nVidia GeForce 7800 GTX (SLI) im Test: Mit zwei Grafikkarten gegen ATi
3/17Der G70 im Detail
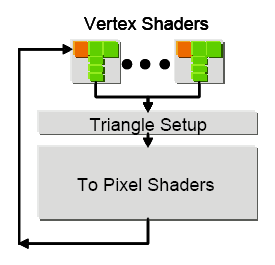
Vertexshader:
Allfällig ist natürlich für eine neue Generation auch wieder die Steigerung der Vertexleistung geworden, die kaum ein Spiel auch nur ansatzweise auszureizen im Stande ist. Vielmehr dienen die Verbesserungen in dieser Region der GPU dem professionellen Markt der OpenGL-CAD/CAM/CAE-Beschleuniger, sowie natürlich dem 3DMark, welcher sich dank horrend-unrealistischer Polygonzahlen über jedes Bißchen Vertexeinheit freut.
Zu allererst ist natürlich für die Leistungssteigerung die von sechs auf acht gestiegene Anzahl der Vertexshader und der leicht erhöhte Takt der GPU zu nennen, wie unsere tabellarische Übersicht auf der vorhergehenden Seite zeigt.
Neben der Takt- und Parallelitätssteigerung, die allein schon für rund 43 Prozent der theoretisch vorhandenen Mehrleistung verantwortlich sein dürften, hat man bei nVidia auch die Leistung des dem Vertexshader nachgeschalteten Triangle-Setups und speziell des festverdrahteten Culling-Teils nach eigenen Angaben um 30 Prozent verbessert*. Dies ist wohl nötig gewesen, da nVidias Early-Z-Lösung nicht direkt an die Anzahl der Pixelpipelines gebunden ist, so dass, wenn man, wie hier geschehen, mehr Shaderpipelines hinzunimmt, nicht gleichzeitig die Anzahl verwerfbarer Pixel steigt. Zugespitzt würde dies irgendwann den Vorteil des Early-Z negieren, mehr Pixel auf einmal verwerfen zu können, als anderweitig zu bearbeiten. Ferner ist nun - auch hier müssen wir noch auf weitere Erklärungen seitens nVidia warten - in jedem der Vertexshader die Berechnung einer üblichen Vector4-Operation parallel mit einer Skalaroperation möglich. Im nV40 waren die Skalaroperationen noch auf wenige Spezialbefehle eingeschränkt, so dass nicht generell von einer 4+1-FP-ALU im Vertexshader gesprochen wurde.
Pixelshader:
„Ein schäbiges ADD!“, so könnte man böswillig und verkürzt die „bis zu doppelte Performance“ der Pixelshader-Pipelines pro Takt und Stück auch beschreiben. De facto wurde die Shader-Einheit 1, die die TMU ansteuert, schlicht und einfach um die Möglichkeit bereichert, einen zusätzlichen ADD-Befehl zum bereits vorhandenen MUL-Kommando auszuführen, so dass sich jetzt die Möglichkeit ergibt, dass beide Shader-Units eine MAD-Operation pro Takt ausführen können. Vorher war dies nur der Shader-Einheit 2 möglich, so dass sich der MAD-Durchsatz pro Takt und damit auch die Shader-Gesamtleistung verdoppelt - willkommen in der wunderbaren Welt des Marketing.
Ganz so drastisch ist die Realität natürlich nicht – die Verbindung eines MUL mit einem ADD (beide Befehle machen so ziemlich genau das, wonach sie klingen: Multiplizieren und Addieren) bzw. das daraus resultierende MAD(D) wird neben dem Normalmapping auch im Dot-Product für Specular-Mapping genutzt und somit in zwei der bereits häufig und großflächig eingesetzten Shadertechniken.
Mehr als durch dieses „zusätzliche ADD“, von nVidia nach eigenen Angaben aufgrund extensiver Recherchen, was verwendete Shaderoperationen in modernen Spielen für Beleuchtung und Normalmapping angeht, hinzugefügt, dürften sich die Shadereinheiten aber durch ihre schiere Anzahl und viele kleinere Verbesserungen im Detail verschnellert haben. Ein wenig pikant ist allerdings die Frage, warum man dieses „ADD“, wenn es doch so wichtig und richtig ist, erst aus der zweiten Shadereinheit des nV40 entfernte.
Ansonsten wurde die Geschwindigkeit der Pixelshader vornehmlich durch die höhere Parallelität, jetzt 24 4xSIMD-Kanäle, vormals nur 16, und durch im Anschluß beschrieben Änderungen an der Textureinheit erreicht – diese stellte bis zum nV45 unter Umständen noch einen Flaschenhals dar, der die Auslastung der Pipeline herunter drückte.

Texture-Engine:
Die TMU ist beinahe traditionell ein Problemkind in der CineFX-Engine. Nicht, dass sie nicht schnell und flexibel zu Werke gehen könnte. Nein, ihr Einsatz blockiert für die Dauer ihrer Latenz, die mit zunehmend anspruchsvollerem Texturfilter natürlich steigt, die zweite Shadereinheit und, sobald der interne Buffer voll ist, auch die erste. Somit wird bei hohen Graden an anisotroper Texturfilterung eine Pixelpipeline einen mehr oder minder großen Teil der Zeit einfach gar nichts tun, sondern einfach nur abwarten, bis die TMU ihr Ergebnis zurückliefert. Das wirklich problematische an dieser Geschichte ist, dass die Latenz der TMU um ein Vielfaches größer ist als die Zeit, die ein normal-aufwendiger 2.0-Shader zur Ausführung braucht – nicht einen oder zwei Takte mehr, sondern eher im Bereich dutzender, sinnloser Wartezyklen.
Diese überflüssige Warterei wollte man verständlicherweise reduzieren und so veränderte man die Texturcaches bzw. deren Anbindung so, dass nun auch größere Texturwerte als 32 Bit schneller bereitgestellt werden können. Dies könnte entweder durch eine Verbreiterung der Cacheanbindung oder einfach durch größere Caches geschehen sein. Für die GeForce 6-Serie gab nVidia auch den Hinweis an Developer, Floating-Point Texturen mit vier Kanälen (RGBA) lieber in zwei separate Zweikanal-Texturen (RG & BA) aufzuteilen, woraus man bis zu 30 Prozent zusätzliche Performance gewinnen könne.
Transparency-AA:
Ein großes Problem des Multisampling waren und sind so genannte Alpha-Test-Texturen. Diese werden genutzt, um durchsichtige Löcher in Texturen darzustellen, ohne dass man das entsprechende Objekt aufwendig mit Geometrie modellieren muss. Aktuell sind die Maschendrahtzäune in Half-Life² so ein Beispiel. Dadurch, dass die Löcher quasi Bestandteil einer Textur sind und eben nicht mit Geometrie erreicht werden, wirkt hier Multisampling einfach nicht und sobald die extrem dünnen Maschendräht virtuell kleiner sind als ein Pixel, beginnen sie auf- und wieder wegzupoppen.
Transparency-AA kann einerseits schon länger Supersampling für Alpha-Test-Texturen aktivieren, ein altes Verfahren, welches vor dem heute üblichen Multisampling bereits von GeForce 2 und VSA-100 genutzt wurde, aber damals auf das komplette Bild angewandt wurde und entsprechend Leistung verschlang. Andererseits, und das ist neu, kann der G70 dieses ressourcenverschlingende Supersampling für entsprechende Texturen aktivieren oder auf mit Pixelshadern berechnete Oberflächen, die wirklich durchsichtige Flächen enthalten, selektiv begrenzen, und so einiges an Leistung sparen – etwas langsamer als aktuelles Multisampling ist es jedoch.
Zusätzlich gibt es noch eine schnellere Multisampling-Variante des Transparency-AA, welche ein sehr ähnliches Verfahren nutzt, aber noch etwas schneller zu Werke geht. Genauere Details wollte nVidia hierüber nicht verraten, es scheint aber, als würde hierbei eine Art Verteilung der Samples auf die durchsichtig und die dahinter liegende Fläche vorgenommen. Intelligenterweise scheint es sich bei dem Raster, welches für Transparency-AA verwendet wird, nicht um das ineffektive Ordered-Grid zu handeln. Über den Treiber hat man die freie Auswahl zwischen beiden Modi.



PureVideo
Wie unser Test zeigt, verfügt auch der G70 über einen funktionsfähigen Videoprozessor. Dieser ist im Gegensatz zu früheren Varianten nun in drei eigene Einheiten für verschiedene Kompressionsverfahren und -bearbeitungsstufen, sowie für verschiedene Post-Processing-Effekte und De-Interlacing-Verfahren aufgeteilt. Neben dem bisher bereits möglichen 3:2-Pulldown wird nun auch das für PAL-verwöhnte Europäer unter Umständen nicht unwichtige 2:2-Pulldown-Verfahren angeboten (dies allerdings erst in einem spätern Treiber. Woher kommt uns das nur bekannt vor?). Ebenfalls soll der G70 fortschrittliche Kompressionsformate wie H.264 unterstützen (auch dies wiederum nur unter Verwendung spezieller Software wie bsw. den kostenpflichtigen nV-DVD-Dekoder) und dank seiner Programmierbarkeit auch für zukünftige Entwicklungen gerüstet sein.
HDR / MSAA:
Noch eine kleine Anmerkung am Rande. Bisher war es in Spielen wie Far Cry oder Splinter Cell Chaos Theory nicht möglich, „High Dynamic Range Rendering“ (HDR, vier Kanäle mit FP16-Genauigkeit) zusammen mit Multi-Sampling zu verwenden. Wie wir uns bei nVidia auf dem Launch-Event in Paris persönlich überzeugen konnten, werden in beiden Launch-Demos definitiv geglättete Kanten zu sehen sein – und laut Aussage von nVidia verwenden beide Demos, „Mad Mod Mike“ und „Luna“ (übrigens ein Anagramm von „Nalu“ von vor einem Jahr), HDR-Rendering.
Auf Nachfrage konnte uns nVidia bestätigen, dass die angenommene Unverträglichkeit von MSAA und HDR nur für, so wörtlich, herkömmliche Verfahren gelte. Man habe aber einen Weg gefunden, diese Beschränkung zu umgehen und diverse Developer davon unterrichtet. So dürfen wir uns in Zukunft hoffentlich auf glatte Kanten in allen Lebenslagen freuen!


Update:
* die „eigenen Angaben“ nVidias beziehen sich auf das Triangle-Setup, nicht auf den Culling-Teil.