GeForce GTX 680 im Test: Mit Kepler ist Nvidia wieder die Nummer 1
3/30Architektur-Änderungen
Auf der GeForce GTX 680 verbaut Nvidia die GK104-GPU, die anders als gewohnt nicht die schnellste Ausbaustufe darstellt. Dies trifft erst auf den GK110 zu, der den neusten Gerüchten zu Folge allerdings noch einige Monate auf sich warten lässt – frühestens im dritten Quartal soll er aufschlagen, vielleicht aber auch später.
Der GK104 wird im neuen 28-nm-Prozess bei TSMC gefertigt und setzt sich aus 3,54 Milliarden Transistoren zusammen. Der Rechenkern, an dem die Kalifornier laut eigenen Angaben ab Mitte 2007 gearbeitet haben, weist eine Größe von 294 mm² auf.
Die Eckdaten des GK104 lesen sich größtenteils vielversprechend: So gibt es 1.536 Shadereinheiten, wobei Nvidia jedoch erstmals seit dem G80 auf den so genannten „Hot Clock“ verzichtet. 128 Textureinheiten, 32 ROPs, ein 256 Bit breites Speicherinterface, 2.048 MB GDDR5-Speicher, PCIe 3.0 sowie DirectX 11.1 runden die grobe Ausstattung ab. Schauen wir uns nun die Änderungen etwas genauer an.
Nvidias Kepler-Architektur ist beileibe keine Neuentwicklung, denn dazu haben die Chipentwickler zu viel aus der Fermi-Generation übernommen. Primär hat es Änderungen an den ALUs gegeben, wobei es diese in sich haben: Nvidia betreibt bei Kepler sämtliche ALUs nur noch mit der Frequenz der restlichen GPU (die „Base-Clock“ liegt bei 1.006 MHz), während die ALUs bei den Vorgängern noch doppelt so schnell wie die restlichen Bauteile liefen (der sogenannte Hot Clock).
Was sich zunächst unbedeutend anhört, bedeutete für das Designteam viel Arbeit. Nvidia ist den Schritt zu einer einheitlichen Frequenz aus zwei verschiedenen Gründen gegangen: Mit dem Hot Clock war es zwar möglich, mit nur wenigen, dafür aber sehr hoch taktenden ALUs auszukommen, in der Entwicklung ist dies jedoch sehr aufwendig. Darüber hinaus benötigen die Shadereinheiten mehr Platz auf der Die-Fläche als mit einer traditionellen Taktung und in einem Atemzug ist der Energieverbrauch höher – zu viele Nachteile gegenüber den Vorteilen.
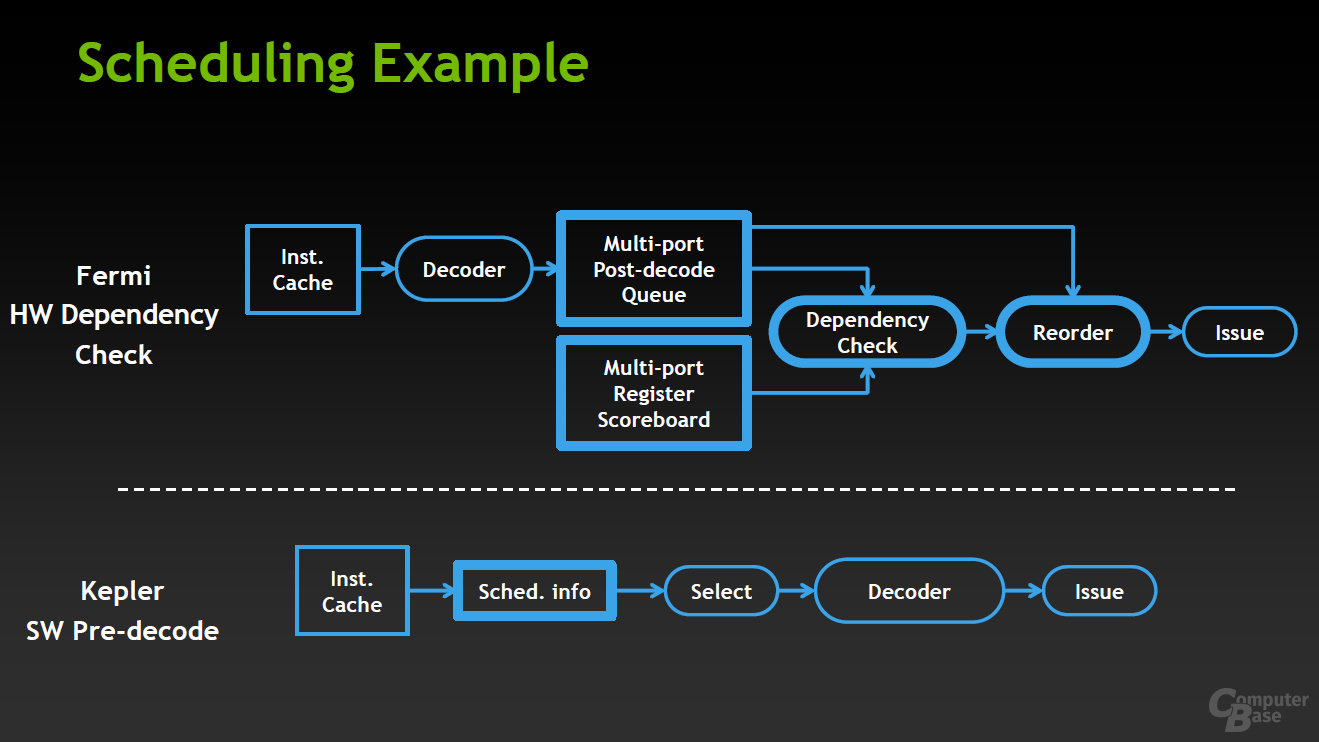
Nvidia erstellt dafür ein (imaginäres) Rechenbeispiel: So soll das Kepler-Design bei einer um zehn Prozent geringeren Leistungsaufnahme 80 Prozent mehr Die-Fläche für die ALUs nutzen können. Bei derselben Die-Fläche soll Kepler um 50 Prozent sparsamer mit der Leistungsaufnahme umgehen als die Fermi-Architektur. Nvidia gibt dabei aber strikt an, dass es sich nur um ein Rechenbeispiel handelt und sich nicht auf ein Produkt bezieht. Zeitgleich hat Nvidia das Scheduling der Rechenbefehle vereinfacht und stärker auf die Software ausgelagert, während bei Fermi noch das genaue Gegenteil der Fall ist. Hierdurch sind für deutlich mehr Befehle die Rechenwege beziehungsweise die Verteilung der Aufgaben schon vorher festgelegt, während bei Fermi die Hardware mehr Einfluss darauf hatte, welche Daten wohin verteilt werden. Durch diese Änderung soll die Effizienz deutlich steigen.


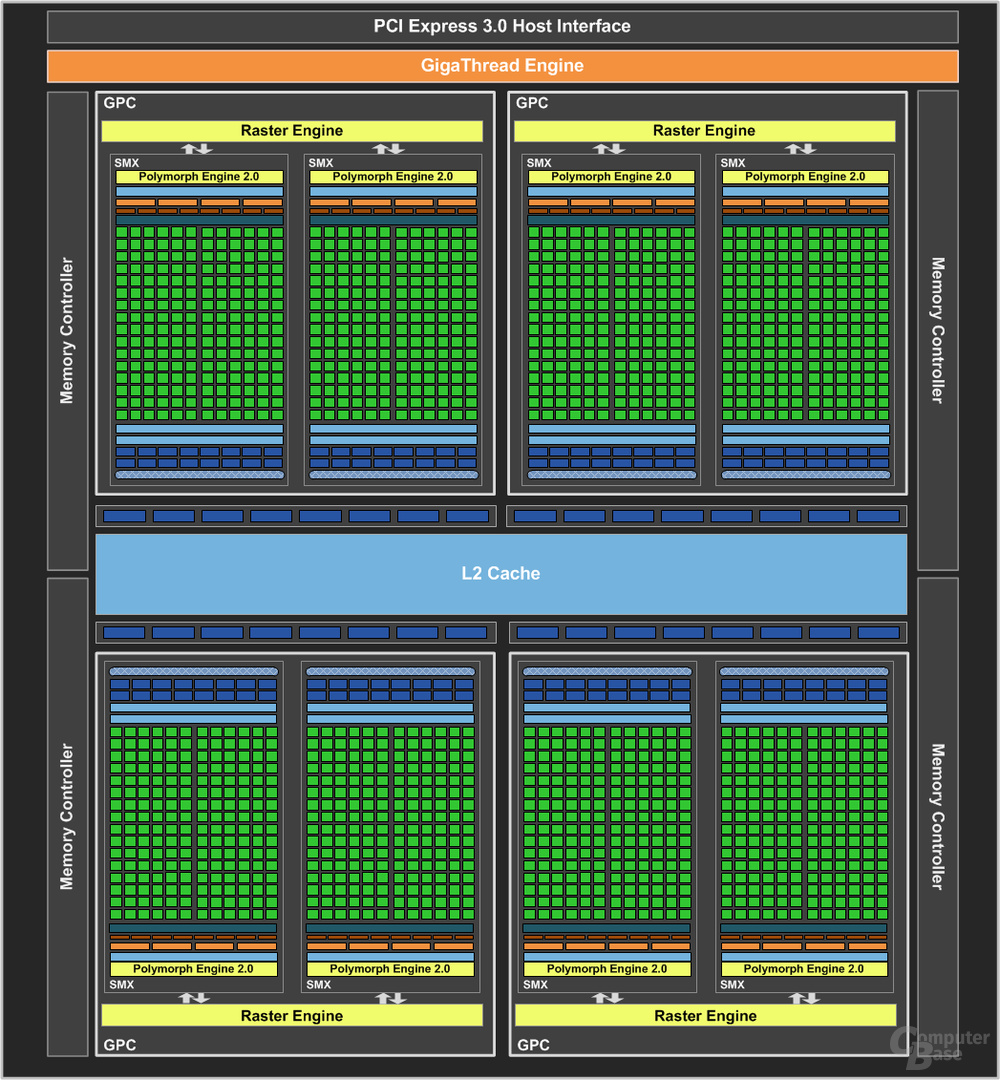
Und das war es eigentlich schon mit den größten Änderungen. Wie Fermi setzt sich Kepler aus vier Graphics Processing Clusters (GPCs) zusammen, die die meisten Ausführungseinheiten beherbergen. So findet sich dort unter anderem die kaum veränderte Raster-Engine ein, die das (sehr starke und skalierbare) Front-End darstellt. Anders als beim Vorgänger ist die Raster-Engine nun in der Lage, sämtliche ROPs pro Takt mit einem Pixel zu versorgen, was auf Fermi nicht möglich gewesen ist.
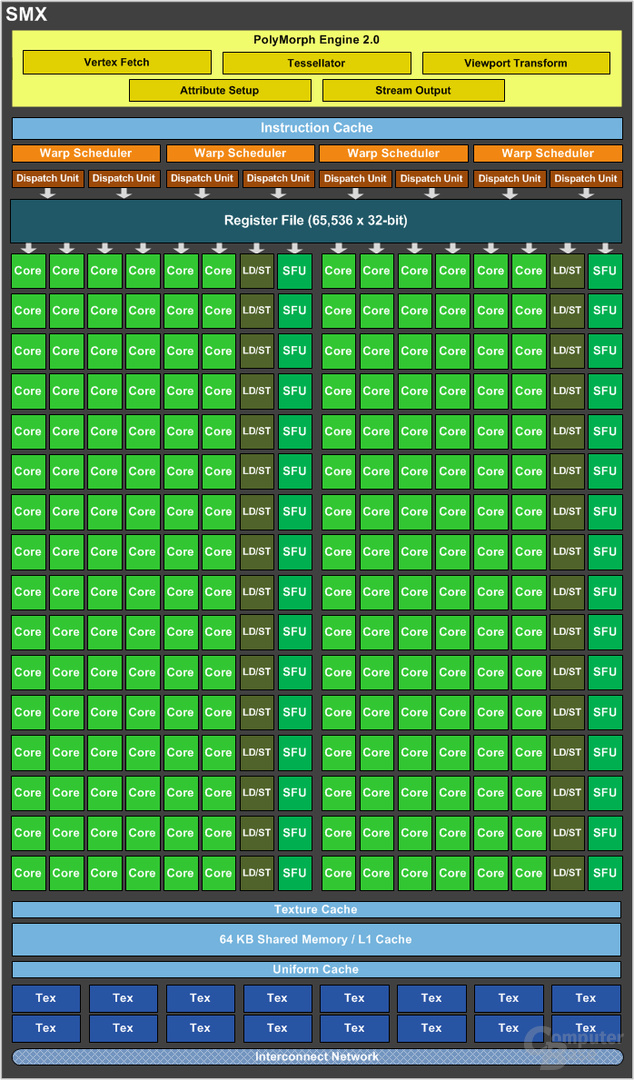
Jeder GPC besteht aus zwei SMX-Blöcken, die die Streaming Multiprocessors (SM) ablösen. Jeder SMX baut sich aus 192 skalaren Shadereinheiten zusammen, die pro Takt ein MADD (Multiply-ADD) berechnen können. Dadurch kommt der GK104 auf 1.536 ALUs, deren Aufbau an sich inklusive der Load-and-Store-Einheiten sowie Special-Function-Units identisch geblieben sind. Zur Double-Precision-Leistung wollte sich Nvidia nicht äußern, da dort erst der GK110 „zuschlagen“ soll. Laut unseren Messungen beträgt diese rund 1/16 der Single-Precision-Performance, während der GF100 1/8 der Leistung bietet.
Ein SMX kann zudem auf 16 vollwertige Textureinheiten zurückgreifen, die pro Takt ein Pixel adressieren sowie texturieren können – das macht insgesamt 128 TMUs auf dem GK104. Erwähnenswert ist die Polymorph-Engine, die für die Tessellation-Leistung zuständig ist. Pro SMX gibt es eine Polymorph-Engine, weswegen die Anzahl dieser gegenüber Fermi halbiert ist (Fermi hat doppelt so viele SM wie Kepler SMX). Als Ausgleich hat Nvidia den Primitiven- sowie Tessellation-Durchsatz verdoppelt, weswegen die Performance identisch zwischen dem Vollausbau vom GK104 und GF100 sein sollte. Darum tragen die Polymorph-Engines nun den Namenszusatz „2.0“. Am sonstigen Aufbau inklusive des 64 KB großen Shared-Memory-/L1-Cache hat sich nichts getan.
GK104 verfügt über vier ROP-Cluster mit je acht Raster Operation Processors, von denen es also 32 gibt. Das Speicherinterface setzt sich aus vier einzelnen 64-Bit-Controllern zusammen, was ein 256 Bit breites Speicherinterface zur Folge hat. Die einzelnen Controllern hat Nvidia derart überarbeitet, dass diese nun auch mit hochgetaktetem GDDR5-Speicher (3.004 MHz auf der GTX 680) umgehen können. Die Speichergröße beträgt 2.048 MB, wobei theoretisch auch ein doppelt so großer VRAM in Zukunft denkbar ist. Der L2-Cache, auf den alle SMX zugreifen können, ist 512 KB groß.

- Bester CPU-Hersteller
- Bester Mobile-SoC-Hersteller
- Bester SSD/HDD-Hersteller
- Alle Wahlen im Überblick...