AMD Brazos im Test: Der perfekte Wohnzimmer-PC
2/22Technische Details
AMDs „Zacate“ beziehungsweise „Ontario“ ist das Herz der „Brazos“-Plattform. Dahinter verbirgt sich ein in 40 nm gefertigter Chip, der die Wesenszüge eines Prozessors und einer Grafikkarte miteinander vereint. AMD nennt diese Konstruktion letztlich APU – Accelerated Processing Unit.
Was auf dem ersten Blick jedoch nach einer vielleicht gleichen Verteilung von Prozessor und Grafik klingt, ist unter der Haube ganz anders. Der eigentliche Prozessorteil mit den beiden Kernen samt L1-Cache und dem dazugehörenden L2-Cache macht nur einen Bruchteil des 75 mm² großen Dies aus, der Bärenanteil geht allein auf den DirectX-11-fähigen Grafikteil und die notwendigen Anschlüsse zurück. Der integrierte Speichercontroller für Single-Channel-Anwendungen belegt ebenfalls einen größeren Teil, der in der Fläche etwa an die Hälfte der beiden CPU-Kerne samt L2-Cache heran reicht.
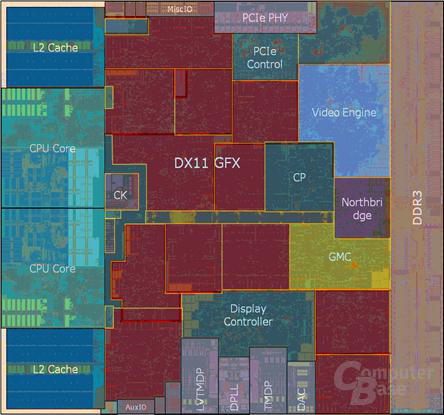
Anhand der Aufteilung wird direkt klar, in welchem Segment die Prioritäten der APUs liegen. Es soll keine brachiale Prozessorpower geboten werden, das Gesamtpaket aus CPU, GPU und der dazu benötigten Energie soll stimmig sein. Heraus ragt dabei das Dual-Core-Modell des „Ontario“, das quasi genau diesen gezeigten Die besitzt und in eine TDP-Klassifizierung von 9 Watt fällt. Da AMD jedoch auch etwas mehr Leistung sowohl für die CPU-Kerne als auch die Grafikeinheit aus dem Design herausgekitzelt hat, sind mit den „Zacate“ auch Versionen mit einer TDP von 18 Watt verfügbar.
| Modell | Codename | CPU -Kerne |
CPU-Takt | GPU | Stream- prozessoren |
GPU-Takt | TDP |
|---|---|---|---|---|---|---|---|
| E-350 | „Zacate“ | 2 | 1,6 GHz | Radeon HD 6310 | 80 | 500 MHz | 18 W |
| E-240 | „Zacate“ | 1 | 1,5 GHz | Radeon HD 6310 | 80 | 500 MHz | 18 W |
| C-50 | „Ontario“ | 2 | 1,0 GHz | Radeon HD 6250 | 80 | 280 MHz | 9 W |
| C-30 | „Ontario“ | 1 | 1,2 GHz | Radeon HD 6250 | 80 | 280 MHz | 9 W |
Prozessor
Basis für den eigentlichen Prozessor ist die „Bobcat“-Architektur. Diese geisterte bereits seit Mitte 2007 über AMDs Roadmap, hat jedoch viele Jahre gebraucht, um den Markt zu erreichen. Von den Ursprüngen ist dabei jedoch nicht mehr viel erhalten geblieben, lediglich die Idee wurde weiter getragen. Heute ist der Bobcat ein moderner Prozessorkern im Out-of-Order-Design, der strikt in Richtung geringe Energieaufnahme optimiert wurde. Dafür musste in einigen Bereichen natürlich der Rotstift angesetzt werden.
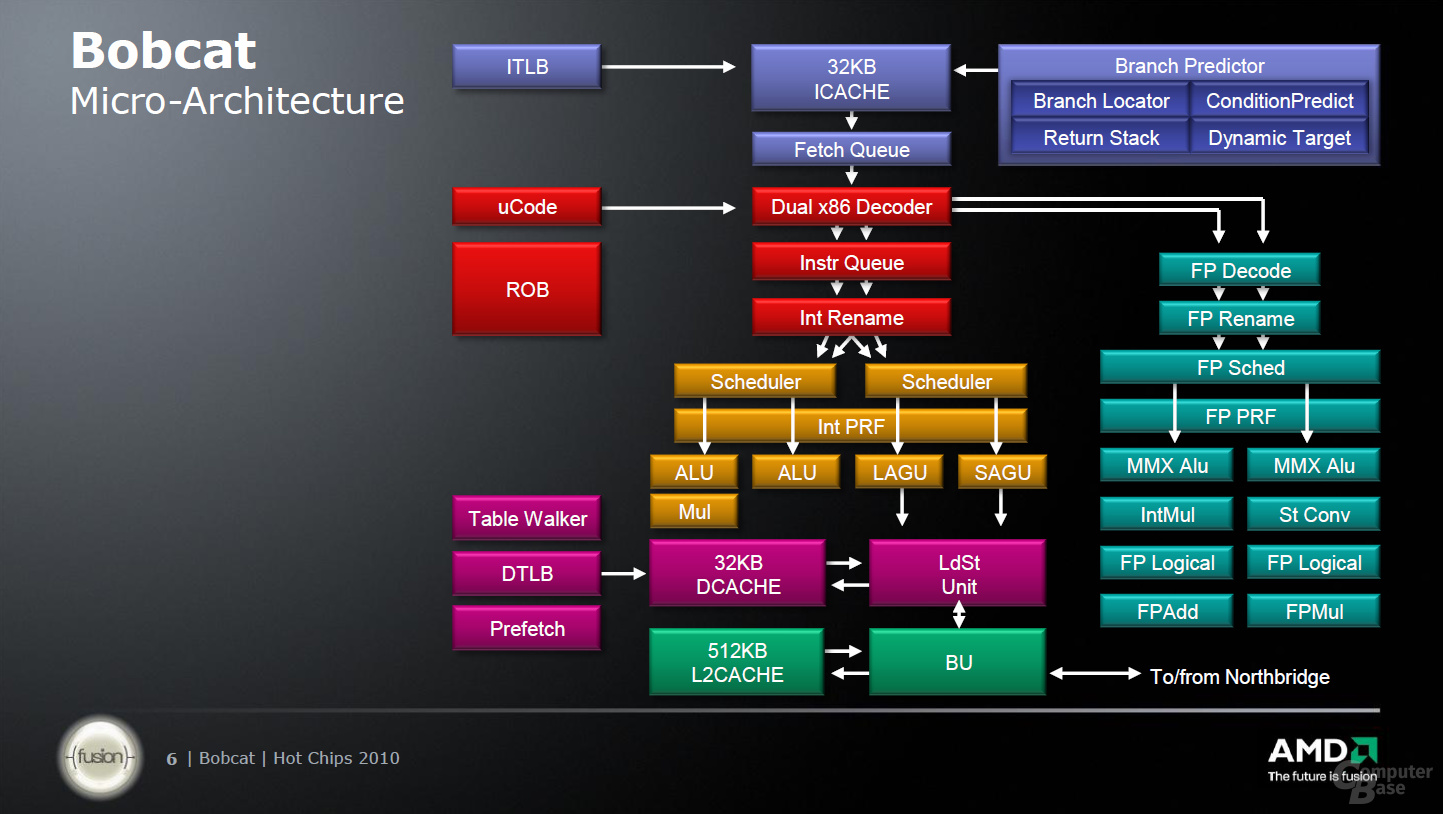
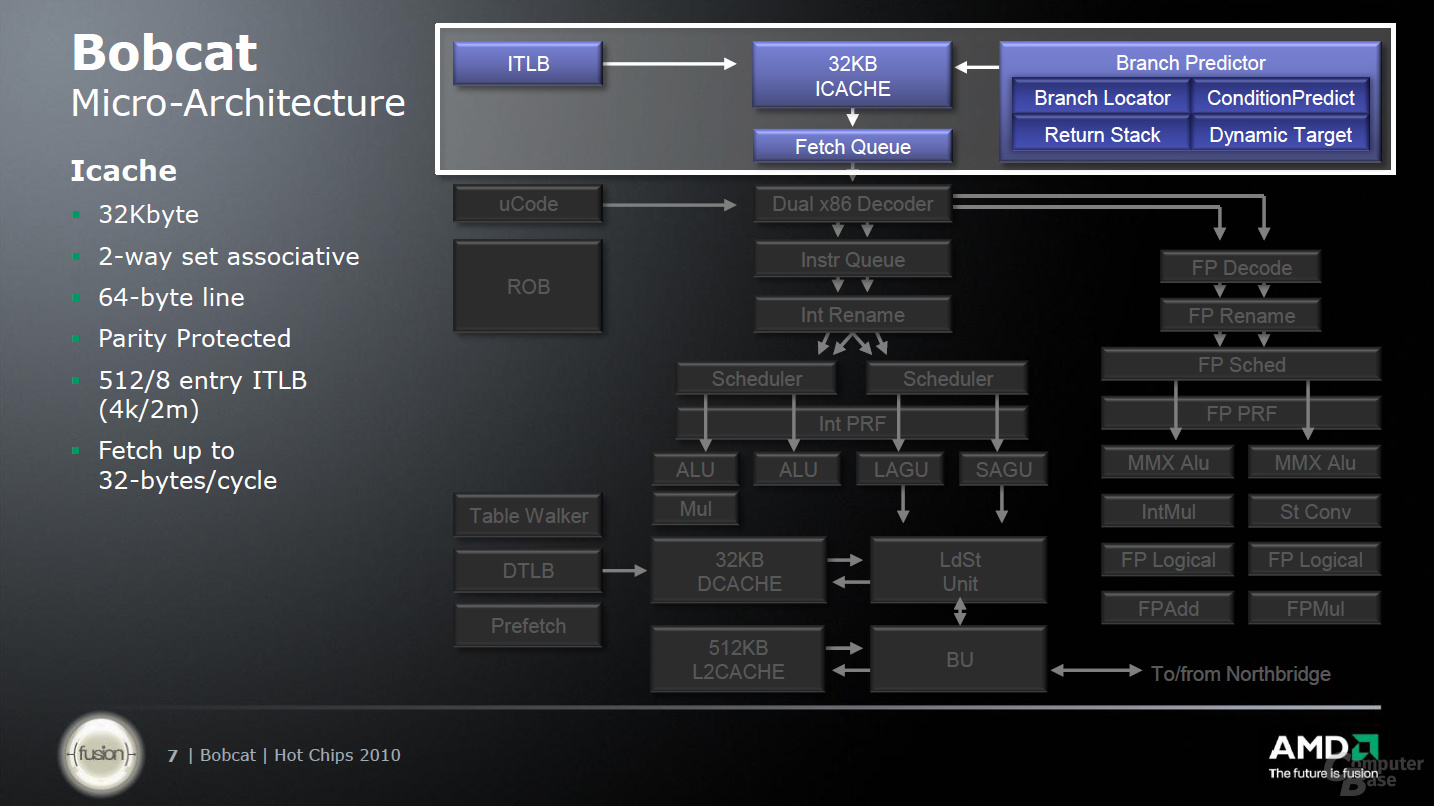
So richtig lässt sich AMD dabei allerdings nicht in die Karten sehen. Eines der wichtigsten Elemente ist wie bei jedem Prozessor eine überarbeite und optimierte Sprungvorhersage (Branch Prediction), die im Falle des „Bobcat“ zwei Sprünge pro Taktzyklus vorhersagen kann. Nach der Zwischenspeicherung im L1-Instruktionen-Cache kann sich die Befehlsholstufe pro Taktzyklus 32 Byte aus L1I-Cache holen und diese an die Decode-Unit weiterreichen, in der maximal zwei x86-Befehle pro Taktzyklus gleichzeitig verarbeitet werden. Hier kommt das erste Mal AMDs Trickkiste zum Einsatz, denn dank eines Micro-Code-Speichers können 89 Prozent der Befehle direkt übersetzt werden.
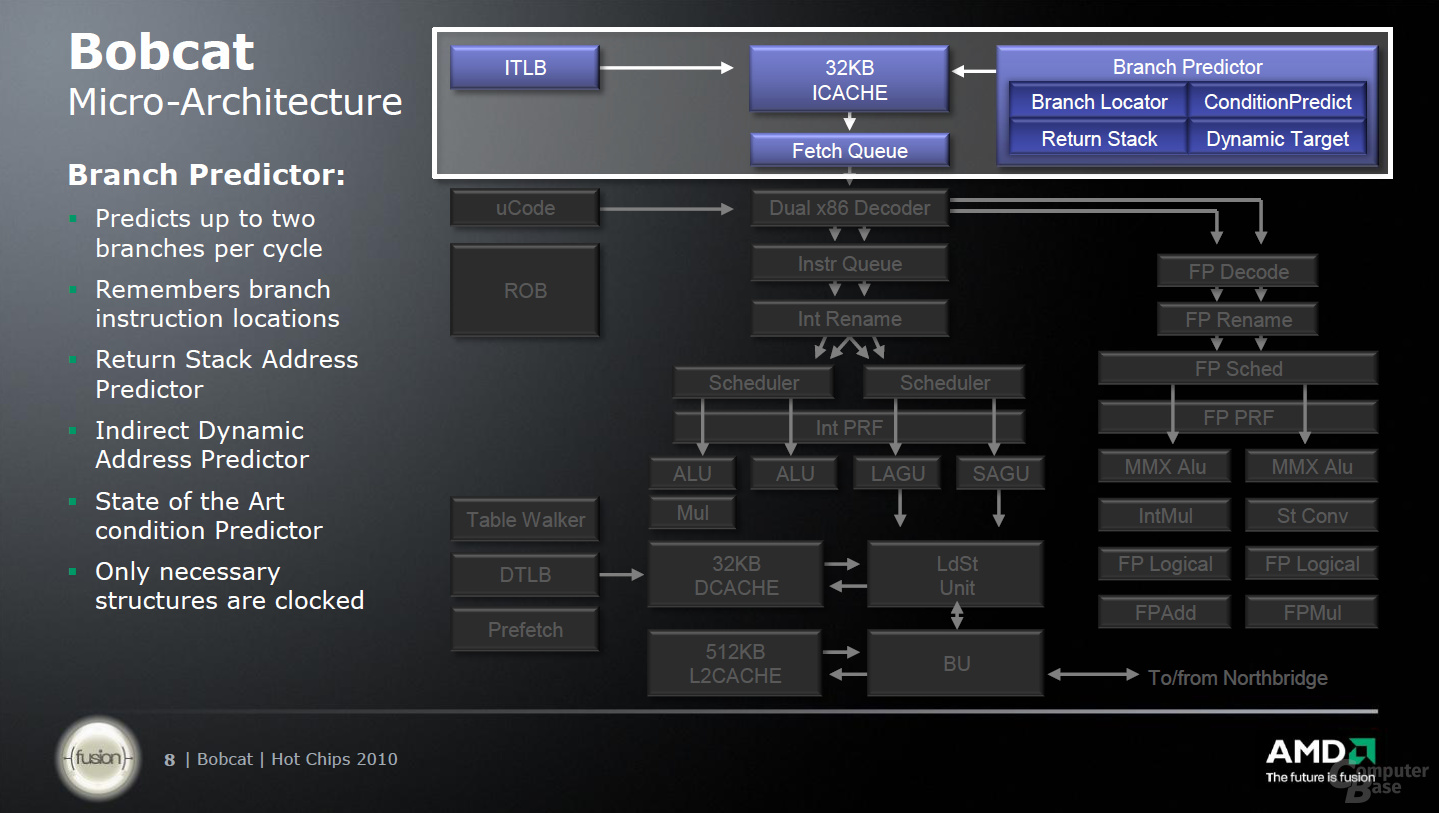
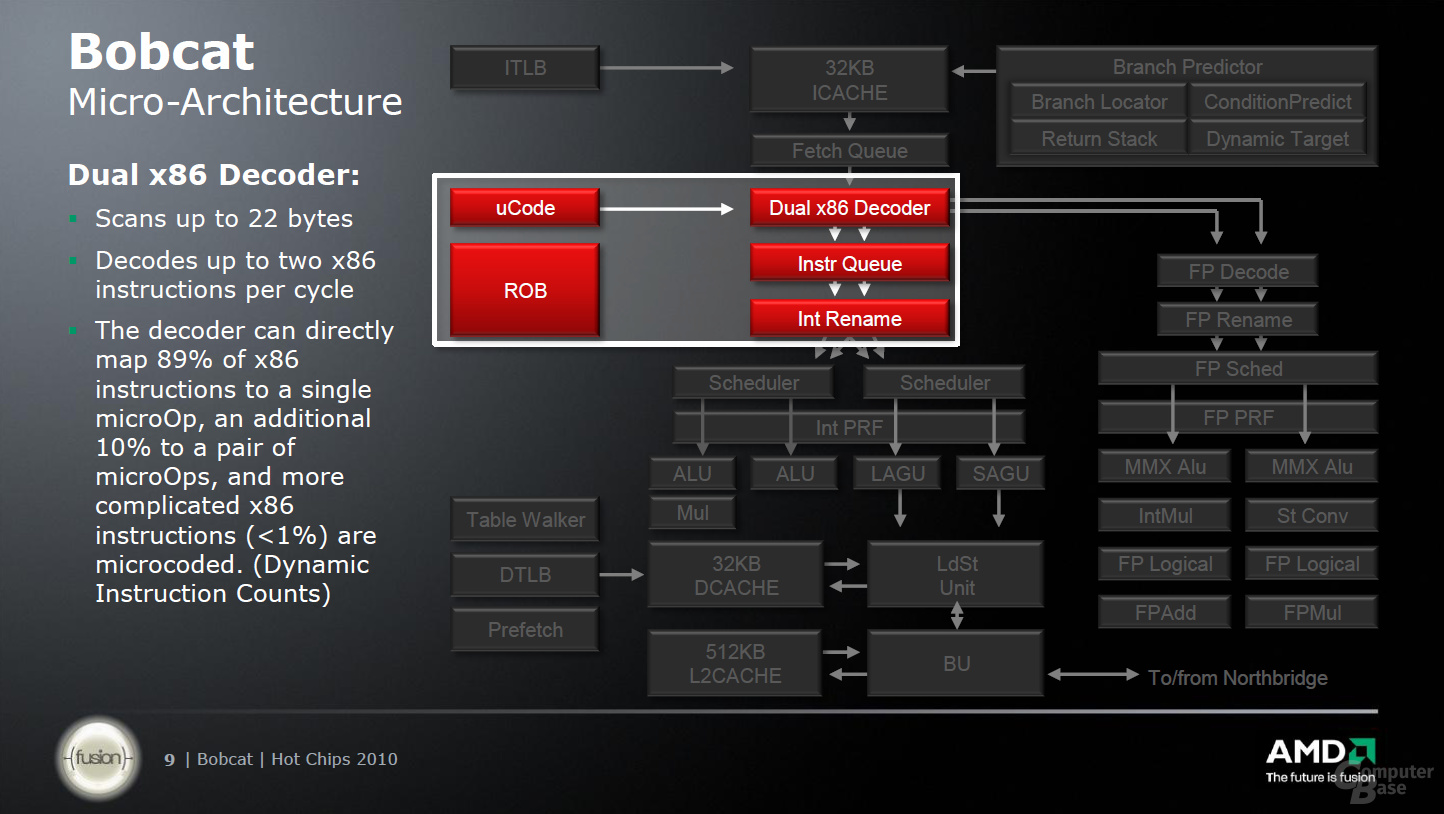
Früher hat jeder µOp (Micro-Befehl) eine Kopie seinesgleichen im Buffer (ROB) abgelegt. Dadurch wurden immer Speicherplatz und gleichzeitig auch Transferkapazität belegt, der mit der Einführung des Physical Register Files (PRF) beim „Bobcat“ anderweitig genutzt wird. Statt nun eine Kopie mitzuführen, wird der Micro-Befehl im PRF abgelegt und dort gezielt angesprochen, was wiederum Energie einsparen soll – eines der Ziele dieser Architektur.
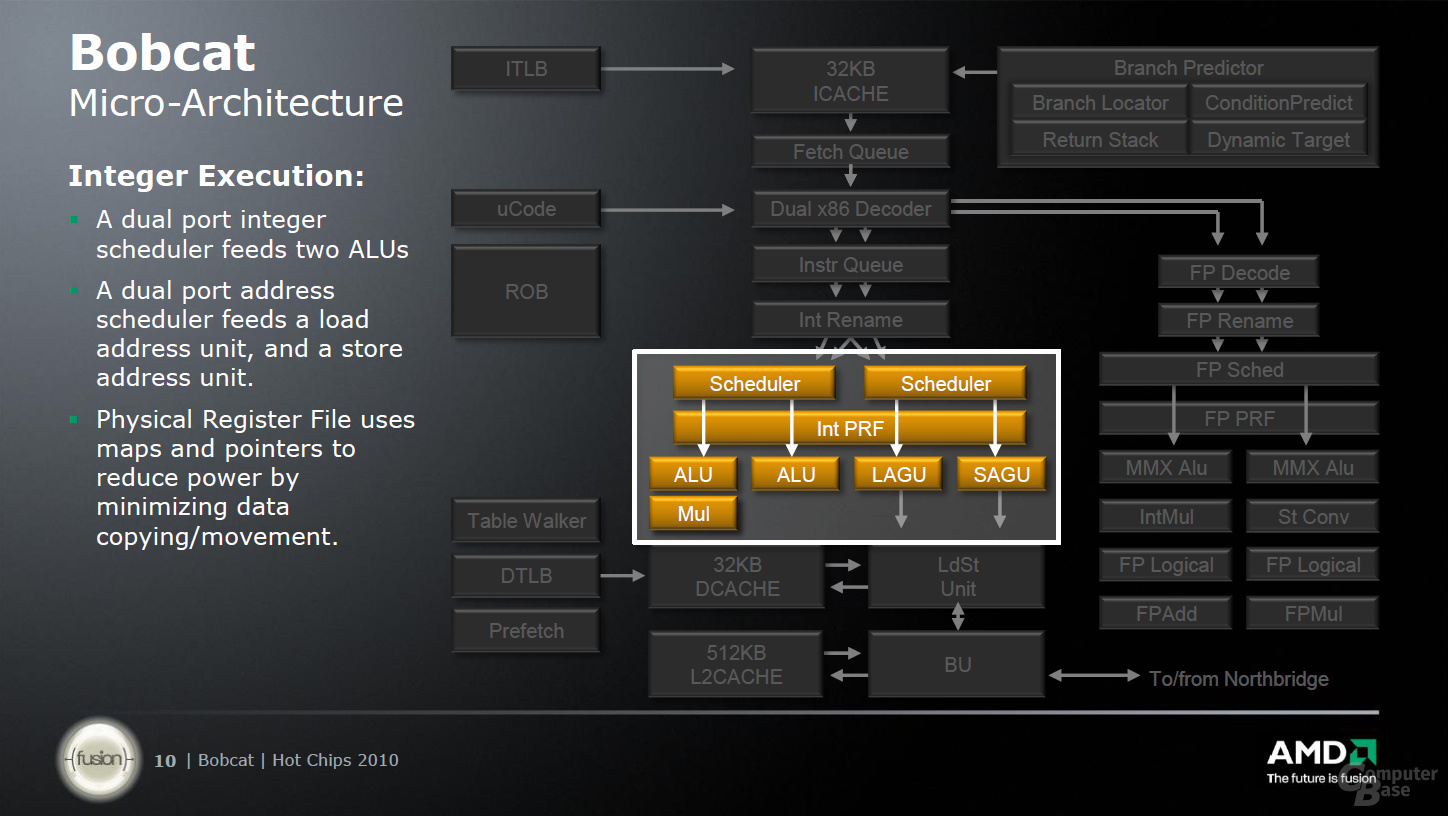
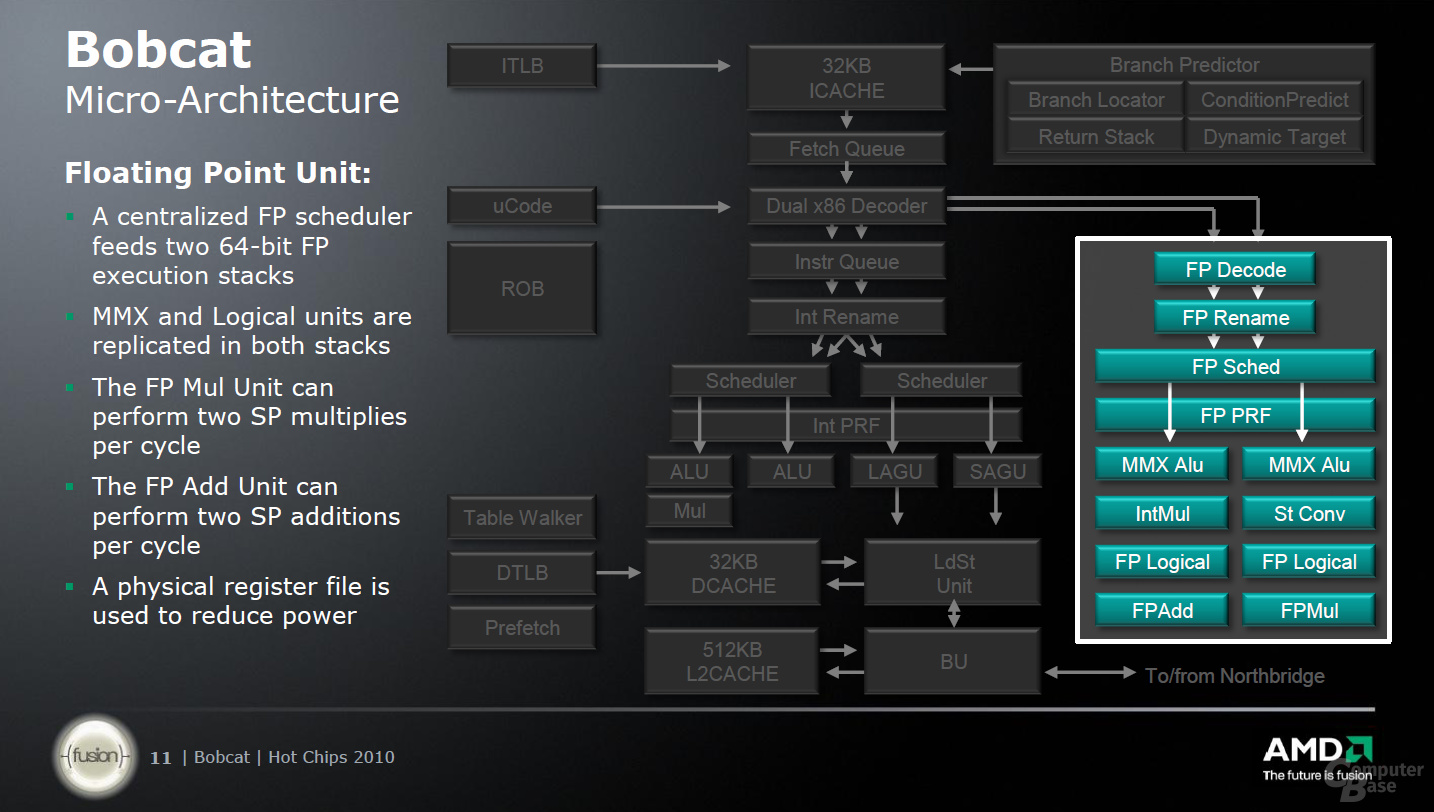
Die größten Einschränkungen folgen jedoch erst in den kommenden Bereichen: bei den Integer- und Gleitkommaberechnungen. So kann die Gleitkommaeinheit nur zwei Ausführungseinheiten ansprechen, von denen jeweils eine multipliziert und eine addiert. Die weitere Einschränkung besagt, dass diese Befehle auch nur maximal 64 Bit große Operanden enthalten dürfen, was ein weiteres Hindernis darstellt. Ähnlich geht es bei der Integer-Berechnung zu: Zwei Scheduler sprechen zwei ALUs und zwei AGUs an, wobei sich letzte wiederum in eine AGU für Speicher- und eine für Lade-Operationen aufteilen.
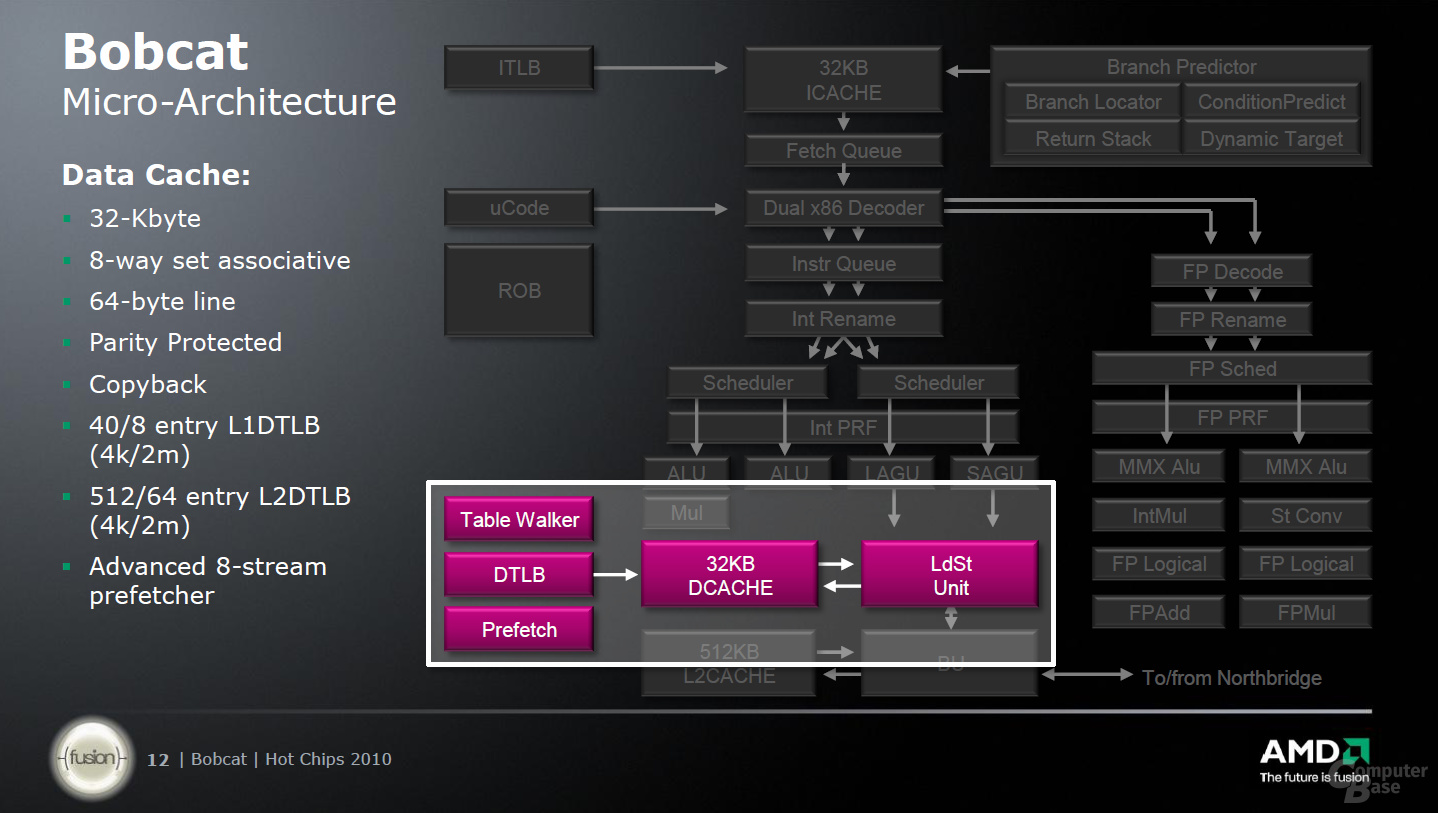
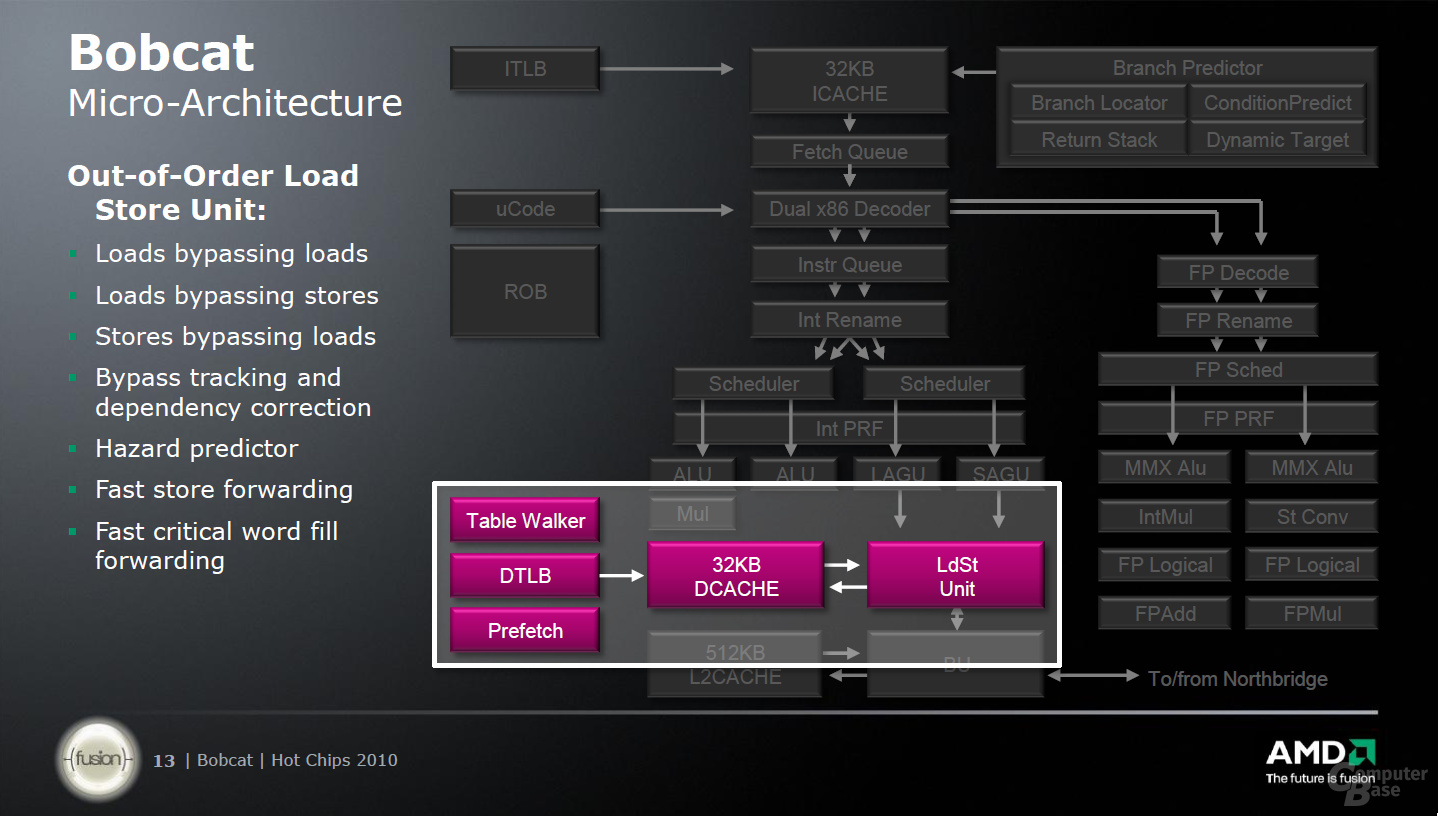
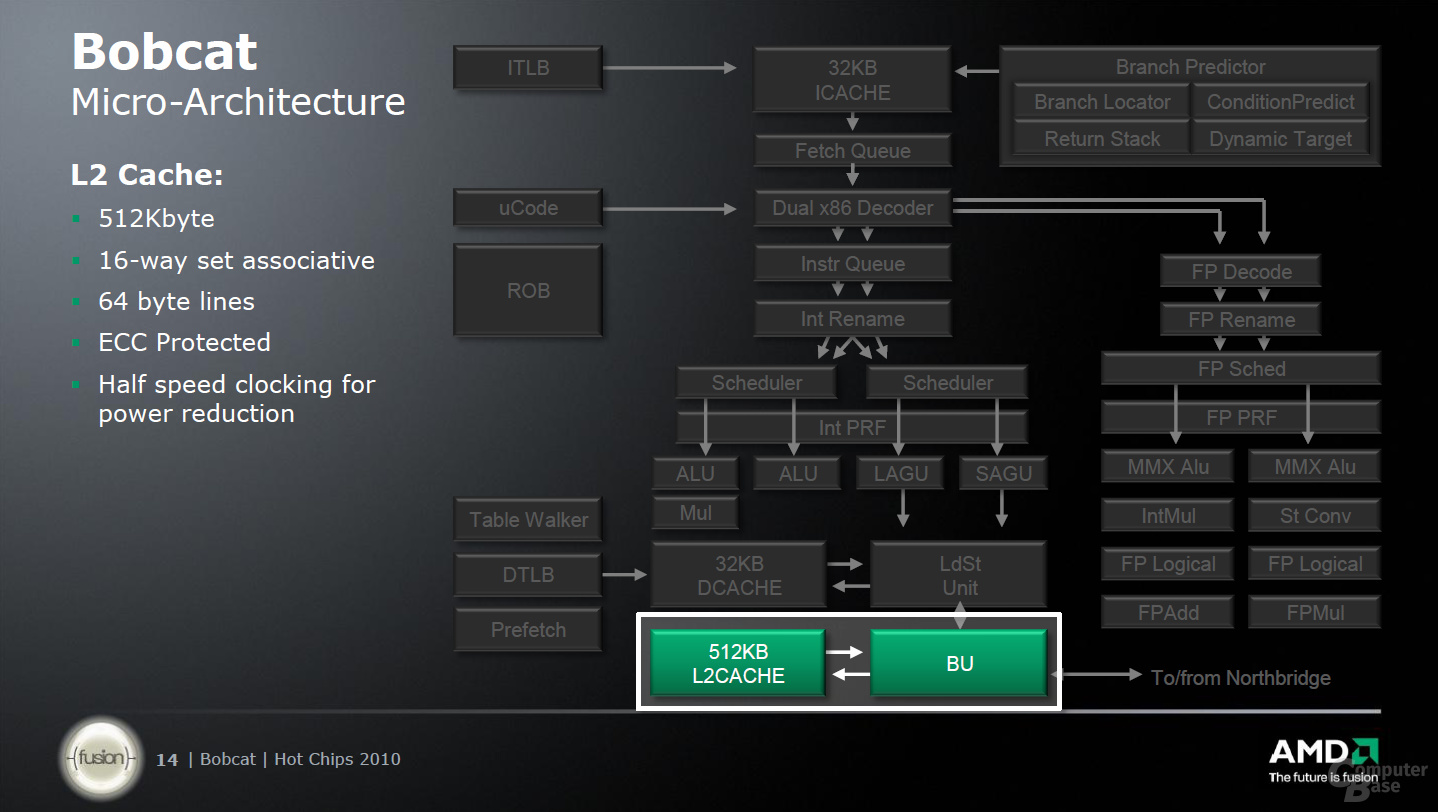
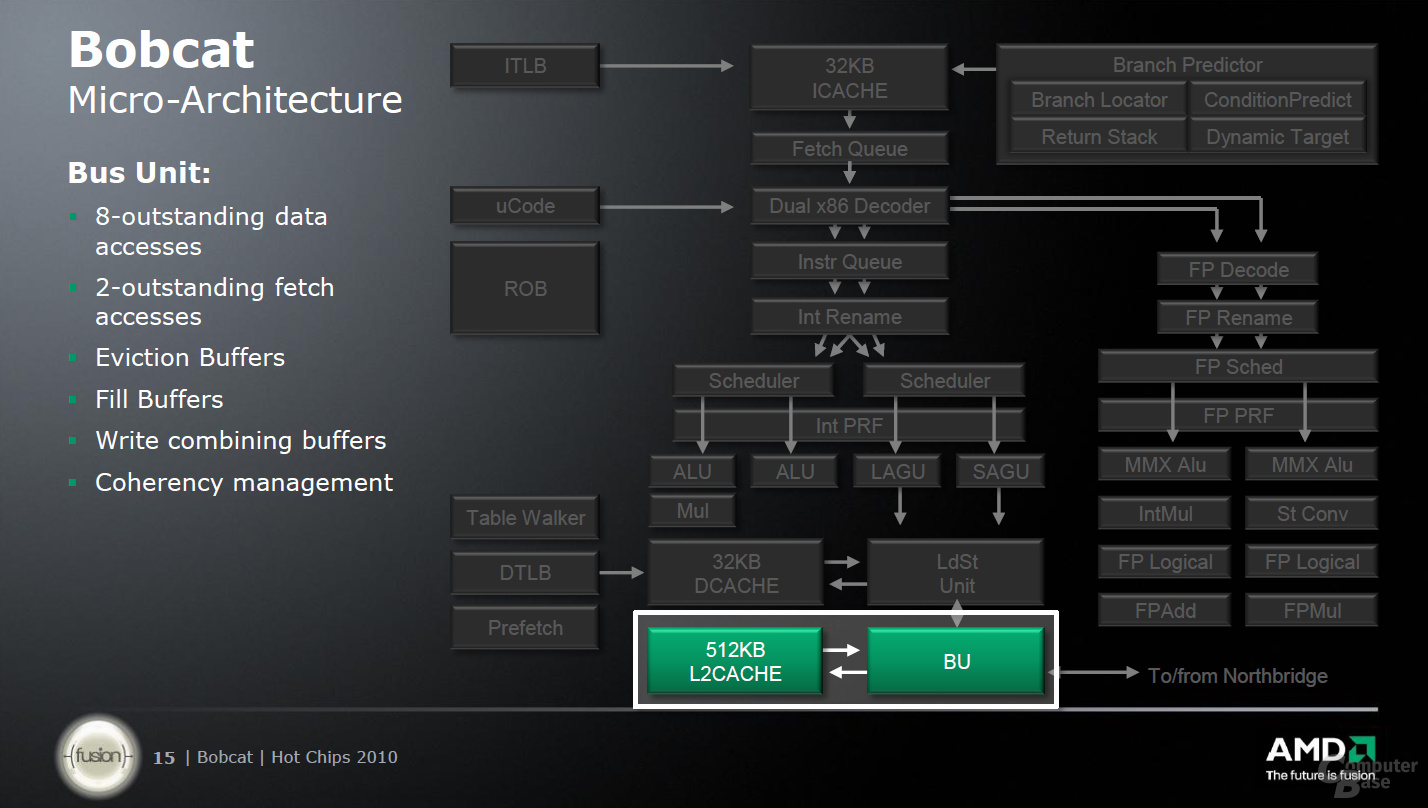
Zu guter Letzt gibt es noch einen 32 KByte großen L1-Daten-Cache sowie der L2-Cache von 512 KByte pro Kern, der die Ausführungseinheiten unterstützt. Der L2-Cache arbeitet dabei aber nur mit halber Taktfrequenz; erneut ein Abtritt an die Optimierung der Architektur hinsichtlich des Energieverbrauchs und nicht der Performance.