Volker_Dirr
Cadet 1st Year
- Registriert
- Okt. 2023
- Beiträge
- 14
<Vorwort>
Liebe Moderatoren, falls diese Mail als Werbung aufgefasst werden sollte, dann bitte entwerder den Link oder die ganze Nachricht löschen. (Für Werbung ist dieses Forum aber unpassend und die falsche Zielgruppe. Lehrerforen wären dafür "hilfreich", dort finde ich aber nicht das, was ich wissen möchte.)
</Vorwort>
Hallo,
ich bin co-Autor einer Open Source Stundenplanungssoftware.
Diese Software wird i.d.R. auf PC der unteren Mittelklasse durchgeführt (typische Bürorechner), weil im Büro i.d.R. nicht so leistungsfähige Rechner benötigt werden. Aber ~2 mal pro Jahr wird für ~1 Woche benötigen Schulen extrem viel Leistung für die Stundenplanung.
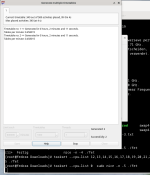
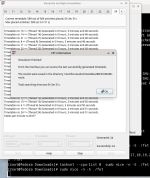
Ich habe unsere Software so abgeändert, dass ein Benchmark leicht durchgeführt werden kann. (Es ist also kein "syntetischer" Benchmark, sondern eine professionelle Anwendung). Ich habe schon Benchmarkergebnisse von typischen (untere) Mittelklasse-CPUs. Mich interessieren jetzt noch insbesondere Ergebisse der teuren aktuellen Desktopklasse und Server CPU Klasse, die in Bürorechnern üblicherweise nicht sind. Also aktuelle CPUs der Preisklasse 400+x €. Archikektur ist egal. Muss nicht x86 und Windows sein, kann im Grunde auch jede andere Architektur sein. (ARM, .. Linux, MacOS, ...).
Ich schätze den gesamten Zeitaufwand (Download, Benchmark durchführung, Ergebisse mitteilen, ...) auf etwa 15 Minuten.
Ich würde mich freuen, wenn ich zumindest 4 Teilnehmer finden würden (Je einer für aktuelle High End Desktop und Server CPU von Intel und AMD). Bitte nach Möglichkeit keine OC CPU, nur Standartwerte. Grafikkarte ist für den Test unerheblich. RAM kann ruhig OC sein.
Wer hat Interesse mir zu helfen?
Den Benchmark (und bisherige Ergebnisse) gibt es hier (Englisch - aber ich helfe gerne weiter, wenn das ein Problem sein sollte):
https://lalescu.ro/liviu/fet/forum/index.php?topic=5729.0
(Falls die Moderatoren den Link entfernt haben sollten, dann schreibt mir doch eine PN)
Schönes Wochenende
Volker
Liebe Moderatoren, falls diese Mail als Werbung aufgefasst werden sollte, dann bitte entwerder den Link oder die ganze Nachricht löschen. (Für Werbung ist dieses Forum aber unpassend und die falsche Zielgruppe. Lehrerforen wären dafür "hilfreich", dort finde ich aber nicht das, was ich wissen möchte.)
</Vorwort>
Hallo,
ich bin co-Autor einer Open Source Stundenplanungssoftware.
Diese Software wird i.d.R. auf PC der unteren Mittelklasse durchgeführt (typische Bürorechner), weil im Büro i.d.R. nicht so leistungsfähige Rechner benötigt werden. Aber ~2 mal pro Jahr wird für ~1 Woche benötigen Schulen extrem viel Leistung für die Stundenplanung.
Ich habe unsere Software so abgeändert, dass ein Benchmark leicht durchgeführt werden kann. (Es ist also kein "syntetischer" Benchmark, sondern eine professionelle Anwendung). Ich habe schon Benchmarkergebnisse von typischen (untere) Mittelklasse-CPUs. Mich interessieren jetzt noch insbesondere Ergebisse der teuren aktuellen Desktopklasse und Server CPU Klasse, die in Bürorechnern üblicherweise nicht sind. Also aktuelle CPUs der Preisklasse 400+x €. Archikektur ist egal. Muss nicht x86 und Windows sein, kann im Grunde auch jede andere Architektur sein. (ARM, .. Linux, MacOS, ...).
Ich schätze den gesamten Zeitaufwand (Download, Benchmark durchführung, Ergebisse mitteilen, ...) auf etwa 15 Minuten.
Ich würde mich freuen, wenn ich zumindest 4 Teilnehmer finden würden (Je einer für aktuelle High End Desktop und Server CPU von Intel und AMD). Bitte nach Möglichkeit keine OC CPU, nur Standartwerte. Grafikkarte ist für den Test unerheblich. RAM kann ruhig OC sein.
Wer hat Interesse mir zu helfen?
Den Benchmark (und bisherige Ergebnisse) gibt es hier (Englisch - aber ich helfe gerne weiter, wenn das ein Problem sein sollte):
https://lalescu.ro/liviu/fet/forum/index.php?topic=5729.0
(Falls die Moderatoren den Link entfernt haben sollten, dann schreibt mir doch eine PN)
Schönes Wochenende
Volker
Zuletzt bearbeitet: