AMD Radeon HD 7970 im Test: Neue Radeon-GPU weiß zu überzeugen
3/24Architektur-Änderungen
Im Mai 2007 präsentierte AMD die Radeon HD 2900 XT mit der VLIW5-Unified-Shaderarchitektur. Diese hatte zahlreiche Macken, sorgte nach einigen Modifikationen allerdings für sehenswerte Erfolge mit dem Höhepunkt in Form der Radeon HD 5870. Irgendwann ist jedoch jedes noch so gute Design „am Ende“ und benötigt einen Nachfolger mit tiefgreifenden Änderungen, um die Performance und die Features weiter verbessern zu können.
Mit der „Graphics-Core-Next“-Architektur (GCN), die erstmals auf der Tahiti-GPU und damit der Radeon HD 7970 eingeführt wird, ist es nun so weit. Dementsprechend wird die Southern-Island-Generation zudem einen Ausblick auf kommende Produkte geben: Denn das neue Design wird die Radeon-Grafikkarten noch viele Jahre begleiten.
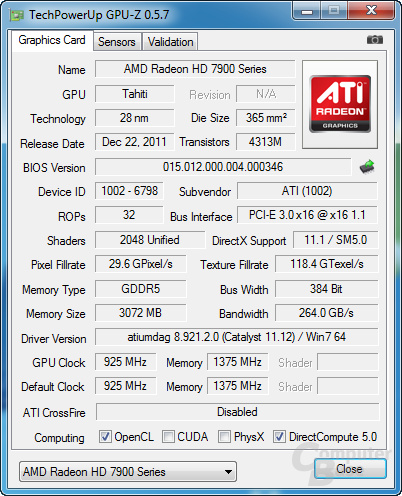
Laut Michael Mentor, Senior Fellow Design Engineer bei AMD, ist an GCN seit der R600-Fertigstellung vor 4–5 Jahren gearbeitet worden. Die Eckdaten lesen sich dabei durchaus beeindruckend, denn die Tahiti-GPU der Radeon HD 7970, die im neuen 28-nm-Prozess bei TSMC gefertigt wird, verfügt über 4,3 Milliarden Transistoren und weist eine Größe von 365 mm² auf.

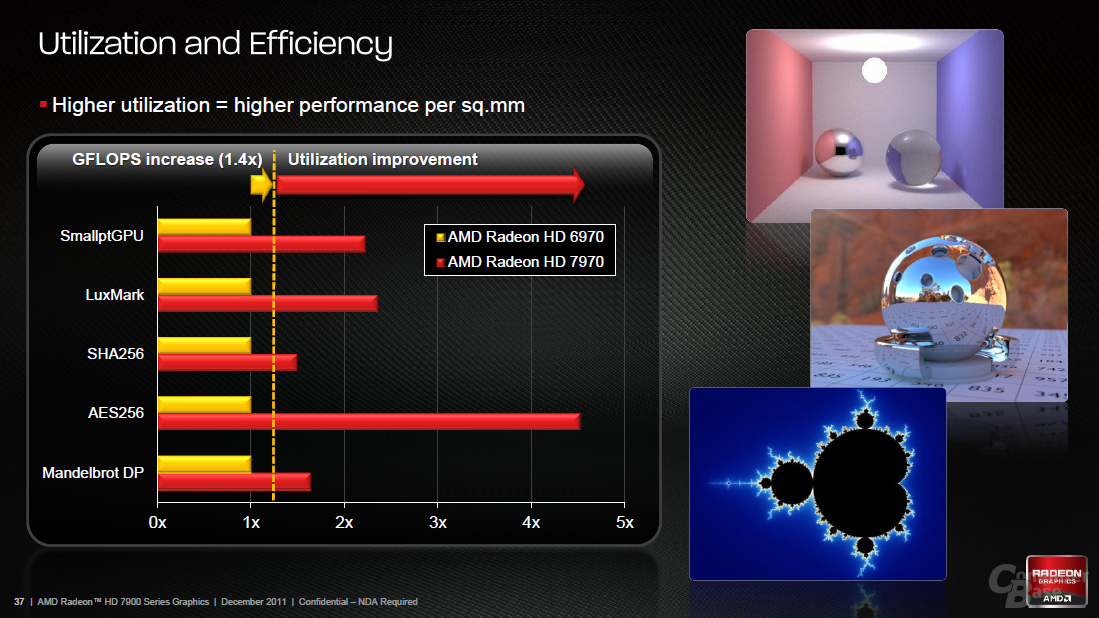
Vom VLIW-Design (mehrere sequentielle Befehle, die in einem Thread parallel ausgeführt werden) verabschiedet sich AMD und setzt auf teils skalare, teils Vektor-Einheiten: 2.048 Shadereinheiten sind es schlussendlich geworden, die deutlich effizienter als bei älteren AMD-Grafikkarten arbeiten sollen (eine bessere Effizienz/Auslastung war eines der wichtigsten Eckpunkte bei der GCN-Entwicklung). Darüber hinaus liegen die groben Tahiti-Eckdaten bei 128 Textureinheiten, 32 ROPs, ein 384 Bit breites Speicherinterface, PCIe 3.0, und DirectX 11.1. In den folgenden Abschnitten schauen wir uns das Design etwas genauer an.
Compute-Unit, Shadereinheiten
Da AMD bei Graphics Core Next primär die Shadereinheiten umgekrempelt hat, wollen wir diese zuerst analysieren. Das Hauptproblem der VLIW-5- und VLIW4-Einheiten (Einführung von VLIW5 auf der HD 2900 XT) war deren Auslastung, da jede einzelne ALU nicht so ohne weiteres mit Daten gefüttert werden konnte und so (beinahe) durchweg Leerlauf entstanden ist – die ALUs sind voneinander abhängig. Und genau dies soll GCN beheben.

Ein einzelner Shadercluster auf GCN, Compute Unit (CU) genannt, ist theoretisch exakt so leistungsstark wie eine SIMD-Einheit auf Cayman (HD 6970) und kann 64 MADDs (Multiply-ADD) pro Takt berechnen. Jedoch werden die einzelnen ALUs anders mit Daten versorgt. Jede CU setzt sich unter anderem aus vier Vektor-Einheiten zusammen, die wiederum vier einzelne SIMD-Einheiten mit 16 ALUs (64 ALUs pro CU) tragen. Jede SIMD kann eine „Betriebsart“ an Shadern (Pixel-, Vertex-, Geometry-, Computeshader) gleichzeitig berechnen, wodurch es nun eine Art „Betriebsart-Limitierung“ bei GCN gibt, die aber recht problemlos sein soll.
Die Änderung hat für den Compiler im Grafik-Treiber den Vorteil, dass dieser nicht mehr krampfhaft die Shaderprogramme aufteilen muss, um die Einheiten bestmöglich auszulasten. Das Scheduling der Daten vereinfacht sich massiv. Gleichzeitig wird die Fehlersuche für Software-Entwickler vereinfacht, da nun besser verfolgt werden kann, was genau die einzelnen ALUs berechnen. Die Performancevorhersage fällt aus demselben Grund leichter.


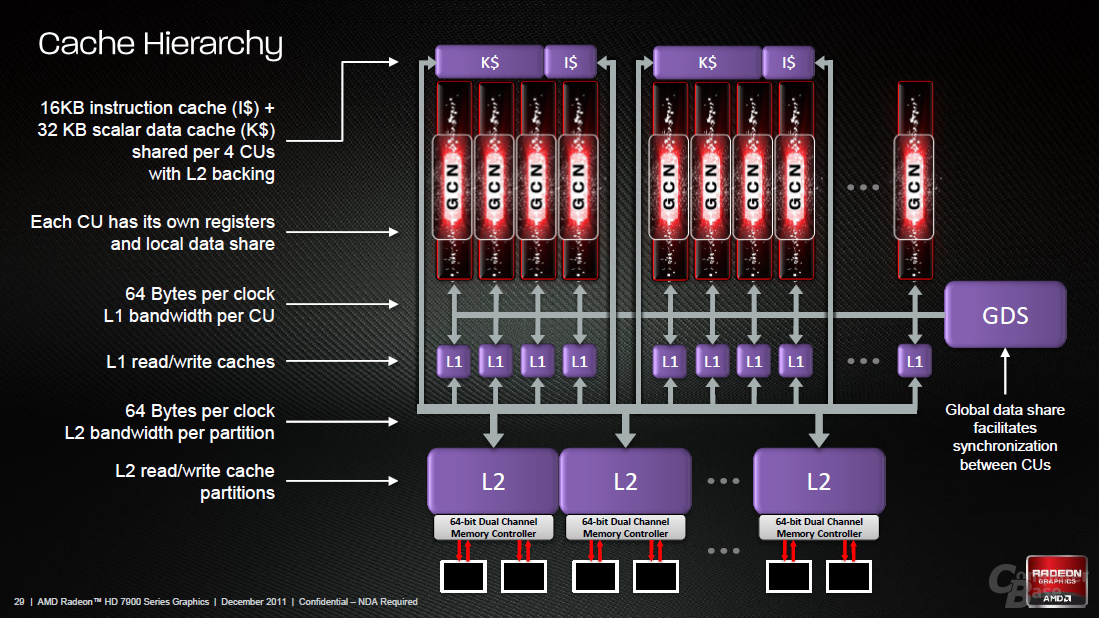
Eine CU besteht aber noch aus viel mehr als nur den vier SIMD-Einheiten. So hat jede CU ihren eigenen Scheduler, der die einzelnen Einheiten mit Daten versorgt. Eine skalare Co-Einheit sorgt dafür, dass die Vektoreinheiten nicht von entsprechenden Berechnungen ausgebremst werden. Es ist zusätzlich eine „Branch & Message Unit“ (Sprungeinheit für Programmverzweigungen) sowie ein Textur-Cluster vorhanden. Letzterer enthält vier vollwertige Texture Mapping Units (TMUs), die pro Takt einen Pixel adressieren sowie texturieren können und 16 Load/Store-Einheiten, die die Quell- und Zieladressen von 16 Threads in einem Takt berechnen und die Ergebnisse in den Cache schreiben können.
Apropos Cache: Eine CU weist einen 340 KB großen Cache auf. Jede Vektor-Einheit hat ihren eigenen, 64 KB großen Cache (Vector Registers), während die Skalar-Einheit auf einen 4 KB großen Cache (Scalar Registers) zugreifen kann. Ein 64 KB großer „Local Data Store“ kann von allen Einheiten für gemeinsam verwendete Daten genutzt werden. Der L1-Cache der TMUs ist 16 KB groß.
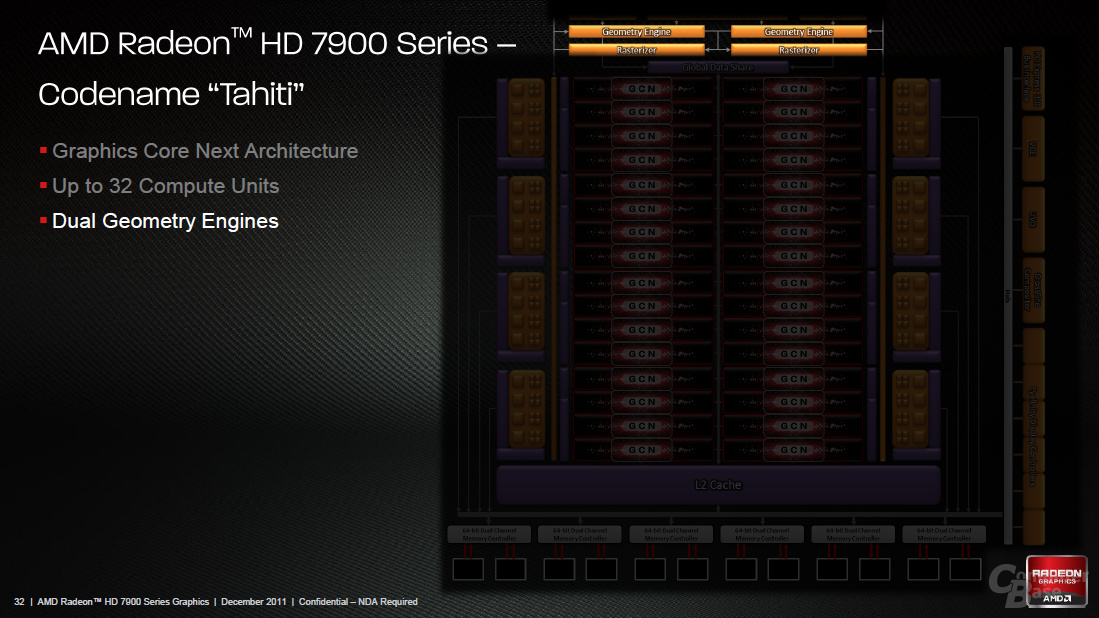
Die CU sind, wie bereits erwähnt, die Hauptunterschiede bei Graphics Core Next. Tahiti als Vollausbau und damit die Radeon HD 7970 setzt sich aus 32 CUs (2.048 Shadereinheiten zu 128 SIMDs), 128 TMUs, 512 Load-Store-Einheiten sowie knapp 8,2 MB Cache zusammen.
Front-End
Das Front-End skaliert, anders als bei Nvidias GF110-Architektur, nicht mit der Anzahl der CUs, sondern ist weiterhin „starr“ integriert. Der Command Processor teilt die kommenden Befehle auf zwei „Geometry-Einheiten“ mit je einem Geometry-Assembler, Vertex-Assembler und einer Tessellation-Einheit der neunten Generation auf, die (bei manchen Tessellation-Faktoren) bis zu vier Mal schneller als auf der Cayman-GPU arbeitet. Es sind weiterhin zwei Rasterizer in das Design integriert. Das Front-End, das mit den CUs zur Synchronisation auf ein und denselben „Global-Data-Share“-Cache zugreifen kann, wurde also nur geringfügig angepasst.

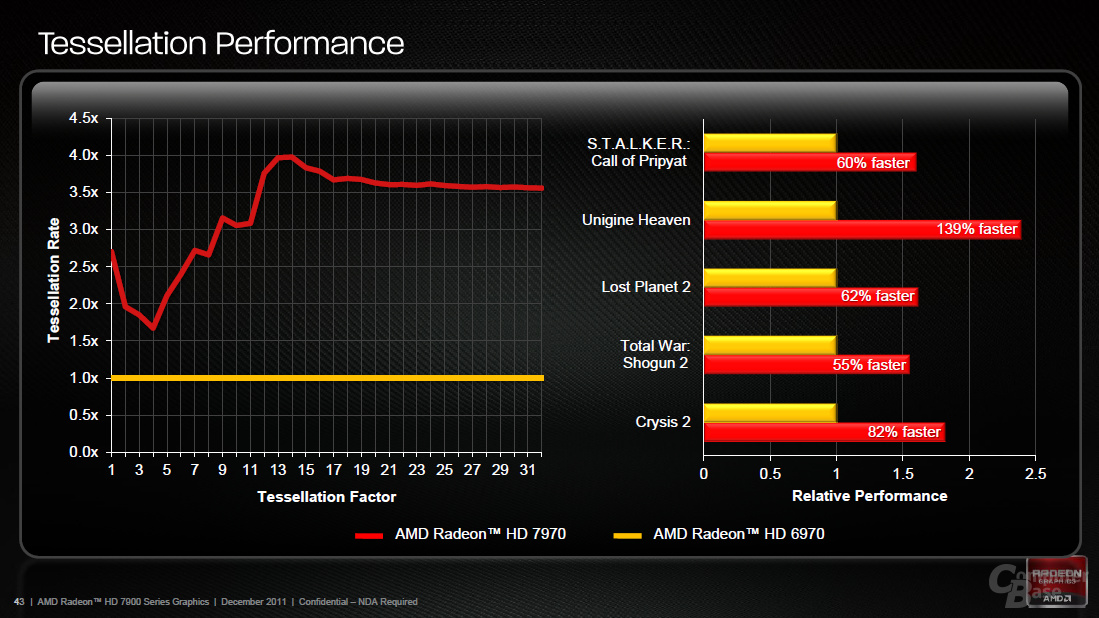
ROPs und Speicherinterface
Auf der Tahiti-GPU verbaut AMD acht ROP-Cluster, die genauso wie in der Cayman-GPU aufgebaut sind. Es sind in diesen also vier ROPs sowie 16 Z/Stencil-Units platziert, die sich um die Sichtbarkeitsprüfungen kümmern. Pro Takt berechnet Tahiti 32 Farb- und 128 Z/Stencil-Aufgaben – die Anzahl ist mit Cayman gleich geblieben. Jeder ROP-Cluster hat einen eigenen Cache und ist mittels einer Crossbar mit dem Speicherinterface verbunden. Zudem gibt es einen 768 KB großen L2-Cache, in den aber nicht nur die ROPs, sondern sämtliche Einheiten hinein schreiben und von diesem Lesen können.
Kommen wir nun zum Speicherinterface, was AMD ausgebaut hat. Dieses wurde um 50 Prozent vergrößert und weist nun einen 384 Bit breiten Bus auf, der sich aus sechs 64 Bit breiten Speichercontrollern zusammensetzt und damit identisch mit dem Pendant auf dem GF110 von Nvidia ist. Pro Controller sind weiterhin zwei GDDR5-Speicherbausteine notwendig, womit Tahiti „krumme“ Speichergrößen aufweist – standardmäßig sind es 3072 MB, es sind aber theoretisch genauso 1.536 MB und 6.144 MB möglich.

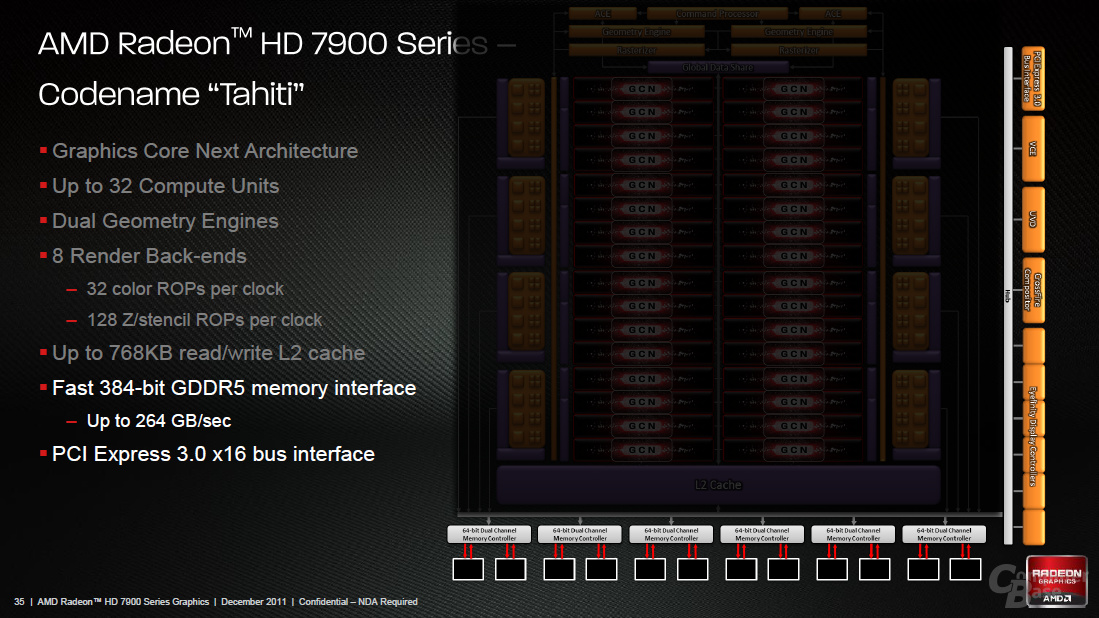
Dies sind die groben Eckpunkte der Graphics-Core-Next-Architektur, die primär auf eine bessere Auslastung aller vorhandenen Einheiten abzielt. Der Kundenkreis sind dabei aber nicht nur die Spieler, sondern genauso „professionelle Kunden“, die Software abseits von 3D-Grafik auf der GPU berechnen möchten. Für diese hat AMD ebenso zahlreiche Änderungen vorgenommen, sodass Tahiti 947 GFLOPS – also ein Viertel der SP-Leistung – bei doppelter Präzision (64 Bit, Double Precision) als theoretischen Wert erreicht. Darüber hinaus kann der Speicher vollständig mit der ECC-Fehlerüberprüfung arbeiten. Als APIs werden Direct Compute 11.1, OpenCL 1.2 sowie C++AMP unterstützt.