Intel „Haswell“-Prozessor für Desktop-PCs im Test: Enttäuschend gut.
5/51Front End
Es gibt keinen modernen x86-Prozessor, der die komplexen CISC-Befehle variabler Länge direkt verarbeitet. So übersetzen sowohl AMD als auch Intel die eingehenden x86-Befehle in kleine, handliche Instruktionen, die das Prozessor-Back-End versteht. Diese Vorverarbeitung (Decodierung) erfolgt im Prozessor-Front-End, das die Mini-Instruktionen, so genannte Micro-Befehle (µOps), erzeugt. Die Hauptaufgabe und Herausforderung des „Front End“ ist es nun, stets genügend µOps an das „Back End“ zu liefern, damit dieses unentwegt beschäftigt ist. Erneut hat Intel hier Optimierungen angesetzt, denn je reibungsloser und besser der Datenstrom funktioniert, desto effektiver und schneller wird ein Prozessor.
In diesem Zusammenhang wurde auch die Sprungvorhersage (Branch Prediction) überarbeitet, denn dort bietet sich für die Architekten ein großer Spielraum für Optimierungen. Denn immer wenn ein Sprung (engl. Branch) falsch vorher gesagt wird, muss die gesamte Pipeline geleert werden. Dies reduziert nicht nur die Performance, auch bereits investierte Energie geht verloren.
Der L1-Instruktion-Cache (Icache) sowie der zugehörige Translation Lookaside Buffer (ITLB) können bei Haswell nun Misses (keine Daten im Cache vorhanden) spekulativ behandeln und parallel zu tatsächlich fehlenden Daten abarbeiten. Unterm Strich verspricht Intel dadurch verringerte Latenzen, sollten tatsächlich mal keine Daten vorhanden und der Miss unausweichlich sein. Die Größe des L1-Instruktion-Cache mit 32 KByte und der 128 Einträge fassende TLB wurden gegenüber Sandy Bridge ansonsten unangetastet gelassen.
Von Sandy Bridge erbt Haswell den seinerzeit eingeführten µOp-Cache. Er funktioniert quasi als 6 KByte großer L0-Cache, der in den 32 KByte großen L1-Instruktion-Cache eingebettet ist. Ein neuer Befehl wird direkt nach der Initialisierung und damit vor dem vollständigen Decodieren mit dem µOp-Cache verglichen, der bis zu 1.500 Micro-Befehle enthalten kann. Werden Übereinstimmungen gefunden – laut Intel soll dies in 80 Prozent der Fälle gelten –, wird die gesamte verbleibende Dekodierstufe abgeschaltet und der Befehl wandert direkt in die nächste Sektion. Für die restlichen 20 Prozent der Befehle heißt es, weiterhin den klassischen Weg vom L1-Instruktion-Cache über die Decoder-Einheit zu gehen.
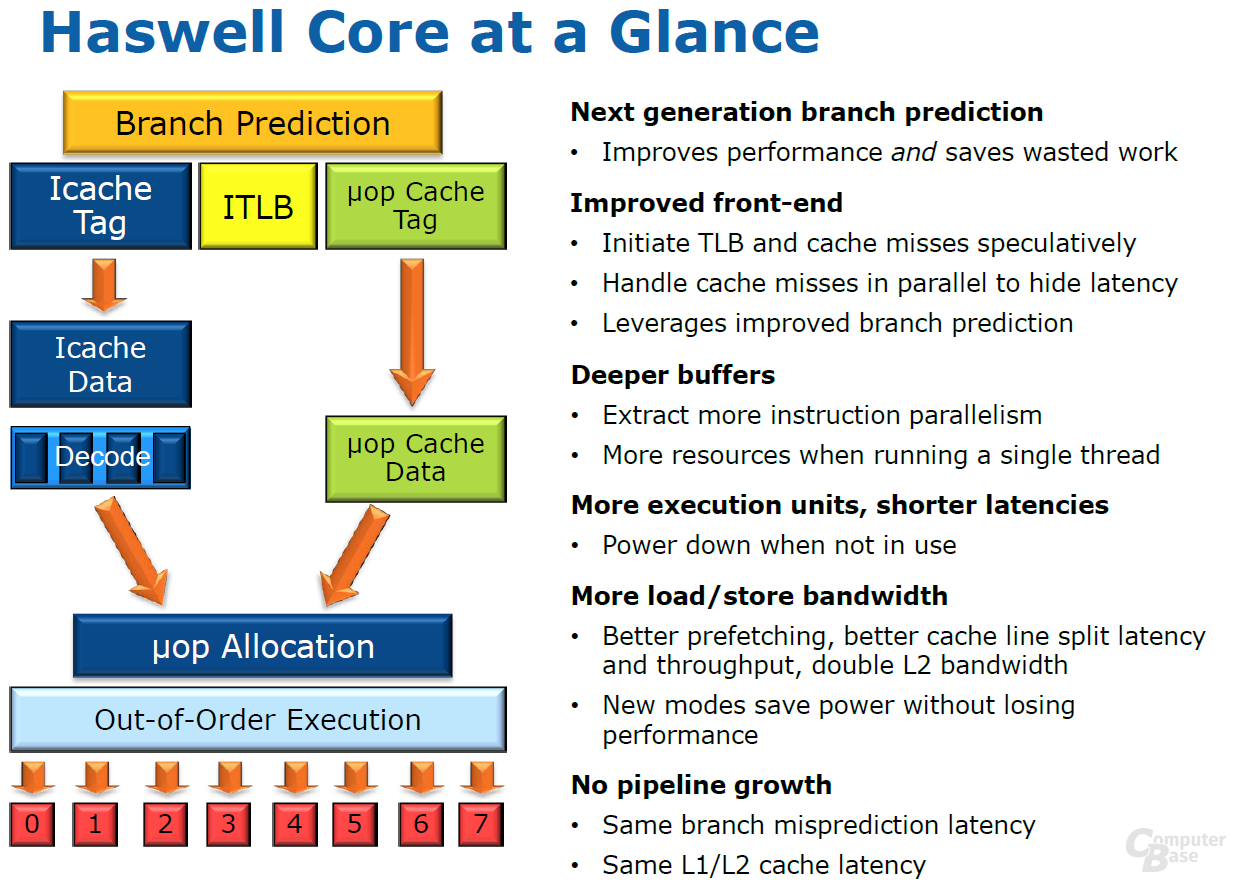
Bevor die µOps dann auf dem einen oder anderen Wege den größten Teil des Front Ends hinter sich gelassen haben, finden sie sich in der Warteschlange zur Ausführung (µOp Allocation) wieder. Hier hat Intel nochmals angesetzt und die Vorgehensweise von Sandy Bridge überarbeitet. Dort wurden pro Thread 28 µOps abgearbeitet, diese 28 µOps wurden jedoch auf den zweiten Thread repliziert. In Ivy Bridge hatte Intel dies bereits zu einem gemeinsamen Thread und 56 µOps zusammengefasst, was jetzt bei Haswell fortgesetzt wird. Auch hier verspricht sich Intel eineb fokussierteren Einsatz der zur Verfügung stehenden Ressourcen, was am Ende mehr Performance bedeuten soll.
Diese Überarbeitung ist nur ein kleiner Punkt, denn Intel hat nahezu alle Puffer deutlich aufgebohrt. Doch dazu auf der folgenden Seite mehr, wenn es in Richtung „Back End“ und der Ausführung der Instruktionen geht.