Asus V8440 TD und V8460 ultra TD im Test: Zwei „Ti“-tanen unter sich
5/21LMA-II
Die LMA-II besteht aus sechs Einzelkomponenten, von denen jede für sich dazu beitragen kann, exzessive Bandbreitennutzung durch Texturoperationen zu minimieren. Zu Zeiten des GeForce3 waren es demgegenüber nur vier Elemente, die sich in „verbesserter“ Form auch in der LMA-II wiederfinden. Im Einzelnen wären dies der Cross-Bar Memory Controller, Z-Occlusion Culling und Lossless Z-Compression. Neu hinzugekommen sind eine QuadCache genannte Cache-Ansammlung, ein Auto PreCharge für das lokale GrafikRAM sowie ein Fast Z-Clear. Nachfolgend ein paar Worte zu jeder Komponente.
Cross-Bar Memory Controller (CBCM):
Bei nahezu jeder herkömmlichen Grafikkarte (sogar inklusive der Radeon8500) arbeitet ein Memory-Controller, der die diversen notwendigen Speicherzugriffe, üblicherweise mit 128Bit (DDR), durchführt. An und für sich ist das eine gute Sache aber es gibt hier einen Haken. Jedesmal, wenn ein Zugriff durchgeführt wird, beim dem weniger als 128Bit (DDR) übertragen werden müssen, wird die überschüssige Kapazität des Controllers einfach verschenkt.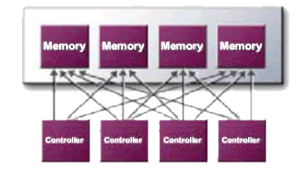
Beim nV25 (und auch beim nV20) kommt dagegen ein vierfacher Speichercontroller zum Einsatz, der jeweils unabhängig mit 32Bit (DDR) arbeitet. Diese, bei Bedarf auch zusammenschaltbaren Einheiten mit dann ebenfalls 128Bit (DDR), ermöglichen eine wesentlich effizientere Nutzung der zur Verfügung stehenden Speicherbandbreite, da oftmals nicht die vollen 128Bit (DDR) während eines Zugriffes benötigt werden. Im Idealfall (Zugriffe mit weniger als 33Bit (DDR) können so bis zu 75% Bandbreite eingespart werden, die dann für andere Aufgaben zu Verfügung stehen.
QuadCache:
Für Primitive (grundlegende geometrische Elemente), Vertex-Daten, Texturen und bereits in Bearbeitung befindliche Pixel kommt jeweils ein eigener in Größe und Aufbau optimierter Cache zum Einsatz. Dieser hält häufig benötigte Daten vor, die ansonsten umständlich aus dem Grafikspeicher geladen werden müssten. Der Effekt ist vergleichbar den First- und Second-Level Caches, ohne die sich selbst ein moderner Prozessor jenseits der 1,5GHz auf das Leistungsniveau eines Pentium133 ausbremsen ließe.
Laut nVidia sind diese Caches optimal an das jeweilige Anforderungsprofil angepasst, was auch nötig ist, da sie ja im Chip integriert sind und dort jeder unnötige Transistor bares Geld wert ist.
Z-Occlusion Culling:
Wie kann man im Vorfeld erkennen, dass bestimmte Bildpunkte, oder idealerweise ganze Bereiche, später nicht zu sehen sind? Die Lösung hierfür ist eigentlich recht naheliegend. Da man auf dem Bildschirm kein heilloses Durcheinander von sich gegenseitig überlagernden Objekten zu sehen bekommt, muss es ja schon irgendeinen Wert geben, der bestimmt, wie weit ein bestimmtes Objekt im Sichtfeld vom Betrachter entfernt ist. Diesen Wert, die Tiefeninformation, nennt man Z-Wert und er wird, naheliegenderweise, im Z-Buffer aufbewahrt. Wenn man nun vor dem Rendering prüft, ob ein bestimmtes Pixel evtl. schon von einem anderen verdeckt wird, kann man sich natürlich die weitere Berechnung sparen, was wiederum der verfügbaren Bandbreite stark zugute kommt.
Ein Unterpunkt ist die Anwendung dieses Verfahrens auf eine komplette Region des Bildschirminhaltes, die sogenannnte Occlusion Query. Dies muss aber zur Zeit noch per Software-Anforderung erfolgen, d.h. Das jeweilige Programm muss den Grafikchip dazu auffordern, eine Region zu prüfen. Prinzipiell ist diese Methode natürlich noch deutlich effizienter, erfordert jedoch den Einsatz hierfür ausgelegter Software.
Lossless Z-Compression:
Hierunter versteht nVidia eine Komprimierung für die zu schreibenden Tiefeninformationen (Z-Buffer), wobei die Kompressionsrate bei 4:1 liegen soll, wie schon beim GeForce3. Nähere Informationen zu diesem Feature liegen uns leider noch nicht vor, so dass man erst einmal kritisch nVidias Behauptung, der Datenverkehr vom und zum Z-Buffer könne hierdurch um den Faktor 4 reduziert werden, im Hinterkopf behalten sollte.
Auto PreCharge:
Dieses Feature dient dazu, das RAM nach einem Zugriff auf einen Bereich des RAM und vor den Zugriff auf einen anderen Bereich möglichst schnell wieder bereit zum Aufnehmen neuer Daten zu machen. Auch der im PC verbaute Hauptspeicher muss z.B. eine gewisse Zahl an Taktzyklen warten, bis neue Daten gesendet werden können. Je höher die Taktfrequenz des RAM, desto höher fällt im Allgemeinen auch die Anzahl dieser Zyklen aus. nVidia spricht hier von bis zu 10 Taktzyklen, die nötig sein können, bis ein Speicherbereich geschlossen und der nächste geöffnet und bereit zur Datenübertragung ist. Auto PreCharge soll nun per im Chip berechneter Vorhersage Bereiche aktivieren, die in nächster Zeit (im Microsekundenbereich) möglicherweise zum Ziel eines Datentransfers werden. Diese werden dann auf Verdacht "pre charged" und so kann die Wartezeit auf die "normale" Latenz von 2-3 Zyklen reduziert werden.
Fast Z-Clear:
Den Z-Buffer haben wir ja vorhin bereits angesprochen. Damit kein Chaos auf dem Bildschirm entsteht, müssen die Werte darin natürlich exakt sein. Restbestände von einem Pixel aus dem letzten fertig gerenderten Frame können das Ergebnis verfälschen und Pixelfehler wären die Folge. Deswegen muss vor jedem neuen zu berechnenden Bild jeder wert im Z-Buffer auf Null gesetzt werden. Das kostet im Prinzip genausoviel Bandbreite, wie jeder andere Zugriff. Für ein einziges Bild in 1024x768 in 32Bit würden alleine für diesen Z-Buffer Reset 3,1MB an Bandbreite verloren gehen (multipliziert mit der Anzahl der Bildrate, bei angenommenen 30 Bildern/s also schon 95MB/s) , die man genausogut sinnvoll verwenden könnte.
Nun werden hier die Z-Buffer nicht einzeln mit Null überschrieben, sondern in einem Rutsch auf den Ursprungswert gesetzt, prinzipiell einem Druck auf den Reset-Knopf nicht unähnlich, nur das ausschließlich der Bereich des Grafikspeichers gelöscht wird, in dem sich der Z-Buffer befindet.
Interessant ist in diesem Zusammenhang noch die Tatsache, dass es bei der GeForce3 noch ein weiteres Features gegeben hat, welches ebenfalls zur Reduzierung der Bandbreite diente, allerdings in diesem Falle zur Reduzierung der Geometriedaten.

Die Rede ist von den sogenannten Higher Order Surfaces. Vielen mögen sie schon einmal in Form von ATIs TruForm über den Weg gelaufen sein. Im wesentlichen ging es bei nVidias Weg der HOS darum, komplexe gewölbte Flächen nicht mehr mittels einer Unmenge von Dreiecken über den AGP-Bus zu jagen, sondern nur noch durch eine komplizierte mathematische Formel zu beschreiben. Nötige Veränderungen wurden dann per Variablenänderung an der Formel durchgeführt. Diese Feature ist leider zeitlebens ein Phantom geblieben. In der offiziellen Produktbeschreibung zur GeForce3 taucht es zwar auf, aber seit den Detonator-Treiber in Version 20.80 ist es nicht mehr verfügbar und nun scheint nVidia dies ganz aus der Feature Liste gestrichen zu haben obwohl es mittels gepatchter Treiber noch immer in Hardware verfügbar ist.
Accuview FSAA
Accuview widmet sich der Entferung der sogenannten Anti-Aliasing Artefakte. Diese Artefakte entstehen vornehmlich an den Kanten von Objekten und Polygonen dadurch, dass z.B. eine schräge Kante nur durch eine feine Treppenabstufung mit Hilfe der Pixel dargestellt werden kann. Wenn man die Anzahl der Pixel nun deutlich erhöht, wird unter normalen Umständen dieser Treppcheneffekt gemildert. Das wirklich störende Element dieser Artefakte entsteht vor allem durch Bewegung. Dabei kann es nämlich passieren, dass sich die Reihenfolge dieser Treppenstufen sehr häufig ändert, quasi ständig umspringt, ein Flimmereffekt ist die Folge, der auch bei sehr hohem Auflösungen wie z.B. 1600x1200 durch die Bewegung noch deutlich sichtbar bleibt.
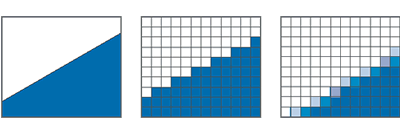
Es gibt nun verschiedene Methoden, diese Aliasing-Effekte zu bekämpfen, zusammengefasst unter dem Begriff Anti-Aliasing.
Die einfachste Art des AA ist, einfach jedes einzelne Bild in einen höher aufgelösten Framebuffer zu rendern, als die aktuell eingestellte Auflösung und das Ergebnis am Ende wieder auf die ursprüngliche Auflösung herunterzurechnen. So würde bei einer Auflösung von 800x600 virtuell bsw. ein 1600x1200 Pixel großer Framebuffer eingerichtet und hinterher wieder auf 800x600 herunterskaliert. Die Artefaktbildung würde sich so auf dem Niveau einer weitaus höheren Auflösung bewegen. Da jedoch mit dieser Supersampling genannten Methode quasi der gesamte Renderingvorgang in einer höheren Auflösung durchgeführt wird, inklusive aller Texturzugriffe etc. stellt sich ein extremer Leistungsverlust ein.
Da dieses Feature also de facto nicht nutzbar war, versuchte man bei nVidia mit Einführung eines im Consumerbereich neuen Verfahrens, bei noch ausreichender Leistung Anti-Aliasing nutzbar und auf breiter Front als Must-Have Feature durchzusetzen. Dieses wurde unter dem Namen „Quincunx“-Anti-Aliasing vermarktet und basierte auf dem Multisampling-Verfahren und einem nachgeschalteten Filter. Multisampling bedeutet, dass die Kanten mindestens genausogut geglättet werden, wie beim Supersampling, jedoch werden die Texturen bei diesem Verfahren nicht behandelt, so dass im direkten Vergleich zu Supersampling-“Texturen“ diejenigen des Multisampling-Bildes nicht ganz so scharf aussehen und ausserdem der Flimmereffekt bei entfernten Texturen nicht bereinigt wird.
Die GeForce3 bot bereits dedizierte Hardware zu diesem Zwecke, so dass die zusätzlichen „Samples“ bei voller (GPU-)Leistung berechnet werden konnten. Augenscheinlich zu diesem Zwecke wird seit der GeForce3 die Füllrate der Chips nicht mehr in Gigatexeln/s angegeben, sondern in Anti-Aliased-Samples pro Sekunde.
Accuview basiert ebenfalls auf dieser Technik, beinhaltet aber zusätzliche Möglichkeiten, die gleichzeitig eine gesteigerte Bildqualität und höhere Leistung versprechen.
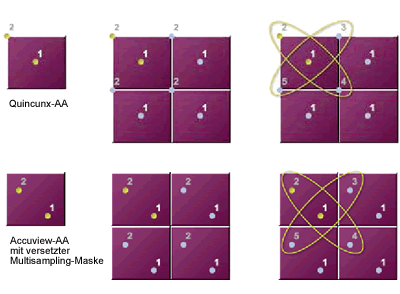
Das Quincunx-Muster, benannt nach der Anordnung der fünf Augen auf einem Würfel, bleibt erhalten, wird allerdings mitsamt der zusätzlich berechneten Samples um einen „halben“ Bildpunkt schräg versetzt. Diese Verschrägung kommt der Kantenglättung zugute, da die zusätzlich erzeugten Pixel nun in y- wie in x-Richtung um 50% näher an einer imaginären Schräge und damit der realen Position des Pixels wären und die Anti-Aliasing Wirkung durch die exaktere Näherung steigt. Besonders fällt dies an leicht geneigten, beinahe horizontalen Linien auf.
Desweiteren wurde bei der Ausführung des Accuview-Anti-Aliasing ein kompletter Zugriff auf den Framebuffer eingespart. Dies geschieht jedoch nicht, wie in der Gerüchteküche und unserem Preview spekuliert wurde, durch das Zusammenfügen der Multisamplebuffer zu einem Framebuffer erst im RAMDAC.
Sicher hingegen ist jedoch, daß es einen neuen FSAA-Modus geben wird, der "4xS" bezeichnet ist. Das "S" steht für staggered und soll für eine gesteigerte Wiedergabetreue in Texturen sorgen, indem 50% mehr Texturwerte ausgelesen werden und in die endgültige Berechnung miteinfließen. Wie mittlerweile zu erkennen war, wird hierbei 2x2 Multisampling mit 1x2 Supersampling kombiniert, so dass sich auch der begehrte Texturenglättungseffekt einstellt.
Weiterhin will man dieses Mal wohl auch die positive Wirkung von Anisotropischer Filterung betonen, sprich vermarkten. Darunter versteht man eine Filterung, die entgegen den herkömmlichen bilinearen und trilinearen Filtern nicht in alle Richtungen gleich stark wirkt, sondern analog des Blickwinkels, also z.B. bei 3D-Spielen meist in die Tiefe des Monitors hinein, abhängig vom eingestellten Grad der Filterung, deutlich mehr als nur die benachbarten 4 Pixel zur Filterung heranzieht.