Hi Leutz,
Ich wollte euch mal von meinen Erfahrungen mit paralleler Programmierung (mittels Multithreading auf einer Mehrkern-CPU) berichten, insbesondere von deren Tücken, die ganz unvorhergesehenermaßen auftreten können.
Einst, vor vielen Jahren, noch zu Single-Core-Zeiten, habe ich die eine oder andere wissenschaftliche Simulation programmiert. Als ich dann 2007 meine erste Dual-Core-CPU, einen Athlon64 X2, hatte, dachte ich mir, ich könnte es mal angehen, meine Programme auf Multithreading umzustellen, um mehr Performance rauszuholen. Damals klappte das allerdings noch nicht so recht, ich bekam zwar mehrere Threads zum laufen, aber eine Performance-Steigerung stellte sich nicht ein. Ich berichtete seinerzeit in diesem Thread auf www.3dcenter.de davon:
http://www.forum-3dcenter.org/vbulletin/showthread.php?t=378301
(ich nannte mich dort Arokh). Meine Vermutung ist, dass das daran lag, dass beim X2 jeder Kern einen separaten L2-Cache hat, was dann, wenn beide Kerne an derselben Datenstruktur werkeln, nachteilig ist.
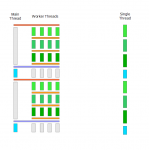
Mittlerweile habe ich jedoch einen Intel Core 2 Duo, und so dachte ich mir kürzlich, ich könnte es doch darauf noch einmal versuchen (der Core 2 Duo hat einen shared L2-Cache für beide Kerne, das sollte die bessere Voraussetzung bieten). Gesagt, getan, und in der Tat konnte ich mit 2 Threads einen Performance-Zuwachs von knapp 50% erzielen. Dass es nicht mehr geworden ist, liegt vermutlich einmal daran, dass die Ergebnisse im Hauptthread grafisch ausgegeben werden, und andererseits an der ziemlich aufwendigen Synchronisation zwischen den Threads. Ich habe hier mal das Prinzip, wie die parallele Verarbeitung abläuft (bzw. theoretisch ablaufen soll), als Diagramm skizziert:

Zunächst sendet der Hauptthread ein Start-Signal an die Worker-Threads, dass sie loslegen können (dunkel orange). Die Worker-Threads beginnen dann mit der Verarbeitung (grüne Abschnitte) und synchronisieren sich dabei zwischendurch immer wieder (hell orange). Der Hauptthread wartet solange (grauer Abschnitt). Wenn die Worker-Threads mit einem Durchlauf fertig sind, senden sie ein Ready-Signal an den Hauptthread (lila), der daraufhin die Rechenergebnisse grafisch ausgibt (türkiser Abschnitt), während die Worker-Thread warten (graue Abschnitte). Anschließend sendet er für den nächsten Durchlauf wieder das Signal an die Worker-Threads, usw.
Soweit die Theorie. Jedoch musste ich feststellen, dass mein Programm immer wieder sporadisch hängenblieb (die Ausgabe fror ein, und die im Taskmanager angezeigte CPU-Last ging auf 0 herunter). Ich vermutete die Ursache zunächst in der Synchronisation zwischen den Worker-Threads, dass es da irgendwo zu einem Deadlock kommen würde. Nach eingehender Analyse des Phänomens gelangte ich aber schließlich zu der Erkenntnis, dass das Problem an einer ganz anderen Stelle lag, nämlich am Zusammenspiel mit dem Hauptthread!
Es zeigte sich nämlich, dass es ab und zu mal vorkam, dass in dem Augenblick, in dem der Haupthread das Start-Signal sendete (dunkel orange im Diagramm), gar nicht alle Worker-Threads bereit waren, das Signal entgegenzunehmen. Konsequenz: der Hauptthread hatte das Signal abgeschickt und wartete darauf, dass die Worker-Threads fertig wurden, aber einer der Worker-Threads hatte das Signal nicht empfangen und wartete noch auf dieses. Ein typischer Deadlock! Um dem vorzubeugen, habe ich dann die Routine zum Absenden des Start-Signals modifiziert, und zwar so, dass der Hauptthread die wartenden Worker-Threads zählte, bevor er das Signal losschickte, und in dem Fall, dass noch nicht alle Worker-Threads im Wartezustand waren, eine kurze Pause machte und es dann erneut versuchte.
Die sporadischen Freezes traten aber immer noch auf! Abermals fiel mein Verdacht auf die Synchronisation zwischen den Worker-Threads. Aber an der lag es auch diesmal nicht. Vielmehr stellte sich heraus, dass das, was passieren konnte, wenn der Hauptthread den Worker-Threads signalisierte, weiterzumachen, auch im umgekehrten Fall eintreten konnte, wenn die Worker-Threads dem Hauptthread signalisierten, dass sie fertig waren (lila im Diagramm). Es konnte nämlich sein, dass der Hauptthread aus irgendwelchen Gründen in diesem Augenblick noch gar nicht soweit war, auf das Ready-Signal von den Worker-Threads zu warten. Da muss man aber auch erstmal drauf kommen: theoretisch sollte ja der Haupthread sofort in den Wartezustand gehen, nachdem er das Start-Signal abgeschickt hat, aber in der Praxis ist das offenbar nicht immer sichergestellt.
Des Rätsels Lösung war also: der Hauptthread muss mit dem Senden des Start-Signals warten, bis alle Worker-Threads bereit sind, und die Worker-Threads müssen beim Senden des Ready-Signals warten, bis der Haupthread bereit ist.
Hier das ganze als Programmcode, in C++ mit boost als Multithreading-Bibliothek. Zunächst die ursprüngliche Lösung:
Und hier die finale Version:
Ich wollte euch mal von meinen Erfahrungen mit paralleler Programmierung (mittels Multithreading auf einer Mehrkern-CPU) berichten, insbesondere von deren Tücken, die ganz unvorhergesehenermaßen auftreten können.
Einst, vor vielen Jahren, noch zu Single-Core-Zeiten, habe ich die eine oder andere wissenschaftliche Simulation programmiert. Als ich dann 2007 meine erste Dual-Core-CPU, einen Athlon64 X2, hatte, dachte ich mir, ich könnte es mal angehen, meine Programme auf Multithreading umzustellen, um mehr Performance rauszuholen. Damals klappte das allerdings noch nicht so recht, ich bekam zwar mehrere Threads zum laufen, aber eine Performance-Steigerung stellte sich nicht ein. Ich berichtete seinerzeit in diesem Thread auf www.3dcenter.de davon:
http://www.forum-3dcenter.org/vbulletin/showthread.php?t=378301
(ich nannte mich dort Arokh). Meine Vermutung ist, dass das daran lag, dass beim X2 jeder Kern einen separaten L2-Cache hat, was dann, wenn beide Kerne an derselben Datenstruktur werkeln, nachteilig ist.
Mittlerweile habe ich jedoch einen Intel Core 2 Duo, und so dachte ich mir kürzlich, ich könnte es doch darauf noch einmal versuchen (der Core 2 Duo hat einen shared L2-Cache für beide Kerne, das sollte die bessere Voraussetzung bieten). Gesagt, getan, und in der Tat konnte ich mit 2 Threads einen Performance-Zuwachs von knapp 50% erzielen. Dass es nicht mehr geworden ist, liegt vermutlich einmal daran, dass die Ergebnisse im Hauptthread grafisch ausgegeben werden, und andererseits an der ziemlich aufwendigen Synchronisation zwischen den Threads. Ich habe hier mal das Prinzip, wie die parallele Verarbeitung abläuft (bzw. theoretisch ablaufen soll), als Diagramm skizziert:
Zunächst sendet der Hauptthread ein Start-Signal an die Worker-Threads, dass sie loslegen können (dunkel orange). Die Worker-Threads beginnen dann mit der Verarbeitung (grüne Abschnitte) und synchronisieren sich dabei zwischendurch immer wieder (hell orange). Der Hauptthread wartet solange (grauer Abschnitt). Wenn die Worker-Threads mit einem Durchlauf fertig sind, senden sie ein Ready-Signal an den Hauptthread (lila), der daraufhin die Rechenergebnisse grafisch ausgibt (türkiser Abschnitt), während die Worker-Thread warten (graue Abschnitte). Anschließend sendet er für den nächsten Durchlauf wieder das Signal an die Worker-Threads, usw.
Soweit die Theorie. Jedoch musste ich feststellen, dass mein Programm immer wieder sporadisch hängenblieb (die Ausgabe fror ein, und die im Taskmanager angezeigte CPU-Last ging auf 0 herunter). Ich vermutete die Ursache zunächst in der Synchronisation zwischen den Worker-Threads, dass es da irgendwo zu einem Deadlock kommen würde. Nach eingehender Analyse des Phänomens gelangte ich aber schließlich zu der Erkenntnis, dass das Problem an einer ganz anderen Stelle lag, nämlich am Zusammenspiel mit dem Hauptthread!
Es zeigte sich nämlich, dass es ab und zu mal vorkam, dass in dem Augenblick, in dem der Haupthread das Start-Signal sendete (dunkel orange im Diagramm), gar nicht alle Worker-Threads bereit waren, das Signal entgegenzunehmen. Konsequenz: der Hauptthread hatte das Signal abgeschickt und wartete darauf, dass die Worker-Threads fertig wurden, aber einer der Worker-Threads hatte das Signal nicht empfangen und wartete noch auf dieses. Ein typischer Deadlock! Um dem vorzubeugen, habe ich dann die Routine zum Absenden des Start-Signals modifiziert, und zwar so, dass der Hauptthread die wartenden Worker-Threads zählte, bevor er das Signal losschickte, und in dem Fall, dass noch nicht alle Worker-Threads im Wartezustand waren, eine kurze Pause machte und es dann erneut versuchte.
Die sporadischen Freezes traten aber immer noch auf! Abermals fiel mein Verdacht auf die Synchronisation zwischen den Worker-Threads. Aber an der lag es auch diesmal nicht. Vielmehr stellte sich heraus, dass das, was passieren konnte, wenn der Hauptthread den Worker-Threads signalisierte, weiterzumachen, auch im umgekehrten Fall eintreten konnte, wenn die Worker-Threads dem Hauptthread signalisierten, dass sie fertig waren (lila im Diagramm). Es konnte nämlich sein, dass der Hauptthread aus irgendwelchen Gründen in diesem Augenblick noch gar nicht soweit war, auf das Ready-Signal von den Worker-Threads zu warten. Da muss man aber auch erstmal drauf kommen: theoretisch sollte ja der Haupthread sofort in den Wartezustand gehen, nachdem er das Start-Signal abgeschickt hat, aber in der Praxis ist das offenbar nicht immer sichergestellt.
Des Rätsels Lösung war also: der Hauptthread muss mit dem Senden des Start-Signals warten, bis alle Worker-Threads bereit sind, und die Worker-Threads müssen beim Senden des Ready-Signals warten, bis der Haupthread bereit ist.
Hier das ganze als Programmcode, in C++ mit boost als Multithreading-Bibliothek. Zunächst die ursprüngliche Lösung:
Code:
boost::condition_variable condStart, condReady, condSync;
boost::mutex mut;
int readyCounter = 0;
int waitingCounter = 0;
// Haupthread sendet Start-Signal
void notifyStart()
{
condStart.notify_all();
}
// Worker-Threads warten auf Start-Signal
void awaitStart()
{
boost::unique_lock<boost::mutex> lock(mut);
condStart.wait(lock);
}
// Synchronisation zwischen den Worker-Threads
void synchronize()
{
boost::unique_lock<boost::mutex> lock(mut);
waitingCounter++;
if (waitingCounter < NUM_THREADS)
{
condSync.wait(lock); // auf die übrigen Worker-Threads warten
}
else
{
waitingCounter = 0;
condSync.notify_all(); // alle Worker-Threads warten → weitermachen
}
}
// Worker-Threads senden Ready-Signal an Haupthread
void notifyReady()
{
boost::unique_lock<boost::mutex> lock(mut);
readyCounter++;
if (readyCounter >= NUM_THREADS)
{
// alle Worker-Threads sind fertig → Signal schicken
readyCounter = 0;
condReady.notify_one();
}
}
// Haupthread wartet auf Ready-Signal
void awaitReady()
{
boost::unique_lock<boost::mutex> lock(mut);
condReady.wait(lock);
}Und hier die finale Version:
Code:
boost::condition_variable condStart, condReady, condSync;
boost::mutex mut;
int readyCounter = 0;
int waitingCounter = 0;
// Senden/Empfangen des Start-Signals
void synchronizeStart()
{
boost::unique_lock<boost::mutex> lock(mut);
waitingCounter++;
if (waitingCounter < NUM_THREADS + 1)
{
// auf die übrigen Threads (Worker und Haupthread) warten
condStart.wait(lock);
}
else
{
// alle Threads warten → Start-Signal senden
waitingCounter = 0;
condStart.notify_all();
}
}
// Senden/Empfangen des Ready-Signals
void synchronizeReady()
{
boost::unique_lock<boost::mutex> lock(mut);
readyCounter++;
if (readyCounter < NUM_THREADS + 1)
{
// auf die übrigen Threads (Worker und Haupthread) warten
condReady.wait(lock);
}
else
{
// alle Threads warten → Ready-Signal senden
readyCounter = 0;
condReady.notify_all();
}
}
// Haupthread sendet Start-Signal
void notifyStart()
{
synchronizeStart();
}
// Worker-Threads warten auf Start-Signal
void awaitStart()
{
synchronizeStart();
}
// Synchronisation zwischen den Worker-Threads
void synchronize()
{
boost::unique_lock<boost::mutex> lock(mut);
waitingCounter++;
if (waitingCounter < NUM_THREADS)
{
condSync.wait(lock); // auf die übrigen Worker-Threads warten
}
else
{
waitingCounter = 0;
condSync.notify_all(); // alle Worker-Threads warten → weitermachen
}
}
// Worker-Threads senden Ready-Signal an Haupthread
void notifyReady()
{
synchronizeReady();
}
// Haupthread wartet auf Ready-Signal
void awaitReady()
{
synchronizeReady();
}
Zuletzt bearbeitet: