die Anzahl der Einheiten die Leistung nicht miteinander vergleichen kann. Die Texture Mapping Units stagnieren bei 16, wobei die Funktionalität gegenüber den TMUs des R580 aufgebohrt worden ist. Ebenso sieht es bei den Raster Operation Processors aus, deren Anzahl erneut bei 16 Einheiten liegt. Der Speicherbus wurde auf ein 512-Bit-Interface verdoppelt. Etwas überraschend ist die verbaute Tessellation-Einheit im R600, die über den Direct3D-10-Standard hinausgeht und eigentlich erst in der D3D11-Spezifikation vorgeschrieben ist. Schauen wir uns nun die einzelnen Komponenten des R600 etwas genauer im Detail an.
Ultra-Threaded Dispatch Processor:
Den Anfang der Datenberechnungen im R600 macht der so genannte „Command Processor“ bevor die Daten unter anderem zu den ALUs gelangen. Dieser nimmt die Befehle vom Grafikkartentreiber entgegen und führt den vom Treiber generierten Microcode aus. Damit übernimmt der Command Processor eine Aufgabe von der CPU. Der Overhead des Prozessors soll laut ATi um 30 Prozent niedriger ausfallen als noch bei der R5x0-Generation. Anschließend gelangen die Daten in die „Setup Engine“, die die Bits für die Berechnungen in die Stream Processing Units vorbereitet. Je nach Art der Berechnung, ob ein Pixel- Vertex- oder Geometry-Programm ansteht, wird diese von einer anderen Einheit verwaltet, wobei diese nach Fertigstellung in den von der Radeon-1000-Serie bekannten „Ultra-Threaded Dispatch Processor“ gelangen. Der „Verteilerprozessor“ sorgt dafür, dass die ALUs möglichst maximal ausgelastet werden und keine „Blasen“, sprich Leerlauf der ALUs, auftreten.
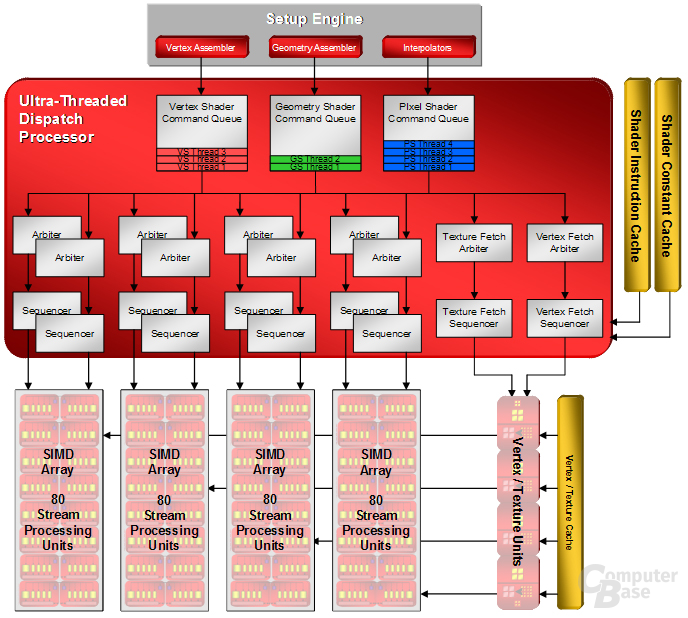
Der Ultra-Threaded Dispatch Processor erstellt einzelne Threads, die aus mehreren Befehlen bestehen. Dabei werden mehrere Threads gesammelt, ohne diese direkt an die ALUs, die sich beim R600 aus vier SIMD-Einheiten (Single Instruction Multiple Data, sprich ein Befehl wird auf mehrere Daten gleichzeitig angewendet) zusammensetzen, weiterzuleiten. Pro SIMD gibt es zwei „Arbiter“, die die Threads in einer ausgesuchten Reihenfolge den ALUs zusenden. Damit befinden sich immer zwei Operationen zur selben Zeit in den Shadereinheiten. Falls Befehle mit einer hohen Priorität anfallen, können die sich derzeit in der ALU befindlichen Operationen „geparkt“ und zu einem späteren Zeitpunkt fortgesetzt werden. Der Ultra-Threaded Dispatch Processor kann auf zwei verschiedene Zwischenspeicher zurückgreifen, wobei die genaue Größe unbekannt ist. Der „Shader Constant Cache“ ermöglicht es eine unendliche Anzahl an Konstanten (Konstanten sind Elemente, die für die gerade anstehenden Berechnungen nicht von Nöten sind) zu speichern, während der „Shader Instruction Cache“ Shaderprogramme zwischenspeichern kann, womit selbst extrem lange Shaderanweisungen zu einem späteren Zeitpunkt durchgeführt werden können. Somit ist es dem R600 möglich, eine auftretende Latenz auf ein Minimum zu reduzieren, da kein Thread auf einen anderen warten muss, weil dieser mit dem bereitgestellte Shadercode erst später abgearbeitet wird. Die Anzahl der maximal möglich zu speichernden Threads beläuft sich auf mehrere hundert.
Stream-Processing-Units (SPU):
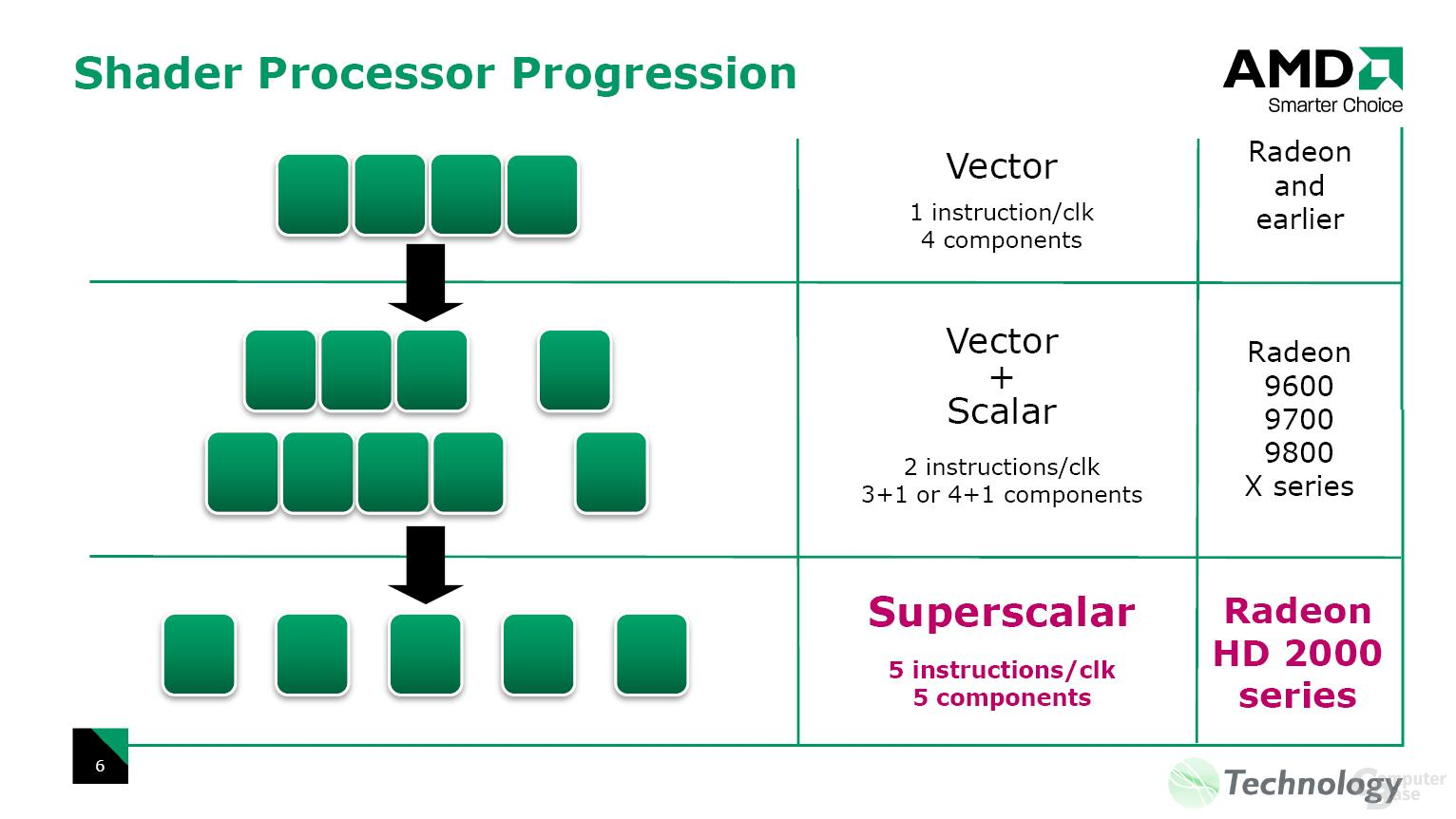
Werfen wir nun einen Blick auf die Stream-Processing-Units (SPU), beziehungsweise die eigentlichen Shadereinheiten im R600, wobei hier die Sichtweisen der Architektur (wohl aus Marketinggründen) etwas auseinander gehen und ATi in der Beschreibung unklar bleibt. Wie weiter oben im Text erwähnt, unterscheiden sich diese in der Arbeitsweise von den Vektorprozessoren im R580, aber ebenso von den Skalareinheiten im G80-Chip von nVidia. Die R600-GPU ist ein VLIW-Design (Very Large Instruction Word), es sollen also mehrere sequentielle Befehle in einem Thread parallel ausgeführt werden. Laut ATi verfügt der R600 über 320 SPUs. Es ist bei GPUs bekannterweise aber immer eine Frage der Zählweise, wie viele Einheiten man nun auf dem Papier stehen hat. Laut ATi sind die ALUs ein „5-way superscalar shader processor“, wobei Superskalar vieles ist. Superskalar bedeutet einzig, dass mehrere Befehle dynamisch parallel arbeitenden Einheiten zugeteilt werden. Nach unserem Kenntnisstand sind die ALUs auf einem R600 allerdings keine Skalareinheiten wie auf einem G80, sondern normale Vektorprozessoren – wobei diese gegenüber dem R580 deutlich verbessert worden sind.
Zweifellos können auf dem R600 bei maximaler Auslastung 320 MADD-Operationen (Multiply-ADD) pro Takt berechnet werden, während auf dem G80 maximal 128 MADDs möglich sind; das zusätzliche ADD aus den früheren ATi-GPUs ist also abhanden gekommen. Unserer Meinung nach sollte man aber nicht von 320 Shadereinheiten bei einem R600 sprechen, sondern von 64 5D-Einheiten, die in vier SIMD-Arrays mit jeweils 16 ALUs organisiert sind. Die 5D-ALUs können pro Takt einen RGBA-Wert (Rot, Grün, Blau sowie den Alphawert) und eine 1D-Skalaranweisung berechnen. Eine der fünf Einheiten in einer ALU agiert zusätzlich als Special Function Unit (SFU) und berechnet mathematische Operationen wie Sinus-, Kosinus- und Logarithmus-Anweisungen. Zusätzlich ist in einer ALU eine „Branch Execution Unit“ verbaut. Dynamic Branching (Sprunganweisung im Shadercode durch zum Beispiel einen if-/when-Befehl) blockiert auf dem R600 also nicht eine MADD-Einheit, sondern wird in einer gesonderten Funktionseinheit berechnet.
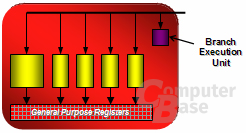
Bisherige Vektorprozessoren wie die 4D-ALUs auf dem R580 haben den Vorteil, dass ein 4D-Shadercode innerhalb eines Taktes beendet werden kann. Falls aber ein 2D-Shader vorliegt, bleiben die zwei weiteren Dimensionen unbelegt und können nicht benutzt werden – die ALUs steht also zeitweise still und wichtige Rechenzeit geht verloren. Aus diesem Grund können sich Vektorprozessoren splitten, aber dies auch nur begrenzt. Der R580 kann die ALUs im Verhältnis 3+1 sowie 4+1 splitten, sprich es wäre im ersten Fall möglich, die Shadereinheiten mit einem Shader aus drei Komponenten sowie einem Skalar auszulasten. Wie uns Eric Demers, der Senior Architect von ATi, gegenüber in einem Gespräch erwähnte, kann der R600 die ALUs selbst im Verhältnis „1D+1D+1D+1D+1D“ sowie alle anderen möglichen Verhältnisse aufsplitten. Somit würden die Vektoreinheiten beinahe wie Skalareinheiten agieren und es können pro Takt fünf Instruktionen fertiggestellt werden.
Weiterhin erwähnte Demers, dass die ALUs des R600 in Phasen von vier Zyklen arbeiten und während der vier Zyklen an vier verschiedenen Datenelementen (wie Pixels, Vertices etc.) arbeiten. Es werden fünf unabhängige Anweisungen ausgeführt. Dabei arbeitet jede Shadereinheit an vier verschiedenen Datenelementen, außer die fünfte Einheit (jene, die die SFU-Funktionen beinhaltet), die wiederum an denselben vier Elementen wie die vier anderen Shadereinheiten werkelt und während der vier Zyklen andere Befehle an jedem Element ausführt. Es wird also nicht, wie man zuerst vermuten könnte und wie fünf richtige Skalarprozessoren vorgehen würden, an fünf Datenelementen gleichzeitig gearbeitet, sondern nur an derer vier, wobei eine Shadereinheit aber zusätzlich alle vier Elemente einmal in den vier Zyklen abdeckt.
Wenn die ALUs ihre Arbeit an einem Datenelement beendet haben, können die Ergebnisse in einem Register zwischengespeichert werden, um auf diese in einem späteren Zeitpunkt zurückgreifen zu können. ATi wirbt auf dem R600 mit einer massiv besseren Geometry-Shaderleistung als auf einer GeForce 8800 von nVidia. Ob dies den Tatsachen entspricht, werden erste Direct3D-10-Benchmarks aber erst noch zeigen müssen. Da die ALUs über keine eigene Taktdomäne verfügen (der gesamte R600-Chip aber über 38 Taktdomänen, die immer nur kleine „unwichtige“ Chipteile betreffen), arbeiten die Shadereinheiten wie der Großteil des restlichen Chips mit 742 MHz. Die kleinere GPU RV630 kann auf 24 ALUs, der RV610 auf acht ALUs zurückgreifen.
Textureinheiten:
nVidia geht bei den Textureinheiten einen sehr interessanten Weg. So verbaut man auf dem G80 doppelt so viele Texture Mapping Units (TMUs), die die Texturen filtern können, als Texture Addressing Units (TAU), die für Aufgaben wie „Texture Lookups“ und allgemein für die Texturadressierung zuständig sind. Dies hat den praktischen Vorteil, dass entweder ein trilinear oder ein 2-fach bilinear anisotrop gefilterter Texel innerhalb eines Taktes fertiggestellt werden kann. ATi geht bei dem R600 genau den gegenteiligen Weg. So existieren auf dem R600 16 (aufgebohrte) TMUs, aber 32 TAU. Diese sind in vier Blöcken organisiert mit je vier TMUs sowie acht TAU. Die acht TAU besitzen jedoch unterschiedliche Fähigkeiten. Vier davon sind für Vertex- und Texture-Fetching zuständig während die vier anderen TAU die Texturadressierung erledigen.
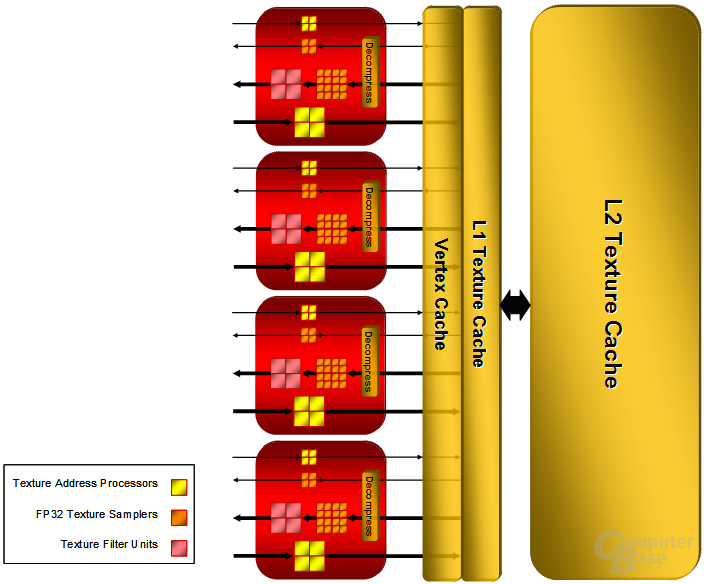
Wie Eric Demers uns in einem Gespräch ehrlich verriet, kann es gut sein, dass das gegensätzliche Verhältnis zu nVidia in Direct3D-9-Spielen ein Nachteil ist. In Direct3D-10-Anwendungen rechnet ATi aber mit einem Vorteil. Die TMUs können innerhalb eines Taktes einen 64-Bit-Wert filtern, weswegen die Textureinheiten FP16-HDR-Rendering ohne Geschwindigkeitsverlust gegenüber der herkömmlichen Genauigkeit berechnen können. FP32-HDRR benötigt dagegen zwei Takte, um einen Wert zu vervollständigen. Massiv gesteigert haben die Kanadier die Anzahl der Texture Samples, die pro Takt einen einzelnen Datenwert abrufen können. Pro Texturcluster gibt es 20 Texture Samples, insgesamt auf einem R600 also 80 dieser Einheiten.
Die Textureinheiten des R600 verfügen über einen überraschend großen Zwischenspeicher. So gibt es einen Shared L1- und L2-Texture-Cache, wobei letzterer auf der Radeon HD 2900 XT 256 KB groß ist, während der Speicher auf der Radeon HD 2600 halbiert ist. Zudem gibt es noch einen Vertex-Cache, dessen Größe wie die des L1-Caches aber unbekannt ist. Beim RV610 verzichtet ATi auf die drei verschiedenen Caches, so dass es nur einen gemeinsamen Vertex-/Texture-Cache gibt. Die TMUs arbeiten auf dem R600 wie die ALUs mit einer Frequenz von 742 MHz. Darüber hinaus hat man die anisotrope Filterung gegenüber dem R580 leicht verändert. Eine winkelabhängige Texturfilterung gibt es nicht mehr, der Treiber ermöglicht, wie der G80, nur noch eine qualitativ höherwertige winkelunabhängige anisotrope Filterung. Ebenfalls hat man einige Bugs entfernt, die in einigen Spielen ein starkes Texturflimmern hervorgerufen haben. Zudem wurde die Präzision des 16-fachen anisotropen Filters verbessert.